
- 8. Cpeh 集群配置
- 9. Ceph 集群操作
- 9.3 集群监控
- 9.4 数据平衡
- 9.5 CRUSH Maps
- 9.6 OSDs 和 PGs 状态
- 9.7 用户管理
- 9.8 pool 操作
- 9.9 CRUSH Map 基础
- 9.10 CRUSH Map 详解
- 9.11 Placement Group
- 9.12 缓存分层 (1)
- 9.13 纠删码池 (1)

8. Cpeh 集群配置
每个 Ceph 进程在启动时都会从多个源位置读取配置信息,包括本地配置、Monitor节点配置库、命令行、环境变量。配置选项有全局配置,应用于所有进程,或应用于特定的进程或客户端。Ceph 集群的守护进程中 ceph-osd和ceph-mon会存储数据到硬盘上。ceph 集群中大多数数据都由 ceph-osd 守护进程负责存储的,通常来说,每个 ceph-osd 进程对应单个存储设备(单个 SSD 或 HDD),此外 ceph-osd 也可以使用组合设备,例如数据存储在 HDD,元数据存储在 SSD。ceph-mon 进程管理集群状态信息,例如集群认证信息、成员信息、状态信息等。小型 ceph 集群,monitor 数据库通常需要数GB的数据容量,在大型 ceph 集群中,monitor 数据库可以达到数百GB的数据容量。
8.1 存储引擎
OSD 管理并存储数据的方式有两种,分别为 Bluestore 和 Filestore 。从Luminous 12.2.z 版本开始,默认存储后端引擎也是推荐的存储方式为 Bluestore。
Bluestore
- 数据直接在存储设备上 (例如裸设备或原始分区) 操作和管理,避免了抽象层 (例如文件系统) 带来的复杂性和性能损耗。
- Bouestore 使用嵌入式 RocksDB 数据库管理元数据 (2013年 Facebook 基于 LevelDB 开发出 RocksDB key/value 数据库,特别针对服务器负载而优化,能够充分利用闪存性能),例如管理对象到磁盘位置的映射。
- 数据完整性和校验和。默认数据和有元数据写入 Bluestore 时受保护的,会有一次或多次的校验,未经验证的数据不会返回给用户。
- 压缩机制。写入的数据在写入之前可选择进行压缩。
- 多设备使用。Bluestore 允许内部日志写入到更快速的存储设备上。
- 写时复制。RBD 和 CephFS 快照都依赖写时复制机制,这可为快照功能和擦除编码池提供更高效的 I/O 性能。
Filestore
- 使用抽象的文件系统管理磁盘上的数据(例如XFS),使用 LevelDB key/value 数据库管理元数据。
- Filestore 经过的充分的生成环境测试和考验,但依赖于文件系统将带来更多的性能损耗和复杂性。
- 理论上 Filestore 存储引擎支持兼容 POSIX 格式的文件系统,但推荐使用 XFS 文件系统。
8.2 配置说明
所有 ceph 配置选项都由一个唯一名称,用小写字符组成的单词组成,并用下划线连接,当配置选项出现在配置文件当中时,也允许使用空格连接。当在命令行进行配置时 _ 和 - 都可以使用。例如 –mon-host 和 –mon_host 的效果相同。
读取配置方式
当 ceph 集群守护进程启动时,首次会依次从命令行、本地配置文件、解析配置选项,然后连接 Monitor 集群检索集中式配置数据库。以下列表优先级从小到大,:
- 默认值
- Monitor 集群中的集中式配置数据库
- 本地配置文件
- 环境变量
- 命令行
- 运行时更改配置的选项
必配项
因为有些配置选项影响到进程连接 Monitor 节点、认证、拉取配置选项等,所以必须将这些配置选项须在本地配置文件中进行配置。
mon_host
mon_dns_serv_name
mon_data、osd_data、mds_data、mgr_data
keyring、keyfile:和 monitor 节点认证所需的密钥信息,通常密钥文件在进程相对的数据目录中,通常不需要额外配置。
在某些情况下,当 monitor 节点无法通信时,可通过 --no-mon-config 忽略从 monitor 节点检索配置选项,在某些 monitor 节点故障排查的情况下可使用此选项。
配置段
在 monitor 集群集中式配置数据库中 ceph 集群的配置段分为几部分,包括:global mon mgr osd mds client ,这些配置段可以指定针对哪一个进程或客户端生效,例如:mon.node1、osd.0、client.test 等。生效优先级为最具体的部分最优先生效,本地配置文件中的配置项始终优先于 monitor 集群中的集中式配置数据库中的配置。此外,配置文件中还支持掩码的形式(两种方式)进一步指定对那些进程生效。
示例
# 格式1
type:location
# 格式2
class:device-classtype 是 CRUSH 中 type 的属性值字段,例如 host、rack 等,例如 host.osd,限制为某个主机上的特定进程或客户端,location 是 type 的值。
device-class 是 CRUSH 设备类的名称(例如hdd或ssd),例如 class:ssd,此类掩码不适用于非 osd 进程的配置。此外还可以使用例如 osd/rack:foo 表示所有机架上的 osd。
读取配置文件
当 ceph 进程启动时,会从以下几个位置读取配置文件。
- $CEPH_CONF ($CEPH_CONF环境变量指定)
- -c path/path (命令行)
- /etc/ceph/$cluster.conf
- ~/.ceph/$cluster.conf (家目录)
- ./$cluster.conf (当前目录)
注:使用 # 或者 ; 添加注释;如果配置值过长可以使用
\换行;配置值包含空格可使用双引号或单引号引用;可以使用\转义特殊配置值中的特殊符号,例如 # [ 等符号。
命令行配置
# 给某个进程或客户端设置配置项
ceph config set <who> <option> <value>帮助信息
ceph config help <option>
ceph daemon <name> config help [option] # 从特定进程中查找帮助信息
ceph config help log_file -f json-pretty # 输出 json 格式的帮助信息覆盖配置信息
可以使用 tell 或 daemon 子命令在命令行设置临时值,进程重启后设置值失效。
# 通过网络提交配置信息,tell 命令可接受通配符,例如 osd.*
ceph tell <daemon_name> config set <option> <value>
# 通过本地套接字提交配置信息 /var/run/ceph/
ceph daemon <daemon_name> config set <option> <value>配置信息查看
# 列出所有的可用配置项
ceph config ls
# 获取存储在 monitor 集群配置数据库中的配置项
ceph config dump
# 获取指定进程或客户端存储在 monitor 集群配置数据库中的配置项
ceph config get <who> [<option>]
# 显示某个正在运行的进程的运行配置
ceph config show <who>
# 查看某个进程的默认配置
ceph config show-with-defaults <who>
# 将从输入文件中提取配置文件,并将所有有效选项移至 mointor的配置数据库中。对于从旧版配置文件过渡到基于集中式监视器的配置很有用
ceph config assimilate-conf -i <input file> -o <output file>
# 从运行中进程的socket文件获取配置信息
ceph daemon <who> config show
# 获取被改变的配置参数
ceph daemon <who> config diff
# 获取指定配置参数的值
ceph daemon <who> config get <option>
# 查看当前所有配置项
ceph --show-config8.3 Monitor 配置
在生成环境中通常至少部署三个 monitor 节点保证 Monitor 的高可用性,同时也能够确保 Paxos 算法能够确保那个 Cluster Map是最新的并且能够有仲裁结果。ceph-mon 进程在 V2 版本中通常监听在 3300 端口,V1 版本中监听 6789 端口,ceph-mon 的数据目录通常在 /var/lib/ceph/mon/{cluster-name}-{mon-name} 目录下。
Ceph Monitor 维护一个最新(主副本)的 Cluster Map ,这意味着客户端能够通过取到最新的 Cluster map,从而取到最新的集群状态信息,包括 monitor、osd daemon、meatadata server等信息。
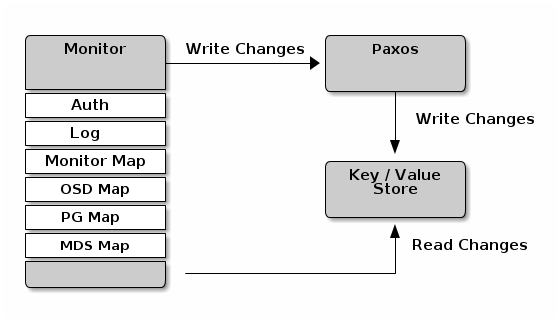
8.3.1 基本配置
cluster Map
Cluster Map 包括了 Monitor Map、OSD map、PG map、Metadata server Map。Cluster Map 跟踪和记录几个重要方面:1、Ceph 集群中有哪些进程;2、哪些进程在集群中是 up 还是 down 状态;3、PG 状态;4、集群容量及使用量等其他信息。当集群状态发生变化,例如守护进程停止、pg进入降级状态,集群将更新信息并反映当前状态。此外,monitor 还维持一个历史状态信息,即维护 cluster map 的历史版本,我成每个版本为 epoch。
Monitor quorum
Monitor 使用 Paxos 算法来确定和达成谁是主 cluster map 副本的共识。
# 强制将 monitor 加入选举,即便 monitor 已经从 map 中移除
mon force quorum join = false | true一致性
当将一个 monitor 加入集群时,集群会严格执行 monitor 之间的一致性操作。ceph 客户端和其他 ceph 进程通过 cpeh 配置文件发现 monitor 节点,而 monitor 节点之间通过 monitor map 发现。避免配置文件配置字段的错误,另外,配置文件不会自动分发和更新。monmap 是保证 monitor 之间一致性的重要手段。严格执行一致性也适用于对 monmap 的更新,monitor 集群将通过 Paxos 算法确保 monitor 之间的一致性,例如添加或删除 Ceph monitor,以确保仲裁中的每个节点都具有相同版本的 monmap。对 monmap 的更新是渐进式的,因此 monitor 之间有一个最新的 monmap 商定版本和一个上一个 monmap 版本,这样的好处是可以使得处于落后的 monitor 节点能够渐进的将 monmap 更新至最新版本。
Monitor 初始化
Monitor 自举或初始化时需要显示的在配置文件中进行配置。
- fsid:fsid 是 ceph 集群的唯一标识符。部署工具通常会自动生成 fsid,也可以手动指定,使用 uuidgen 命令。
- Monitor ID:是 Monitor 集群中节点的唯一标识符。
- key:初始化 monitor 时,需要生成相对应的密钥。
8.3.2 数据配置
通常情况下,ceph 提供了默认的数据存储目录,在生产环境中为了实现最佳性能,建议将 ceph-mon 和 ceph-osd 分离部署(至少是不同磁盘),因为 RockDB 使用 mmap() 写数据,monitor 刷新数据到磁盘是非常频繁的,则ceph-mon 可能会干扰 osd 进程的负载。在 ceph 0.58 之前,ceph monitor 将数据写入文件中,这种方式允许管理员使用 cat 或 ls 看查看数据,然而却不能保证数据的强一致性。在之后的版本中,ceph monitor 数据存储在键值对中,符合 ACID 规则。通常不建议修改 monitor 默认的数据位置。
# monitor 数据目录
mon data = /var/lib/ceph/mon/$cluster-$id
# 当 monitor 数据达到多大容量时,给 cluster 发出 HEALTH_WARN 警告,默认是 15 G
mon data size warn = 16106127360
# 当 monitor 数据存储空间小于或等于某个百分比时,向 cluster 发出 HEALTH_WARN 警告
mon data avail warn = 30
# 当 monitor 数据存储空间小于或等于某个百分比时,向 cluster 发出 HEALTH_ERR 警告
mon data avail crit = 5
# 缓存池未配置 hit_set_type 值时,给 cluster 发出 HEALTH_WARN 警告
mon warn on cache pools without hit sets = True
# 当 straw_calc_version 值为 0 时,向 cluster 发出 HEALTH_WARN 警告
mon warn on crush straw calc version zero = True
# 当 CRUSH 可调参数是就版本时,向 cluster 发出 HEALTH_WARN 警告
mon warn on legacy crush tunables = True
# 集群所需的最低可调配置文件版本
mon crush min required version = hammer
# 如果 mon_osd_down_out_interval 的值为 0,向 cluster 发出 HEALTH_WARN 警告
mon warn on osd down out interval zero = True
# 如果 osd 之间的心跳信息超过 osd_heartbeat_grace 指定时间的百分之多少时,向 cluster 发出 HEALTH_WARN 警告
mon warn on slow ping ratio = 0.05
# 覆盖 mon_warn_on_slow_ping_ratio 的值,指定一个具体值,单位为毫秒,默认是禁用的。
mon warn on slow ping time = 0
# 如果 pool 没有设置副本数量,向 cluster 发出 HEALTH_WARN 警告
mon warn on pool no redundancy = Ture
# 当达到 cache_target_full 和 target_max_object 指定的百分之多少时,开始发出警告
mon cache target full warn ratio = 0.66
# 是否定期写入日志报告集群状态摘要信息
mon health to clog = True
# 定期向日志写入集群状态信息摘要的时间间隔。如果当前运行状况摘要为空或与上次相同,则 monitor 不会将其发送到集群日志
mon health to clog tick interval = 60
# 定期向日志写入集群状态信息摘要的时间间隔。如果当前运行状况摘要为空或与上次相同,则 monitor 也会将其发送到集群日志
mon health to clog interval = 36008.3.3 存储容量
当 ceph 集群存储达到最大容量,集群将为了数据安全,会停止客户端读取和写入数据,因为数据存储量增加可能导致数据的丢失,默认值是容量的 95%,在有少量 osd 的集群中,尽量将此值设置尽可能小一些。
# OSD 硬盘使用率达到多少就认为它 full,无法写入数据
mon osd full ratio = .95
# OSD 硬盘使用率达到多少就认为它 nearfull,ceph状态会发出告警
mon osd nearfull ratio = 0.85
# OSD 硬盘使用率达到多少就认为它剩余空间太少而无法回填,拒绝 PG通过 backfill 方式迁入或迁出数据从此osd中
mon osd backfillfull ratio = .90
# 防止 OSD 磁盘空间被 100% 写满,超过此限制,则写入操作将被丢弃
osd_failsafe_full_ratio = 0.978.3.4 数据同步
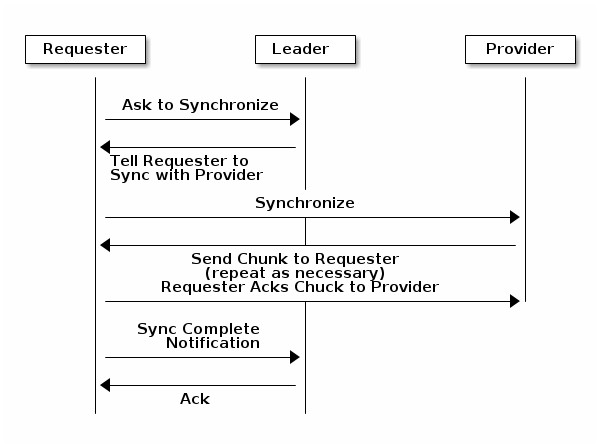
monitor 可能有以下三个角色:
- leader:是第一个获得最新 Paxos 版本的集群映射的 monitor。
- provider:Provider 具有 cluster map 的最新版本,但不是第一个获得最新版本 cluster map 的节点。
- requestr:此角色的节点的 cluster map 版本已落后于最新版本,需要同步最新版本的 map,才能加入集群中。
leader 可以将同步职责委派给 provider,避免集中的同步请求增加 leader 的负载。下图中,Requester 得知自己的 cluster map 的版本落后于其他节点后,向 leader 发起同步请求,之后 leader 将同步任务委派给 provider。
# monitor 在放弃并重新引导之前将等待其同步程序发出的下一个更新消息的秒数
mon sync timeout = 60
# 同步数据有效负载字节数
mon sync max payload size = 1048576
# 强制修剪 mdsmap 到某一个版本(默认为0,表示禁用,慎操作)
mon mds force trim to = 0
# 强制修剪 osdmap 到某一个版本,即便指定的版本有 pg 不处于 clean 状态(默认为0,表示禁用,慎操作)
mon osd force trim to = 0
# osdmap 的缓存大小
mon osd cache size = 500
# 选举提议时,ACK 的超时时长
mon election timeout = 5.00
# 租约机制。leader节点会定期发送lease消息,延长各个peon的时间,但是如果某个peon 节点挂掉,leader节点就无法收到lease_ack消息,超时之后,就会重新选举。leader节点也可能会异常宕机,peon节点也要能监督leader节点。如果leader down掉,peon节点就收不到来自leader的lease更新消息,超时之后,会选举。此配置项表示,每次延长 leader 租约多长时间,单位为秒
mon lease = 5.0
# monitor 多久发送一次 lease 信息 (小于1)
mon lease renew interval factor = 0.60
# 超时时间,超过这个时间多久后重新选举。leader等待provider告知其版本的秒数
mon lease ack timeout factor = 2.0
# leader等待 requester 同步的最大时间(默认2s),默认值是2.0
mon accept timeout factor = 2.0
# OSD map维持的最小版本号数量(默认500),默认值是500
mon min osdmap epochs = 500
# monitor保留的最大的log版本号数量(默认500),默认值是500
mon max log epochs = 500关于 paxos 算法的配置项
# 当 monitor 数据版本落后于其他节点很多时,首先会进行数据同步,然后继续之后的任务。在此次数据同步之前,Paxos 迭代的次数
paxos max join drift = 10
# 每个PaxosService代表集群的一种状态信息。对应的,Ceph Moinitor中包含分别负责OSD Map,Monitor Map, PG Map, CRUSH Map的几种PaxosService。此值表示保存 PaxosService 状态副本的频率(以 commit 为单位),影响 mds,mon,auth 和 mgr PaxosServices
paxos stash full interval = 25
# map 更新之前,收集变更和更新的时间间隔
paxos propse interval = 1.0
# 维持最低数量的 paxos 状态
paxos min = 500
# 经过一段时间不活动后收集更新的最短时间
paxos min wait = 0.05
# 操作前允许的其他操作数量,最小
paxos trim min = 250
# 操作前允许的其他操作数量,最大
paxos trim max = 500
paxos service trim min = 250
paxos service trim max = 5008.3.5 时钟同步
ceph 守护进程之间传递和发送各种关键信息,在守护进程达到超时阈值之前,接收方需要处理这些信息。如果时间未同步,则可能出现:1、守护进程忽略接收到的信息,时间戳过期;2、未接收到信息,触发超时阈值,集群进入不正常状态。
# mon 之间心跳时间间隔
mon tick interval = 5
# 允许时钟偏移的时长
mon clock drift allowed = 0.05
# 时钟偏移延迟时长警告,偏移超过指定秒数后开始警告
mon clock drift warn backoff = 5
# 时钟检测时间间隔(和 leader 的时间检测)
mon timecheck interval = 300
# 当和 leader 出现时钟偏移后,时钟检查间隔
mon timecheck skew interval 30.008.3.6 client 配置
# 客户端将每隔 N 秒尝试一个新的 monitor,直到建立连接为止
mon client hunt interval = 3.00
# 客户端每 N 秒 ping monitor
mon client ping interval = 10.00
# 根据每个客户端消息生成的最大日志条目数
mon client max log entries per message = 1000
# 内存中允许的客户端消息数据量(以字节为单位)
mon client bytes = 1048576008.3.7 pool 配置
# 是否允许 monitor 删除 pool
mon allow pool delete = false
# 是否打开 pool 中的快速读取,如果 fast_read 在创建时未指定,则作为新创建纠删码池的默认配置
osd pool default ec fast read = false
# 是否设置新创建的 pool hashpspool 标记
osd pool default flag hashpspool = true
# 给新建的 pool 设置 nodelete 标记,意味着不能删除此池,需要配置文件进行配置。如果需要取消标记可以使用:ceph osd pool set testpool nodelete 0 命令进行取消标记
osd pool default flag nodelete = false
# 给新创建的池标记不允许修改 pg 数量的标记。ceph osd pool set testpool rbd pg_num 64命令可以更改 pool 的 pg 数量,可调整多或者少
osd pool default flag nopgchange = false
# 给新创建的池标记不允许修改pool大小。可使用osd pool set-quota <poolname> max_objects|max_bytes <val> 命令设置 pool 的容量限制和文件数量限制。0表示无限制
osd pool default flag nosizechange = false8.3.8 其他配置
# 集群中允许的最大 osd 数量
mon max osd = 10000
# 集群为客户端和所有进程分配的全局ID数量
mon globalid prealloc = 10000
# 以秒为单位的刷新订阅时间,订阅机制可以获取群集映射和日志信息
mon subscribe interval = 86400
# ceph 将平滑的统计最后 N 个 pg map
mon stat smooth intervals = 6
# 监视器自举无效,搜寻节点前等待的时间
mon probe timeout = 2
# 元数据服务和 osd 信息在内存中的占用上限
mon daemon bytes = 419430400
# 每个事件允许的最大日志条数
mon max log entries per event = 4096
# 当一个 osd 加入集群时,启用或禁用使用先前的 pgmap,如果设置为 true,则客户端使用先前的 osd,直到新加入的 osd 与其他 osd 对等
mon osd prime pg temp = true
# 当退出的 osd 重新加入时,monitor 花费多长时间来填充和更新 pgmap
mon osd prime pg temp max time = 0.5
# 在每个 PG 上所花费时间的最大估值,超过此值我们就并行地捡回所有 PG
mon osd prime pg temp max time estimate = 0.25
# 跳过 FSMap 的安全性检查确认(遇到软件缺陷时还想继续)。如果 FSMap 健全性检查失败,监视器会终止,但我们可以让它继续,启用此选项即可
mon mds skip sanity = false
# 在单个时间中一次性可以修剪多个版本的 mdsmap
mon max mdsmap epochs = 500
# config-key 条目的最大尺寸,单位为字节
mon config key max entry size = 65536
# 以秒为单位,多久去清洗一次,通过计算存储校验和和计算存储密钥来进行清洗
mon scrub interval = 3600*24
# 每次最多洗刷多少个键
mon scrub max keys = 100
# 启动时压缩监视器存储所用的数据库。如果日常压缩失效,手动压缩有助于缩小监视器的数据库、并提升其性能
mon compact on start = false
# 自举引导期间压缩 monitor 所用的数据库,monitor 完成自举引导后开始互相探测,以建立法定人数;如果加入法定人数超时,它会从头开始自举引导
mon compact on bootstrap = false
# 清理旧的状态存档时也压缩这个前缀(包括 paxos )
mon compact on trim = True
# monitor 执行CPU密集工作时使用的线程数
mon cpu threads = 4
# 我们按块计算归置组到 OSD 的映射关系。这个选项指定了每个块的归置组数量
mon osd mapping pgs per chunk = 4096
# 会话闲置时间超过此限制,监视器就会终结这个不活跃的会话
mon session timeout = 300
# osd 映射的缓存保留在内存中最小字节数
mon osd cache size min = 134217728
# monitor 持有的 osd 信息在内存中的缓存数和启用高速缓存自动调整后,kv高速缓存将保留在内存中的映射
mon memory target = 2147483648
# 自动调整用于 OSD monitor 和 KV 数据库的缓存
mon memory autotune = True8.4 认证配置
在 Bobtail v0.56 版本之后,可以明确进行配置是否启用 cephx 认证。在 ceph 集群升级过程中,应该明确声明关闭 cephx 的认证。
auth cluster required = cephx
auth service required = cephx
auth client required = cephxcephx 认证协议默认是启用的,尽管密码认证会消耗一些计算资源,但可以忽略不计。如果关闭 cephx 认证协议,则可能会受到中间人攻击,导致服务瘫痪和故障。
8.4.1 启用/禁用 cephx 认证
默认情况下,会在 /etc/ceph/ 目录下查找密钥文件,但也可以在配置文件中指定密钥文件路径,但不建议这样操作。以下步骤的在未开启 cpehx 认证集群上开启认证的方式。
# 创建一个客户端管理员密钥
ceph auth get-or-create client.admin mon 'allow *' mds 'allow *' mgr 'allow *' osd 'allow *' -o /etc/ceph/{cluster_name}.client.admin.keyring
# 创建一个 monitor 节点之间通信的密钥环文件,然后复制到每一个 monitor 节点的数据目录
ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
cp /tmp/ceph.mon.keyring /var/lib/ceph/mon/{cluster_name}-{mon_name}/keyring
# 生成 mgr 通信密钥
ceph auth get-or-create mgr.{$id} mon 'allow profile mgr' mds 'allow *' osd 'allow *' -o /var/lib/ceph/mgr/{cluster_name}-{$id}/keyring
# 给每一个 osd 生成密钥
ceph auth get-or-create osd.{$id} mon 'allow rwx' osd 'allow *' -o /var/lib/ceph/osd/{cluster_name}-{$id}/keyring
# 给 mds 节点生成密钥
ceph auth get-or-create mds.{$id} mon 'allow rwx' osd 'allow *' mds 'allow *' mgr 'allow profile mds' -o /var/lib/ceph/mds/{cluster_name}-{$id}/keyring
# 配置文件中明确启用 cephx 认证功能
auth cluster required = cephx
auth service required = cephx
auth client required = cephx禁用 cephx
auth cluster required = none
auth service required = none
auth client required = none关于 key
尽管在配置文件中可以指定密钥、密钥环文件、密钥字符串等的位置或内容,但强烈不建议这样做。
# 密钥
key =
# 包含密钥的文件
keyfile =
# 密钥本身内容
key =8.4.2 守护进程密钥
运行的进程密钥文件都有默认路径,但强烈不建议手动指定位置。
ceph-mon = /path/to/keyring
ceph-osd = /path/to/keyring
ceph-mds = /path/to/keyring
ceph-mgr = /path/to/keyring
radosgw = /path/to/keyring8.4.3 签名校验
为了在消息传递过程中避免被篡改,ceph 还提供了签名校验,提供一个更细粒度的认证控制。ceph 提供配置参数提供启用或关闭签名校验。
# 如果设置为true,则Ceph要求在Ceph客户端和Ceph存储集群之间以及组成Ceph存储集群的守护程序之间的所有消息通信上签名校验。ceph Agronaut 之前的版本和 linux kernel version 3.19 之前不支持签名校验
cephx require signatures = false
# 组成 ceph 集群的守护进程之间需要签名校验
cephx cluster require signatures = false
# 客户端在 ceph 集群服务之间的消息传递进行签名校验
cephx service require signatures = false
# 将集群之间及客户端之间的所有消息进行签名校验
cephx sign messages = false
# ceph 客户端在 ceph 集群的认证凭证存活时间
auth service ticket ttl = 60*608.5 OSD 配置
8.5.1 基本配置
# osd 进程的 uuid,部署工具会自动生成,也可以手动生成,但通常不需要配置文件指定
osd uuid =
# 配置 osd 的数据目录(不建议更改此值)
osd data =
# 写入的最大大小(以M单位)
osd max write size = 90
# RADOS对象的最大大小(以字节为单位)
osd max object size = 128M
# 内存中允许的最大客户端数据消息(以字节为单位)
osd client message size cap = 500M
# RADOS 类插件的路径
osd class dir = /usr/lib64/rados-classes8.5.2 Journal 配置
当使用单个设备作为 osd 的存储设备时,journal 会和 data 并置存储到同一个设备上。当使用多种类型的设备时,例如有 ssd 或 NVMe 硬盘时,将 journal 放置到较快的存储设备上,能够有效的提升存储性能,数据则存储到较慢的存储设备上。
# osd journal 的保存路径,这可能是一个文件路径或者一个设备分区。如果是一个文件,则必须创建目录包含此文件,建议将 journal 和数据路径分离存储
osd journal =
# journal 日志的大小
osd journall size = 5120ceph osd 使用 journal 有两个目的:增强性能和保证数据一致性。journal 能够保证 osd 进程能够更快提交写入,能够将小文件和随机 I/O 先写入日志,然后合并之后并行的写入 osd 后端存储。ceph osd 进程需要保证操作的原子性,osd 进程将操作写入日志,并应用于文件系统之上,能够保证操作的原子性,例如 pg 元数据的更新。
# 对于 journal 启用 direct i/o 方式。需要启用 journal block align 特性
journal dio = true
# 对于 journal 启用异步 i/o 的方式写入。需要启用 journal dio 特性
journal aio = true
# 对于 journal 的写入块进行对齐。需要启用 dio 和 aio 特性
jouranl block align = true
# 日志一次可以写入journal 的最大字节数,默认为 10 M
journal max write bytes = 10485760
# 一次可以最大写入 journal 的条目数
journal max write entries = 100
# journal一次性最大在队列中的操作数
journal queue max ops = 500
# 允许某一时刻队列中 journal 的最大字节数,默认为 10 M
journal queue max bytes = 10485760
# 最小对齐大小,默认为 64 k
journal align min size = 64K
# 在创建文件系统期间用0填充整个日志
journal zero on create = false8.5.3 数据刷洗
在多副本的情况下,为了保证数据的一致和完整,ceph 通过对 pg 进行刷洗来完成,类似于 fsck 在对象存储层进行刷洗数据。对于每个 pg 中的对象,ceph 都会生成其中存储对象的目录,并对存储对象的主副本进行比对,以保证数据不丢失或不匹配。轻度刷洗情况下(每天),检查对象的大小和属性,深度刷洗的情况下(每周),会读取数据并使用校验和检查以确保数据完整性。数据刷洗能够有效保障数据的完整性,但同时也会带来一些性能上的消耗。
# 一个 osd 进程“刷洗操作”任务的并发数量
osd max scrubs = 1
# 一天中的几点之后可以开始进行刷洗,取值范围是 0-24
osd scrub begin hour = 0
# 与 begin hour 定义了一个时间窗口。在此时间窗口内可能发生刷洗任务。但是只要超过 osd scrub max interval 指定值,刷洗工作都将进行,无论是否在时间窗口内。
osd scrub end hour = 24
# 将刷洗工作限制在一周的某一天开始,0或7表示星期日,1,表示周一
osd scrub begin week day = 0
# 可以将刷洗时间限制在某几天的范围内
osd scrub end week day = 7
# 在恢复期间时候允许刷洗
osd scrub during recovery = true
# scrub 线程执行的最大时间(单位秒)
osd scrub thread timeout = 60
# 超过这个时间,则断定 scrub 线程超时
osd scrub finalize thread timeout = 60*10
# 当系统负载超过此值时,ceph 将不会进行 scrub 工作
osd scrub load threshold = 0.5
# 考虑集群负载情况,在负载低的情况下,最少多久进行一次 scrub
osd scrub min interval = 60*60*24
# 不考虑集群负载情况,最多多久进行一次 scrub
osd scrub max interval = 7*60*60*24
# 单次 scrub 操作最小的对象存储块的数量
osd scrub chunk min = 5
# 单次 scrub 操作最大的对象存储块的数量
osd scrub chunk max = 25
# 在进入对下一组的存储块刷洗之前,scrub 睡眠时间。增大此值将减慢整个刷洗操作,而对客户端操作的影响较小
osd scrub sleep = 0
# osd scrub load threshold 不会影响此配置的操作。多长时间进行一次深度刷洗
osd deep scrub interval = 60*60*24*7
# 当调度下一次 scrub 任务时给"osd scrub min interval"添加一个随机的延迟时间。这个随机延迟时间值小于"osd scrub min interval * osd scrub interval randomized ratio"的值,因此时间窗口应该是 [1,1.5] * osd scrub min interval
osd scrub interval randomize ratio = 0.5
# 进行深度数据刷洗时读取大小
osd deep scrub stride = 512kb
# 当在 scrub 过程中如果发现有错误的 pg,则进行自动修复。但是如果错误pg数量超过"osd scrub auto repair num errors"指定的值,则不自动进行修复
osd scrub auto repair = false’
# 如果发现pg错误数量超过此值,将不会进行自动修复
osd scrub auto repair num errors = 58.5.4 操作优先级 (待完善)
# 设置 osd 内部各种操作的优先顺序。有常规队列和严格子队列两种模式。两种队列都实现了严格子队列,出常规队列之前要先出子队列,它与常规队列的实现机制不同。最初的 PrioritizedQueue (prio) 使用令牌桶系统,在令牌足够多时它会先处理优先级高的队列;在令牌不够多时,则按优先级从低到高依次处理。新WeightedPriorityQueue (wpq) 会根据其优先级处理所有队列,以避免出现饥饿队列。在一部分 OSD 负载高于其它的时,WPQ 应该有优势。新的基于mClock的OpClassQueue(mclock_opclass)根据操作所属的类(recovery, scrub, snaptrim, client op, osd subop)对操作进行优先级排序。基于mClock的ClientQueue(mclock_client)也合并了客户端标识符,根据客户端进行划分,以促进客户端之间的公平。此配置选项需要重启。可选值有 prio, wpq, mclock_opclass, mclock_client
osd op queue = wpq
# 本选项用于配置把哪个优先级的操作放入严格队列、还是常规队列。 low 这个选项会把所有复制操作以及优先级更高的放入严格队列;而 high 选项只会把复制的确认反馈操作以及优先级更高的发往严格队列。此选项设置为 high 时,应该有助于缓解集群内某些 OSD 特别繁忙的情形,尤其是配合 osd op queue 设置为 wpq 使用时效果更佳。忙于处理副本流量的 OSD 们,如果没有这些配置,它们的主副本( primary client )客户端往往比较空闲。此配置更改后需重启,可选值为 low, high
osd op queue cut off = high
# Ceph能够优先执行某些操作,从而使客户端I/O优先于恢复,清理和快照修整 IO等。值越高,优先级越高。默认值工作得很好,并且不需要太多更改它们。但是,降低清理和恢复操作的优先级以限制它们对客户端I/O的影响可能会有一些好处。为客户端操作设置的优先级,可取值范围为1-53
osd client op priority = 63
# 如果池未指定scrub_priority的值,则为计划的scrub工作队列设置默认优先级。当scrub阻止客户端操作时,可以将此值提高到osd客户端操作优先级的值
osd scrub priority = 5
# 为恢复操作设置的优先级,如果未由池 recovery_op_priority 指定
osd recovery op priority = 3
# 在工作队列上为用户请求的清理设置优先级。如果此值小于osd client op priority,则可以在scrub阻止客户端操作时将其提升为osd客户端操作优先级的值
osd requested scrub priority = 120
# snap 修剪工作优先级
osd snap trim priority = 5
# 下次 snap 修剪工作之前,睡眠多久。增大此值将减慢快照修剪
osd snap trim sleep = 0
# 在下一次修剪调整HDD之前,睡眠时间(以秒为单位)
osd snap trim sleep hdd = 5
# 在下一次修剪调整SSD之前,睡眠时间(以秒为单位)
osd snap trim sleep ssd = 0
# 当osd数据位于HDD上且osd日志位于SSD上时,下一次快照修整操作之前睡眠的时间(以秒为单位)
osd snap trim sleep hybrid = 2
# Ceph OSD守护程序操作线程超时时长(以秒为单位)
osd op thread timeout = 15
# 一个操作进行多久后开始抱怨
osd op complaint time = 30
# 跟踪的最大已完成操作数
osd op history size = 20
# 要跟踪的最老已完成操作
osd op history duration = 600
# 一次显示多少操作日志
osd op log threshold = 5ceph QoS
ceph 基于 dmClock 算法的队列调度实现了 QoS 功能。该算法按权重分配 Ceph 集群的 I/O 资源,并强制执行最小和最大保留,使服务可以公平竞争资源。当前 mclock_opclass 操作队列将涉及到 I/O 的资源划分为以下几类:
- client op:客户端发出通知的 iops
- osd subop:主 osd 发出通知的 iops
- snap trim:快照修剪操作的相关请求
- pg recovery:恢复操作的相关请求
- pg scrub:刷洗操作的相关请求
ceph 使用以下三组 tag 来对资源进行标记,也就是说,每种服务的优先级由三个 tag 控制:
- reservation:为服务分配的最小 IOPS
- limitation:为服务分配的最大 IOPS
- weight:如果超出预设配额或超额使用,则按比例分配容量
在Ceph中,操作按 “cost” 分级,这些 “cost” 消耗分配用于各种服务的资源。即如果服务拥有的保留资源越多,则可能拥有的资源越多。示例如下:
- recovery: (r:1, l:5, w:1)
- client ops: (r:2, l:0, w:9)
解释:
recovery: (r:1, l:5, w:1)表示 recovery 服务收到的请求数每秒不超过 5 个,即使 recovery 需要比 5 更多的请求,且 recovery 服务不会和其他服务产生竞争。只要有 recovery 请求,就一定会为之分配至少每秒 1 个请求,带来的好处是,即使是在高负载的集群中,也会保证给 recovery 能够正常进行。client ops: (r:2, l:0, w:9)中 client 的比重是 9 ,而与之竞争的服务 recovery 比重是 1,因此能够留更多的 I/O 资源给 client,对于 client 没有最大 IOPS 的限制,因此可以利用所有的 I/O 资源。
limitation 和 reservation 的值是以每秒的请求数为单位的,而 weight 是没有单位的,是一个相对的概念,如果两类操作 I/O 的类型的 weight 分别为 9 和 1,则前一类操作和后一类操作将按照 9:1 的比例获得 I/O 资源。
8.5.6 backfill/recovery
backfill
当从集群中删除或添加一个 OSD 之后,CRUSH 算法将通过移入或移除 PG 的方式来重新平衡数据。在 Ceph 中,通过 backfilling 的方式来实现数据的移动。
# 单个 OSD 进程允许的最大 backfill 操作数
osd max backfills = 1
# 每次 backfill 操作允许扫描的最小 | 最大 object 数量
osd backfill scan min = 64 | osd backfill scan max = 64
# 重试 backfill 操作之前等待时间
osd backfill retry interval = 10.0recovery
当某个 osd 故障或与集群失联又重新加入集群后,osd pg 会进入 peering 状态,然后开始写入数据 (与其他 osd 进行同步数据) 。当发生 recovery 时,ceph osd 守护进程进入 recovery 模式,并将获取数据的最新副本并和自己所持有的数据进行同步。当有大量 osd ,例如在一个故障域内的所有 osd 奔溃或故障,则回填过程会既费时又消耗大量性能。为了保证回填过程不至于导致集群网络拥堵或负载过高,ceph 可以对 recovery 请求数、线程、对象块大小进行限制和优化,保证在集群降级的状态下保证良好的性能。
# osd peering 完成之后,ceph 将延迟指定时间后开始恢复 objects
osd recovery delay start = 0
# 每个 osd 同时可以启动多少个恢复请求,尽管更多的请求将加快恢复,但可能会对集群负载造成压力。此值通常为 0,如果设置设置为 0 ,则取决于 osd recovery max active hdd 和 osd recovery max ssd 设置的值
osd recovery max active = 0
# 在主存储是机械盘的 osd 之上同时可以启用多少个 recovery 请求
osd recovery max active hdd = 3
# 在主存储是 SSD 的 osd 之上同时可以启用多少个 recovery 请求
osd recovery max active ssd = 10
# recovery 最大的 chunk 块大小,默认为 8M
osd recovery max chunk = 8388608
# 当 osd recovery 时,每个 osd 新启动的最大恢复操作数
osd recovery max single start = 1
# 恢复线程超时时长
osd recovery thread timeout = 30
# 限制恢复期间的克隆、恢复期间保留克隆重叠,应该始终设置为 true
osd recover clone overlap = true
# 下次恢复或回填操作之前的睡眠时间(以秒为单位),增加此值将减慢恢复操作,而对客户端操作的影响较小
osd recovery sleep = 0
osd recovery sleep hdd = 0.1
osd recovery sleep ssd = 0
# 当osd数据位于HDD上且osd日志位于SSD上时,下次恢复或回填操作之前进入睡眠状态的时间(以秒为单位)
osd recovery sleep hybrid = 0.025
# 为恢复工作队列设置的默认优先级。与池的recovery_priority无关
osd recovery priority = 58.5.7 OSD Map
随着集群运行不断变化,OSD Map epoch 版本会不断迭代增加,以下选项配置了对 OSD Map 处理的一些配置项。
# 启用移除重复 OSD Map 功能
osd map dedup = true
# 缓存 OSD Map 的个数
osd map cache size = 50
osd map message max = 408.6 Heartbeat 配置
在运行操作期间,ceph osd 守护进程检查其他 osd 进程并将检查结果报告给 monitor,通常不需要进行任何配置。当执行 ceph -s 等查看集群状态的命令时,ceph monitor 将报告集群当前的状态给管理员。monitor 要求每个 osd 进程报告自己的状态给自己,并接收 osd 从其他 osd 进程收集的其他 osd 状态的信息。如果 monitor 接收到集群的更改变化信息,monitor 将即时更新 cluster map 的状态。
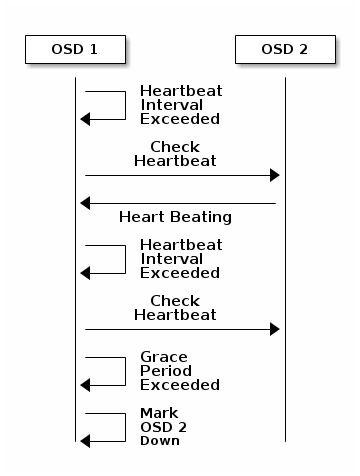
8.6.1 osd 之间心跳
每个 osd 守护进程都以随机的(避免峰值)少于 6 秒的时间间隔去检查其他 osd 进程,如果检查到某一个 osd 进程没有在宽限的 20 秒时间内没有心跳信息,则 osd 进程将报告此 osd 进程 down 的状态给 monitor,monitior 收到此报告后,立即更新 cluster map 信息。可以通过在 [mon] [osd] [global] 配置段先添加osd heartbeat grace 配置项来调整宽限时间。
8.6.2 osd 和 monitor 心跳
默认情况下,要确认一个 osd 为 down 的状态,需要来来自两个不同主机的 osd 向 monitor 报告此 osd 是 down 的状态,monitor 才会标记此 osd 为 down。但是还有一种情况,交换机故障,主机有又处于同一交换机下,此时,来自不同主机的 osd 是无法通信的,为了避免这种情况,我们认为对等 osd 之间的报告结果是可能在集群中有潜在的 “子集群”,类似于有 osd 落后。mon osd reporter subtree level 用于将 CRUSH map 中有共同父树的类型分组为 ”子集群“。默认情况下,只需要来自不同子树的两个报告即可报告另一个 Ceph OSD 守护进程为 down。从 ceph Jewel 版本开始,对于此种情况,可使用 mon osd min down reporters 来指定来自多个不同的子树的报告才确认结果,mon osd reporter subtree 来指定 CRUSH 中的那个父级节点,例如 host。
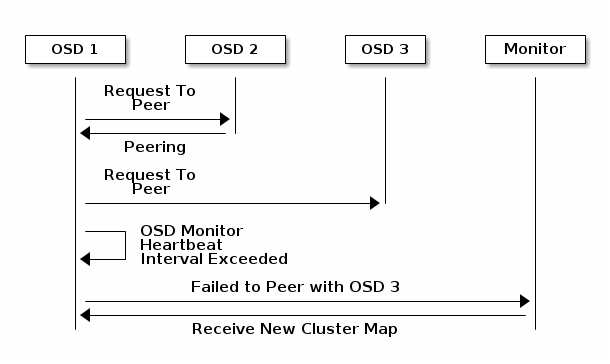
8.6.3 osd 窥视心跳
如果 osd 不能和任何对等的 osd 之间报告状态信息,它会每30秒ping Ceph Monitor以获得群集 cluster map 的最新副本。可通过 osd mon heartbeat interval (在[osd]配置段下配置) 配置来调整 osd ping monitor 的时间间隔。
8.6.4 osd 报告自身状态
如果 osd 不能够报告状态信息给 monitor,mointor 将在 配置段下使用 mon osd report timeout 指定的时间之后认为 osd 进程已经 down 掉。可以通过配置来修改 osd 向 monitor 报告的时间间隔,在 [osd] 配置段下使用配置项 osd mon report interval 来进行设置。而无论 osd 是否发生变化,osd 都每 120 秒向 monitor 发送报告信息,可以使用 osd mon report interval max 来配置最长报告时间。
up_thru 机制是为了避免当两个 osd 同时 down 掉,此时这两个 osd 之上有 同一个 pg,如果 A 先 down,B 后 down,那么在 A down 的时间段内,B 上有数据更新,当 A 先恢复后,由于 A 之上也保留了完整的数据,所以可以接受数据更新,但是由数据缺失,up_thru 可以追踪 osd 的 epoch 版本来避免这种情况。
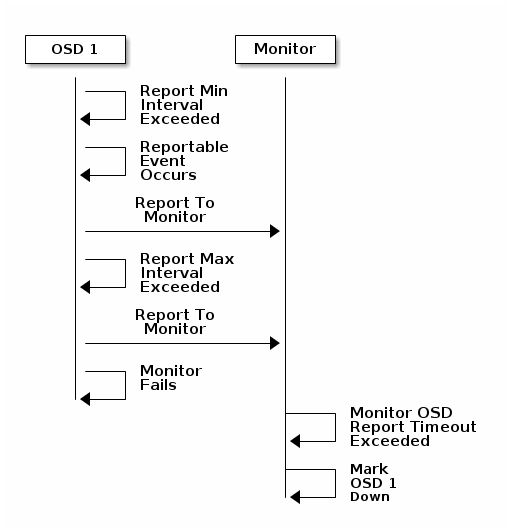
8.6.5 monitor 配置
# Monitor 将 OSD 标记为 down 之前,up 状态的 OSD 进程数量所占最小比例
mon osd min up ratio = .3
# Monitor 将 OSD 标记为 out 之前,in 状态的 OSD 进程数量所占最小比例
mon osd min in ratio = .75
mon osd laggy halflife = 3600
mon osd laggy weight = 0.3
mon osd laggy max interval = 300
mon osd adjust heartbeat grace = true
mon osd adjust down out interval = true
mon osd auto mark in = false
mon osd auto mark auto out in = true
mon osd auto mark new in = true
# 在 OSD 多长时间之内没有心跳时,将 down 掉的 OSD 标记为 out
mon osd down out interval = 600
# 在 CRUSH 层级结构中的某个层级单元的所有 OSD down 之后,不自动将这些 OSD 标记为 out
mon osd down out subtree limit = rack
# 当标记某个 OSD down 之前将延迟多长时间(超时时长)才认定其为 down
mon osd report timeout = 900
mon osd reporter subtree level = host8.6.6 osd 设置
# 配置 OSD 心跳网络,ceph 允许配置 OSD 的心跳网络为单独网络
osd heartbeat address =
# Ceph OSD 守护程序多久一次对伙伴 OSD 执行 ping 操作(以秒为单位)
osd heartbeat interval = 6
# 当某个 OSD 没有心跳信息多长时间以后 Ceph 将认为其已经 down。此配置必须显示的在配置文件 mon、osd、gloobal 段进行配置,因为 osd 和 mon 进程都可以读取此配置
osd heartbeat grace = 20
# 如果 OSD 不能和任何伙伴 OSD 之间通信以完成心跳检测时,OSD 多久 ping 一次 Monitor
osd mon heartbeat interval = 30
osd mon heartbeat stat stale = 3600
# OSD 向 Monitor 报告状态的时间间隔
osd mon report interval = 5
# OSD 等待 Monitor 请求统计信息后响应的超时时长
osd mon ack timeout = 308.7 Messenger V2 协议
Messenger v2 或 msg2 是第二版的 ceph 集群使用的通信协议,其主要特性有:1、通过网络传输的所有数据都进行了加密;2、改进了身份验证有效负载的封装,支持集成新的身份验证模式,例如 Kerberos;3、兼容旧版的特性,支持新版本的功能。目前 ceph 支持绑定多个端口,支持旧版的客户端和新版有 v2 特性的客户端连接。默认情况下,monitor 将绑定到新的 3300 端口,同时还绑定了旧版的 v1 默认端口 6789。
在 nautilus 版本之前,所有的网络地址有使用类似于 1.2.3.4:5678/8760 这样的格式的地址,IP地址 + 端口 + 随机数 来唯一表示一个客户端或者一个守护进程。新版本之后,使用如下格式来标识网络地址:
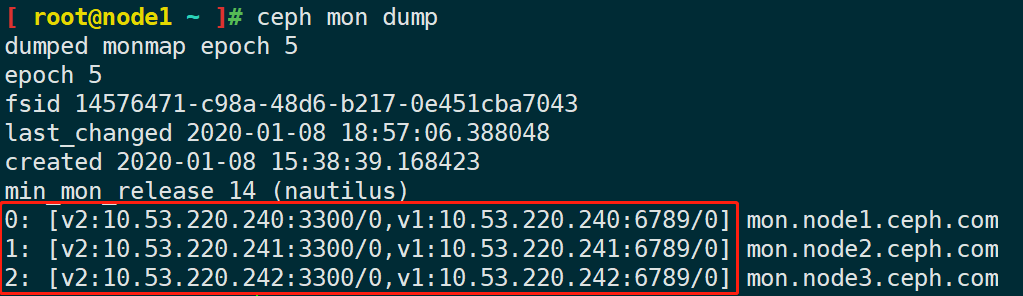
[ ] 之内的地址表示可以在多个端口和协议上访问同一个守护程序,客户端会优先使用 v2 版本的协议,否则将回退到使用 v1 版本。
配置控制选项:
ms_bind_msgr1 = true ms_bind_msgr2 = true ms_bind_ipv4 = true ms_bind_ipv6 = false
v2 支持的模块
v2 协议支持两种连接模块,分别是 crc 和 secure 。crc 支持建立连接时的身份认证,但不提供加密功能,流量是明文传输的。secure 模块能够提供流量加密功能,包括完整性检测。可以通过配置选项对不同的连接配置使用不同的模块,配置选项如下:
# 用于Ceph守护程序之间的集群内通信,如果配置多个模块的值,则首选第一个模块
ms_cluster_mode = "secure crc"
# 客户端连接到集群允许使用的模块列表
ms_service_mode =
# 一个列表,是客户端连接集群的使用的模块,按优先顺序排列
ms_client_mode = 此外,还有一组专门用于 monitor 通信使用的模块配置:
# monitor 之间使用的协议模块
ms_mon_cluster_mode =
# 是客户端或其他 Ceph 守护程序连接到 monitor 时允许使用的模式的列表
ms_mon_service_mode =
# 一个列表,表示客户端或非 monitor 连接 montior 时使用的协议模块
ms_mon_client_mode = 从 nautilus 14.2.z 版本开始,默认会使用 v2 版本协议,但目前为止还只有很少的服务能够支持 v2 协议。
启用 v2 版本协议:
ceph mon enable-msgr2如果为想为 monitor 指定非标准端口,可使用一下命令修改:
# 需要重启服务才能开始监听新设置的端口
ceph mon set-addrs a [v2:1.2.3.4:1112,v1:1.2.3.4:1111]配置文件配置语法格式:
mon_host = 10.0.0.1:6789,10.0.0.2:6789,10.0.0.3:6789
mon_host = [v2:10.0.0.1:3300/0,v1:10.0.0.1:6789/0],[v2:10.0.0.2:3300/0,v1:10.0.0.2:6789/0],[v2:10.0.0.3:3300/0,v1:10.0.0.3:6789/0]
mon_host = 10.0.0.1,10.0.0.2,10.0.0.38.8 Bluestore 配置
8.8.1 Bulestore
Bluestore 能够管理一个或两个,甚至在有必要的情况下管理三个存储设备。在简单的使用场景中,Bluestore 使用单个存储设备,journal、metadata、data 三类数据全部存储在一个存储设备上,此设备通常在 OSD 的数据目录中表现为一个名为 block 的软链接。OSD 的数据目录使用了 tmpfs 文件系统,在系统启动时,由 ceph-volume 激活并挂载,此目录中包含了所有的 OSD 信息和文件,例如 fsid、ceph_fsid、keyring、typ 等文件。此外,Bluestore 还可以管理以下两类设备:
- WAL 设备。在 osd 数据目录中表现名为
block.wal 的软链接,用于存储 Bluestore 的内部日志 journal 和预写日志,当 WAL 设备比存储数据的设备性能更好时,使用 WAL 设备才有意义。 - DB 设备。在 osd 数据目录中表现名为
block.db 的软链接,此设备能够存储 Bluestore 内部的元数据。Bluestore (或嵌入式 RocksDB) 将尽可能多的在 DB 设备上放置更多元数据来提高性能。如果 DB 设备存储设备没有可用容量,元数据将流入主存储设备存放。仅当 DB 设备比主存储设备具有更高的性能时,使用 DB 设备才更有意义。
在仅有少量快速存储空间的情况下,建议用作 WAL 设备将更有意义,如果有更多快速存储空间,则配置 DB 设备更有意义,而 Bluestore 会始终将 journal 存储到可用的快速设备上。所以,使用 DB 设备,将等同于同时使用 WAL 设备和 DB 设备。
8.8.2 size
当我们使用混合类型的设备时,确保要给 block.db 足够大的容量。通常建议 block.db 的大小为 block 的 1% 或 4% 之间。对于 RGW 的使用场景,建议 block.db 的大小不小于 block 大小的 4%,因为 RGW 会频繁读写到元数据。对于 RBD 的使用场景,block.db 是 block 大小的 1% - 2% 通常来说是足够的。
8.8.3 自动缓存
Bluestore 能够调整自动缓存的大小,当 bluestore_cache_autotune 启动时,此选项默认是启用的。Bluestore 尝试将堆内存保持在 osd_memory_target 选项指定的大小范围内。这种算法将尽可能将缓存,同时缓存不会缩小至 osd_memory_cache_min 指定的大小。缓存比率将根据优先级层次选择,如果没有优先级信息,则会根据 bluestore_cache_meta_ratil 和 bluestore_cache_kv_ratio 指定的信息作为备选。
# 自动调整比率给不通 Bluestore,同时遵守最小的值(测试期间发现禁用缓存自动调整并手动配置BlueStore缓存选项取得了更好的结果)
bluestore_cache_autotune = true
# 当 tcmalloc 和自动缓存是启用状态时,指定在内存中的缓存大小。注意:可能与进程使用的 RSS 内存不匹配,虽然该进程映射的堆内存总量通常应保持在接近该目标的水平,但不能保证内核会真正回收未映射的内存。在最初的开发过程中,发现某些内核导致OSD的RSS内存超出映射内存达20%。但是,假设存在大量内存压力时,内核通常会更积极地回收未映射的内存。
osd_memory_target = 4294967296
# 启用缓存自动调整后,分配给缓存的块大小(以字节为单位)。当autotuner将内存分配给不同的缓存时,它将以chunk的形式分配内存
bluestore_cache_autotune_chunk_size = 33554432
# 启用高速缓存自动调节后重新平衡的的间隔。将间隔设置得太小会导致CPU使用率过高和性能下降
bluestore_cache_autotune_interval = 5
# osd内存占用的最小值,默认768M
osd_memory_base = 805306368
# 估计内存碎片的百分比,有助于 autotuner 估算总共的内存使用量
osd_memory_expected_fragmentation = 0.15
# 用于缓存的内存最小使用量。将此值设置得太低会导致高速缓存抖动
osd_memory_cache_min = 134217728
# 调整缓存大小的时间间隔
osd_memory_cache_resize_interval = 18.8.4 手动调整缓存
bluestore 存储引擎可以将 osd 的元数据、最近读取或写入的对象数据、RocksDB 的 key/value 数据缓存到内存中,缓存总量由 bluestore_cache_sieze 配置选项控制,如果其值为 0,则缓存大小由 bluestore_cache_size_ssd 和 bluestore_cache_size_hdd 选项来指定 (根据 osd 使用的数据存储设备类型进行缓存大小配置,表示 bluestore 为由 ssd 支持的 osd 缓存内存总量及有 hdd 支持的 osd 缓存内存使用量)。
# bulestore 用于缓存的总内存总量,值为0,表示根据不同类型设备的 osd 配置项指定
bluestore_cache_size = 0
bluestore_cache_size_hdd = 1GB
bluestore_cache_size_ssd = 3GB
# 推荐 kv 和 meta 比例 0.2/0.8
bluestore_cache_meta_ratio = .4
bluestore_cache_kv_ratio = .4
bluestore_cache_kv_max = 512M8.8.5 校验
Bluestore 对写入磁盘的数据和元数据进行校验和检测,元数据的写入由 RocksDB 检测并使用 crc32c 检测,写入磁盘的数据由 Bluestore 检测,使用 crc32c、xxhash32、xxhash64。默认使用的是 crc32。数据完整性检测会增加元数据的总量,进而增加 Bluestore 存储和管理的数据量,它必须为每4 KB的数据块存储一个校验和值(通常为4个字节)。可以通过使用较小的校验和值来减小元数据的存储量,但同时也会增加风险,检测不到随机错误的概率越大。通过选择 crc32c_16(2 byte) 或 crc32c_8 (1 byte)作为校验和算法,可以选择较小的校验和值。
可通过命令行对每一个 pool 进行配置:
ceph osd pool set <pool-name> csum_type <algorithm>默认校验和大小:
# 取值可以是 none, crc32c, crc32c_16, crc32c_8, xxhash32, xxhash64
bluestore_csum_type = crc32c8.8.6 内联压缩
bluestore 支持使用 snappy、zlib、lz4 对数据进行在线压缩,lz4 压缩插件未来官方打包支持。数据在 Bluestore 中是否被压缩,取决于压缩模块和写操作系相关的指定值。其中压缩模式包括:
- none:从不压缩数据
- passive:不压缩数据,除非写操作携带可压缩提示
- aggressive:压缩数据,除非写操作携带不压缩提示
- force:强制压缩数据
需要注意的是,如果通过 blustore_compression_required_ratio 指定了压缩比率,如果数据未被压缩到此比率,则 Bluestore 将存储原数据。可以通过命令行针对每个 pool 进行配置:
ceph osd pool set <pool-name> compression_algorithm <algorithm>
ceph osd pool set <pool-name> compression_mode <mode>
ceph osd pool set <pool-name> compression_required_ratio <ratio>
ceph osd pool set <pool-name> compression_min_blob_size <size>
ceph osd pool set <pool-name> compression_max_blob_size <size>配置文件配置项:
# 压缩算法,可选值为 lz4, snappy, zlib, zstd,不建议使用 zstd 压缩算法,占用 CPU 较多
bluestore compression algorithm = snappy
# 如果没有给每个 pool 设置压缩模式,则使用默认值不压缩任何数据
bluestore compression mode = none
bluestore compression required ratio = .875
# 小于此大小的块永远不会被压缩
bluestore compression min blob size = 0
# hdd 设备上数据触发压缩的最小块大小
bluestore compression min blob size hdd = 128K
bluestore compression min blob size ssd = 8K
# 大于此值的块,在压缩之前将分解为较小的块
bluestore compression max blob size = 0
bluestore compression max blob size hdd = 512K
bluestore compression max blob size ssd = 64K8.9 pool/pg/CRUSH 配置
# 每个 pool 的最大 pg 数量
mon max pool pg num = 65535
# 同一个 osd 守护进程创建 pg 的时间间隔,以秒为单位
mon pg create interval = 30
# 多少秒之后认为 pg 被 stuck
mon pg stuck threshold = 300
# 如果PG保持不活动状态的时间超过mon_pg_stuck_threshold超过此设置的时间,则在群集日志中发出HEALTH_ERR
mon pg min inactive = 1
# 如果每个(在)OSD中的PG的平均数量低于此数量,请在群集日志中发出HEALTH_WARN
mon pg warn min per osd = 30
# 如果群集中的对象总数低于此数目,则不发出警告
mon pg warn min objects = 1000
# 对象编号低于此值时,不发出警告
mon pg warn min pool objects = 1000
# 当 dowm 掉百分之多少的 osd 时,会启用检查 pg 状态
mon pg check down all threshold = 0.5
# 就是上面的存储池的平均对象与所有pg的平均值的倍数关系。((objects/pg_num) in the affected pool)/(objects/pg_num in the entire system) >= 10.0 警告就会出现
mon pg warn max object skew = 10
#
mon delta reset interval = 108.10 网络配置
Ceph 集群组网方式对集群性能至关重要,Ceph 集群不代表客户端请求数据,相反客户端直接和 OSD 进程交互,由 OSD 进程进行数据复制和读写操作。这意味着每一个 OSD 进程进行数据复制时都会在网络产生流量。默认情况下,Ceph 集群将公共一个 public network(前端网络),但由于 OSD 之间复制和数据恢复都会产生巨大的流量,因此会对性能产生巨大的影响,建议添加另外一个网络 cluster network(后端网络)。
IP及端口
默认 Ceph 集群守护进程通常会监听 6800-7300 范围内的端口。Ceph Monitor 节点监听 3300(v2) 或 6789(v1) 端口,且 Monitor 始终绑定 public network 网络。Ceph Metadata 和 Ceph Manager 、OSD 通常会从 6800 起的第一个可用端口开始监听,当在很短的时间窗口内启停进程时,其监听端口可能发生变化,从而监听到更高的端口。
OSD 监听四个端口,其中两个心跳端口,一个监听在 Public network 与 Monitor 传递心跳信息,另一个监听在 Cluster Network 与 其他 OSD 之间传递心跳信息。此外,在 Public Network 还有一个与 client 进行数据交互的端口,在 Cluster network 有一个用于 OSD 之间数据复制的端口。

配置
网络配置可在 [global] 进行配置,使用 public network = 、cluster network = 进行配置。也可以针对每个进程进行网络配置,public addr = 、cluster network = 。
# 指定 OSD 和 MDS 进程绑定的最小端口
ms bind port min = 6800
# 指定 OSD 和 MDS 进程绑定的最大端口
ms bind port max = 7300
# 是否绑定 ipv6 地址,当前 ipv4 和 ipv6 地址类型智能绑定一种
ms bind ipv6 = false9. Ceph 集群操作
9.1 低级别操作
低级别操作包括启动、停止、重启特定的守护进程;改变特定守护进程设置;添加或移除集群守护进程。
9.1.1 add/remove OSD
通常情况下,使用 cpeh-volume 等工具创建并激活 osd 时,会自动创建 uuid 和 id,但也可以手动创建 uuid 和 id,通常不推荐手动指定 uuid 和 id。 osd 的 id 值是作为数组进行分配的,在集群规模很大,或指定的 id 值很大时,可能占用更大的内存。添加 osd 可以使用手动或自动的方式进行添加。
错误提示:
--> RuntimeError: Unable to create a new OSD id可查看 keyring 是否被导入。
创建 osd :
ceph-volume --cluster test-ceph lvm prepare --bluestore --data cephh/osd15激活 osd:
ceph-volume --cluster test-ceph lvm activate {ID} {osd-uuid}删除 osd:
通过多次调整 osd weight 值,直到降到为 0 ,避免数据多次在集群中迁移:
ceph osd crush reweight osd.0 [value]将此 osd 标记为 out:
ceph osd out osd.0停止 osd 进程,告知其他 osd,此 osd 不接受服务:
systemctl stop ceph-osd@0.serviceLuminous 版本之后,以下命令可用
ceph osd purge {id} --yes-i-really-mean-it代替。
从 crush map 中删除 osd:
ceph osd crush remove osd.0删除 osd:
ceph osd rm osd.0删除认证信息:
ceph auth rm osd.0卸载 osd 的 tmpfs 分区:
umount /var/lib/ceph/osd/test-ceph-15
# 一并删除目录
rm -rf test-ceph-15清理磁盘标签信息:
ceph-volume lvm zap cephc/osd6
ceph-volume lvm zap cephg/block69.1.2 replace OSD
当有硬盘出现故障时,有可能需要替换某一个 osd 的存储设备,与删除一个 osd 不同,替换后的 osd 要求 与旧 osd 的 id 和 crushmap 保持一致。
通过多次调整 osd weight 值,直到降到为 0 ,避免数据多次在集群中迁移:
ceph osd crush reweight osd.0 [value]确保 osd 之上没有数据:
while ! ceph osd safe-to-destroy osd.{id} ; do sleep 10 ; done停止 osd 进程,告知其他 osd,此 osd 不接受服务:
systemctl stop ceph-osd@6.service销毁 osd:
ceph osd destroy {id} --yes-i-really-mean-it如果磁盘之前使用其他用户,需要清理磁盘的标签信息:
ceph-volume lvm zap cephc/osd6
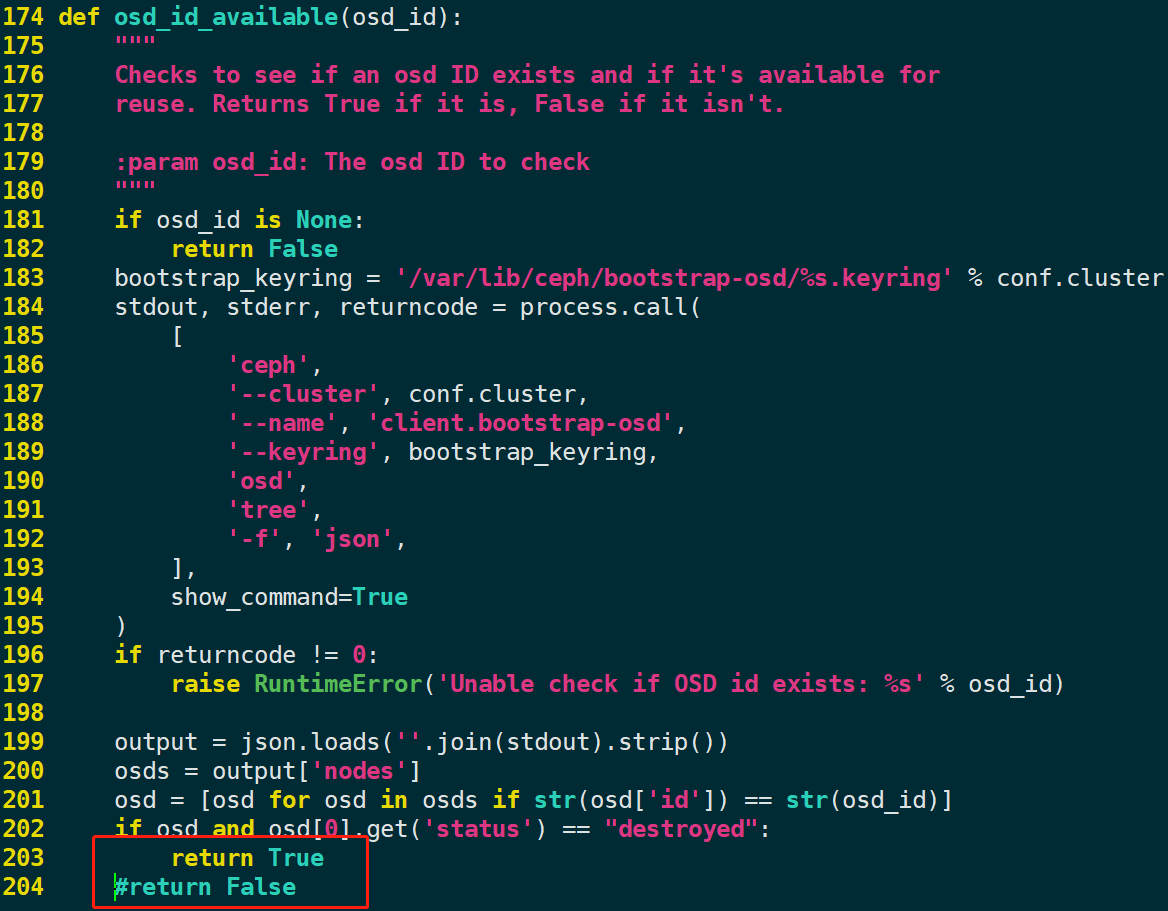
ceph-volume lvm zap cephg/block6注意:当前最新
ceph-volume版本存在一个bug,不能指定 –osd-id 值,需要简单修改源代码跳过此检测。修改
vim /usr/lib/python2.7/site-packages/ceph_volume/util/prepare.py文件:将
return False修改为return True。
准备 osd:
ceph-volume --cluste test-ceph lvm prepare --bluestore --osd-id 6 --data cephc/osd6 --block.db cephg/block6激活 osd:
ceph-volume --cluster test-ceph lvm activate 6 c597becd-4c85-4929-ac58-6d40d4740b6b或准备并激活:
ceph-volume lvm create --osd-id {id} --data /dev/sdX9.1.3 add/remove Monitor
ceph-mon 是一个轻量级进程,负责维护集群的 cluster map 的主副本。尽管一个 monitor 节点也能够使集群正常运行,但强烈建议使用 3 个 monitor 节点以保证 monitor 的冗余性。monitor 节点之间使用 Paxos 算法来保证 monitor 节点之间的信息一致性。由于 Paxos 算法的特性,ceph 需要 monitor 中的多数节点运行来达成共识。建议使用奇数个节点的 monitor,但并不是强制的。monitor 集群需要超过半数的节点正常运行才能达成仲裁,因此奇数个 monitor 节点具有更高性价比的冗余度。
注意:由于 monitor 节点是轻量级的,因此可以和 osd 节点运行于同一节点,但内核的 fsync 问题可能会造成性能下降。
创建 monitor 进程的数据目录:
mkdir /var/lib/ceph/mon/{cluster_name}-{mon_ID}创建一个临时目录,存放 key 和 monmap 文件,以下命令导出。
# 导出 key
ceph auth get mon. -o /path/to/tmp/test-ceph.mon.keyring
# 导出 monmap
ceph auth getmap -o /path/to/tmp/monmap初始化 monitor 数据目录:
ceph-mon --cluster test-ceph --mkfs -i {mon_ID} --monmap /path/to/tmp/monmap --keyring /path/to/tmp/test-ceph.mon.keyring
# 初始化完成后要确认在相应的目录下生成的数据文件最后启动 mon 进程。
从不健康的集群中删除 monitor
将说有主机上的 ceph-mon 进程停止,例如从无法达成投票结果的集群中删除某一个 monitor 。首先停止所有主机的 ceph-mon 进程。
导出 monmap 的副本:
ceph-mon --cluster test-ceph -i node1.ceph.com --extract-monmap monmap删除不健康的 monitor 节点:
monmaptool /path/to/monmap --rm {mon_id}将移除了不健康 monitor 节点的 monmap 导入正常的 monitor 节点:
ceph-mon --cluster test-ceph -i node1.ceph.com --inject-monmap /path/to/monmap注意:修改 monitor 节点数据目录的属组和属主为 ceph。
更改 moinitor IP 地址的方式有两种,修改配置文件并同步到每一个节点,还可以使用直接修改 monmap 的方式来修改。
9.1.4 命令参考 (1)
状态监控信息
ceph -s
ceph -w
# 查看ceph仲裁状态
ceph quorum_status
ceph quorum_status -f json-pretty
ceph mon_status -f json-pretty
# 查看指定某个 monitor 节点状态
ceph -m node1.ceph.com -f json-pretty mon_statuspg 统计信息
# 显示 pg 统计信息,可以指定显示格式
ceph pg dump {-format plain(default)|json|json-pretty|xml|xml-pretty}
# 显示指定状态的 pg
ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format {format}] [-t|--threshold {seconds}]
# 删除或还原某个 pg,当某个 pg 无法修复或者计划恢复到旧版本的状态
ceph pg {pgid} mark_unfound_lost revert|delete
# 显示指定类型统计信息
ceph pg dump {all|summary|sum|delta|pools|osds|pgs|pgs_brief}osd 监控相关操作
# osd 统计信息
ceph osd stat
# 导出最新的 osdmap,导出的是二进制文件,可使用 osdmaptool --print osdmap 查看文本信息
ceph osd getmap -o /path/to/file
# 等同于
ceph osd dump [--format plain|json|json-pretty|xml, and xml-pretty]
# 导出最新的 crushmap,crushtool -d crushmap -o crushmap.txt 命令可转换为文本文件
ceph osd getcrushmap -o file
# 等同于
osdmaptool /tmp/osdmap --export-crush file
# 查看某个 pool 中的对象
rados -p {Pool_Name} ls
# 查看指定某个对象和 pg 的映射关系
ceph osd map {pool-name} {Object_Name}9.1.5 进程操作
对于所有支持 systemd 的 Linux 发行版,ceph 所有守护进程都支持使用 systemd 进行管理。可以批量对所有守护进程或某类型的守护进程管理。
# 停止某个节点上所有ceph进程
systemctl start|stop|status ceph\*.service ceph\*.target
# 按照进程类型启停守护进程
systemctl start|stop|status ceph-osd.target9.2 告警信息
ceph 集群可以发出定义好的错误警告信息,以便于运维人员排查故障。
a). Monitor 告警信息
MON_DOWN
一个或多个 ceph-mon 进程停止,集群中必须要有超过半数的 monitor 节点正常运行才能正常提供服务。如果有 monitor 节点宕机,大多数情况下,集群依旧可以正常提供服务,但客户端可能需要消耗更多的时间去尝试连接正常的 monitor。当出现 monitor 出现故障时,应引起足够的重视,立即去排查。
MON_CLOCK_SKEW
Monitor 之间时间同步出现偏差,应该尽可能的使用时间同步服务器同步节点之间的时间。或配置mon_clock_drift_allowed增加时间偏差的容忍度。注意:此值必须小于mon_lease的值,集群才能正常运行。MON_MSGR2_NOT_ENABLED
ms_bind_msgr2选项开启,但有一个或多个 monitor 在 cluster map 中未配置绑定 msg2 协议的端口。可使用ceph mon enable-msgr2命令启用 v2 协议的功能支持,此命令会改变所有 monitor 的监听端口,修改后为 monitor 会同时监听 v1 版本的 6789 端口和 v2 版本的 3300 端口。注意:如果 v1 版本的协议监听的不是默认的 6789 端口,MON_DISK_LOW
一个或多个 Monitor 节点的磁盘空余容量低时会发出此警告。当 Monitor 几点的 /var/lib/ceph/mon 目录所在的文件系统磁盘空余空间低于mon_data_avail_warn指定的值时会触发此警告,默认值是 30%。MON_DISK_BIG
如果 Monitor 的数据库大小超过mon_data_size_warn指定的大小时会触发此警告,默认为 15G。当某些 pg 长时间没有达到 active-clean 状态时,Monitor 数据库可能会增加。
b). Manager 告警信息
- MGR_DOWN
所有的 ceph-mgr 节点全部 down 掉时会触发此告警。如果集群中没有正常运行的 ceph-mgr 进程,集群在对自身的监控功能会大大降低。此外,ceph-mgr 提供的 API 也将变的不可用,例如 dashboard、CLI 命令返回的指标数据等。但集群仍然将正常运行,提供正常的 I/O 请求和故障恢复。- MGR_MODULE_DEPENDENCY
如果 mgr 的模块启用时依赖检测失败,会触发此告警信息,此外还会附带额外的关于模块的错误信息。- MGR_MODULE_ERROR
mgr 模块遇到意外错误。可以尝试重启 ceph-mgr 进程或执行ceph mgr fail来手动执行故障转移。
c). OSDs 告警信息
OSD_DOWN
1、一个或多个 cpeh-osd 进程停止 2、osd 网络通信问题 3、主机故障OSD_
_DOWN
在 CRUSH 上一个 subtree 的所有 osd 全部停止,例如:OSD_HOST_DOWN, OSD_ROOT_DOWNOSD_OUT_OF_ORDER_FULL
当以下指标超过指定的阈值时,会发出此警告。mon_osd_full_ratio、mon_osd_nearfull_ratio、mon_osd_backfillfull_ratio、osd_failsafe_full_ratio通常的配置规则为:nearfull < backfillfull、backfillful < full、full < failsafe_full
OSD_ORPHAN
osd 在 CRUSH 的 subtree 中被映射,但 osd 并不存在。可以手动从 CRUSH 中删除 osd。ceph osd crush rm osd.<id>OSD_OUT_OF_ORDER_FULL
当配置的阈值不符合 nearfull < backfillfull、backfillful < full、full < failsafe_full 规则时,会触发此告警。ceph osd set-nearfull-ratio <ratio> ceph osd set-backfillfull-ratio <ratio> ceph osd set-full-ratio <ratio>OSD_FULL
一个或多个 osd 磁盘容量使用率超过了 full 指定的阈值。可使用ceph df查看磁盘使用量。OSD_BACKFILLFULL
一个或多个 osd 磁盘容量使用率 backfillfull 指定的阈值,阻止数据重新平衡到该 osd 对应的设备上。OSD_NEARFULL
一个或多个 osd 超过了 nearfull 指定的阈值。OSDSNAP_FLAGS
表示集群被标记了一个多个 flag,可以使用ceph osd set|unset <flag>命令进行标记或取消标记,这些 flag 包括以及 flag 会导致的表现如下:
full: 标记集群 full 状态,停止写入操作。
pauserd: 已暂停,停止读取和写入。
noup: 不允许 osd 启动。
nodown: 即便 osd 失败,monitor 也不报告 osd 的状态。
noin: 以前标记为 out 的 osd 当启动时不会被自动标记为 in。
noout: 当 osd down 之后不会被自动标记为 down。
nobackfill、norecover、norebalance: 停止数据平衡和回填。
noscrub、nodeep_scrub: 停止数据清洗。
notieragent: 暂停缓存分层的使用。OSD_FLAGS
一个或多个 osd 或 CRUSH 中的 subtree 被标记,这些标记及其含义包括:noup: 不允许 osd 进程启动。nodown: osd down 的状态被忽略。noin: 如果 osd 被自动标识为 out 时,当 osd 再次被启动时不标记为 in。noout: 如果 osd 被自动标记为 down 时,osd 不会被标记为 out。
使用方法:ceph osd set-group <flags> <who> ceph osd unset-group <flags> <who> # 示例 ceph osd set-group noup,noout osd.0 osd.1 ceph osd unset-group noup,noout osd.0 osd.1 ceph osd set-group noup,noout host-foo ceph osd unset-group noup,noout host-foo ceph osd set-group noup,noout class-hdd ceph osd unset-group noup,noout class-hddOLD_CRUSH_TUNABLES
当 CRUSH map 中使用了旧版本的配置项,如果需要禁止触发此告警,可以使用mon_crush_min_required_version选项配置。OLD_CRUSH_STRAW_CALC_VERSION
CRUSH 中使用的旧的非最佳的方法计算 straw bucket 的中间权重值。可使用straw_calc_version=1进行相关配置。CACHE_POOL_NO_HIT_SET
一个或多个缓存 pool 未开启命中(hit)集来跟踪数据利用率,这将防止缓存代理识别冷数据对象并将之逐出缓存层。
OSD_NO_SORTBITWISE
内部排序算法,兼容 per-jewel 版本,再新版本中是开启状态。表示对象在 osd 中按位进行排序。POOL_FULL
一个或多个 pool 达到了存储配额且不允许写入数据。
# 查看容量使用情况 ceph df detail # 设置 pool 配额 ceph osd pool set-quota <poolname> max_objects <num-objects> ceph osd pool set-quota <poolname> max_bytes <num-bytes>BLUEFS_SPILLOVER
一个或多个 osd 使用 bluestore 后端存储时,db 分区已经被元数据写满,元数据溢出到慢速设备上。这个告警并不意味着集群出现故障,甚至可以忽略,但在慢速设备上影响 ceph 集群整体性能。
# 关闭告警 ceph config set osd bluestore_warn_on_bluefs_spillover false # 在特定 OSD 上禁用此告警 ceph config set osd.X bluestore_warn_on_bluefs_spillover false可以通过销毁 osd 或重置 osd 来重新规划 db 和 wal 的逻辑卷,也可以将 db 和 wal 使用的逻辑卷进行扩展,扩展前需要停止 osd,然后扩展逻辑卷,扩展之后通过以下方式让 BlueFS 得知设备大小发生改变:
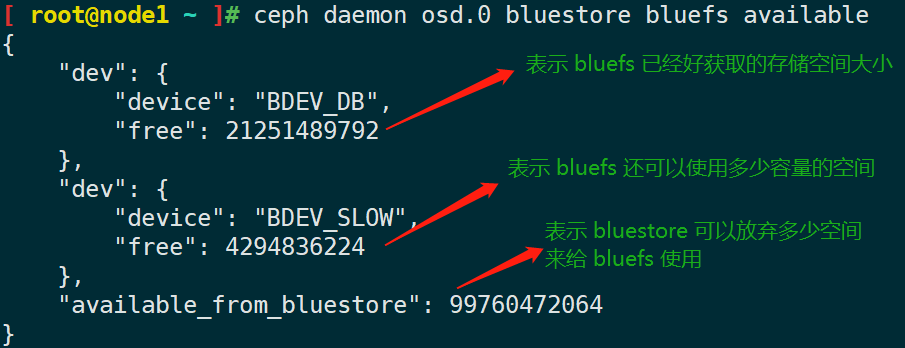
ceph-bluestore-tool BlueFS-bdev-expand --path /var/lib/ceph/osd/ceph-$IDBLUEFS_AVAILABLE_SPACE
查看 bluestore 存储引擎使用的 db 和 wal 设备使用量。
# 三种方式查看 # nautilus 版本起可以使用 ceph daemon osd.X bluestore bluefs available ceph daemon osd.x perf dump ceph osd metadata osd.X
available_from_bluestore的值通常和 bluestore 可用空间不同,因为 BlueFS 分配单位比 bluestore 的分配单位大。BLUEFS_LOW_SPACE
如果BlueFS的可用空间不足,并且
available_from_bluestore很少,则可以考虑减小 BlueFS 分配单元的大小,要模拟分配单位不同时的可用空间,请执行以下操作:ceph daemon osd.X bluestore bluefs available <alloc-unit-size>BLUESTORE_FRAGMENTATION
bluestore 后端存储时间久之后,会造成存储空间碎片化严重,这是正常的也是难以避免的。碎片化会导致性能的下降。可以使用一下命令查看碎片化程度进行一个评估:
# 检查运行状态中的 osd 存储后端碎片化程度 ceph daemon osd.X bluestore allocator score block # 检查未运行状态的 osd 存储后端碎片化程度 ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-X --allocator block free-score评估得分范围在 [0-1] 之间,[0-0.4] 意味着碎片化程度为微小,[0.4-0.7] 意味着碎片化程度为小,[0.7-0.9] 意味着碎片化程度为大,[0.9-1.0] 意味着碎片化程度比较严重,可能会影响到 BlueFS 的从 BlueStore 中获取免费存储空间的能力。
BLUESTORE_LEGACY_STATFS
在 Nautilus 版本中,BlueStore 会跟踪内部每个 Pool 的使用信息统计,如果 osd 版本使用 Nautilus 之前的版本,则针对每个 Pool 的统计信息不可用。如果混合版本使用 osd,则统计信息可能不准确。如果混合版本使用 osd,则可以通过停止 osd 将旧的 osd 更新为使用新方案的跟踪统计方案。# 替换跟踪统计方案 systemctl stop ceph-osd@X ceph-bluestore-tool repair --path /var/lib/ceph/osd/ceph-X systemctl start ceph-osd@X # 关闭此告警提示 ceph config set global bluestore_warn_on_legacy_statfs falseBLUESTORE_DISK_SIZE_MISMATCH
物理设备的大小与跟踪其大小的元数据之间存在内部不一致,这可能会导致 osd 奔溃。可销毁此 osd 进行重建。注:进行 osd 销毁时应格外小心。
ceph osd out osd.$N while ! ceph osd safe-to-destroy osd.$N ; do sleep 1m ; done ceph osd destroy osd.$N ceph-volume lvm zap /path/to/device ceph-volume lvm create --osd-id $N --data /path/to/deviceBLUESTORE_NO_COMPRESSION
一个或多个 OSD 无法加载 BlueStore 压缩插件,可能 ceph-osd 程序与压缩插件不兼容或升级导致。
d). Pool & PG 状态告警信息
PG_AVAILABILITY
数据可用性降级,意味着集群可能对于某些数据的读写请求不发响应。特别是一个或多个 PG 不能提供正常的 I/O 请求。PG 的不可用状态包括
peering、incomplete等。# 查看不正常的 pg ceph health detail # 查询特定 pg 的信息 ceph tell <pgid> queryPG_DEGRADED
一些数据的冗余度降低,意味着集群内的副本场景的副本数量、纠删码的数据块的数量没有达到期望的状态。
PG_RECOVERY_FULL
数据冗余度降低,由于可用空间不足导致数据风险。如果有一个或多个 pg 出现 PG_RECOVERY_FULL 标记,意味着集群不能够迁移或恢复数据,因为有 osd 的使用量达到了 full 指定的阈值。
PG_BACKFILL_FULL
PG_DAMAGED
在 scrub 的过程中发现数据不一致性问题。
OSD_SCRUB_ERRORS
osd scrub 时发现数据不一致问题。
LARGE_OMAP_OBJECTS
一个或多个 pool 中包含了大型 omap 对象。omap 是一个 key-value 数据库,每个对象都可能有自己的数据库。这个数据库允许去插入、更新、插入、查询操作。这个数据库可能是任意大的,但过大的 omap 会导致集群告警。omap 数据库是附加的对象数据,并在 osd 之间以副本的方式复制。当有用户请求查询此数据库时,会直接将请求定位到 primary osd 之上,然后主 osd 会使用 RocksDB 查询并给用户返回请求。RGW 是使用 omap 最频繁的,因为 RGW bucket 利用 omap 来存储索引,会出现数据非常小,但 omap 却非常大的现象。大型 omap 对象可能由未启用自动重新分片的 RGW 存储桶索引对象引起。
# 可通过命令压缩 omap ceph tell osd.X|osd.* compact # 设置 omap key 的数量阈值 ceph config set osd osd_deep_scrub_large_omap_object_key_threshold <keys> # 设置 omap 的总字节数阈值 ceph config set osd osd_deep_scrub_large_omap_object_value_sum_threshold <bytes>CACHE_POOL_NEAR_FUILL
缓存 pool 存储容量容量接近耗尽。从缓存中清除数据时,对池的写入请求可能会阻塞,这种状态通常会导致很高的延迟和较差的性能。
# 缓存 pool 最大字节数阈 ceph osd pool set <cache-pool-name> target_max_bytes <bytes> # 缓存 pool 最大对象数量阈值 ceph osd pool set <cache-pool-name> target_max_objects <objects>
TOO_FEW_PGS
集群中的 PG 的数量低于每个 OSD的 mon_pg_warn_min_per_osd PG 配置的阈值。PG 数量过少会影响数据分发和整体性能。
POOL_PG_NUM_NOT_POWER_OF_TWO
Pool 的 PG 数量不是二的幂次方。
# 调整 PG 数量 ceph osd pool set <pool-name> pg_num <value> # 关闭此告警信息 ceph config set global mon_warn_on_pool_pg_num_not_power_of_two falsePOOL_TOO_FEW_PGS / POOL_TOO_MANY_PGS
一个或多个 Pool 中的 PG 数量过多,这可能导致分发数据不平衡,并可能降低集群整体性能。
# 如果 pg_autoscale_mode 属性开启,则可能会生成此告警 ceph osd pool set <pool-name> pg_autoscale_mode off # 开启 PG 自动自动调整,但可以通过手动的方式设置 PG 数量 ceph osd pool set <pool-name> pg_autoscale_mode onTOO_MANY_PGS
集群中的 PG 数量高于
mon_max_pg_per_osd指定的阈值。如果超过此值,则集群将不允许创建新的 Pool,PG 数量过多,可能导致主机内存使用量过多。POOL_TARGET_SIZE_BYTES_OVERCOMMITTED
当新建一个 Pool 后,将消耗集群少量的容量,尽管有这些干扰因素,但在创建集群时,通常会较为准确的估计数据存储量,避免后期 PG 数量的变化导致大量数据迁移。配置 Pool 预期数据的存储量,有两种方式,配置预期存储容量大小,配置相对于其他 Pool 相对其他 Pool 的权重(所有 Pool 预期存储容量的比,此处设置的 ratio 为此 Pool 所占的比例)。
ceph osd pool set <pool-name> target_size_bytes 100T ceph osd pool set <pool-name> target_size_ratio 1.0也可以在创建池时指定预期容量,
--target-size-bytes或--target-size-ratio。如果指定的容量或比例超过实际容量,则会发出此告警信息。POOL_HAS_TARGET_SIZE_BTYES_AND_RATIO
bytes 和 ratio 两个配置参数同时只能配置一个,如果同时配置两个值,则会发出此告警信息。
ceph osd pool set <pool-name> target_size_bytes 0 ceph osd pool set <pool-name> target_size_ratio 0TOO_FEW_OSDS
OSD 数量小于
osd_pool_default_size指定的副本数量。SMALLER_PGP_NUM
Pool 设置的 pgp_num 小于 pg_num。通常 pg_num 等于 pgp_num 数量。
ceph osd pool set <pool-name> pgp_num <pg-num-value>MANY_OBJECTS_PER_PG
Pool 中的每个 PG 包含的对象数量平均值是明显超过了集群总体的平均值。阈值的配置由
mon_pg_warn_max_object_skew配置参数设定。这表明集群中有的 Pools 中包含了过多数据但 PGs 数量很少,有的 Pools 中包含了很少的数据但 PGs 数量很多。POOOL_APP_NOT_ENABLED
Pool 存在但没有被标记哪些应用程序使用该 Pool。
# 如果该 Pool 通过 RBD 来使用 rbd pool init <pool-name> # 如果该 Pool 被自定义程序使用,则自定义标记 ceph osd pool application enable <application-name>POOL_FULL
如果 Pool 数据存储量达到了指定的配额,会触发此告警信息。此告警出发的阈值由
mon_pool_quota_crit_theresshold配置。# Pool 存储配额配置,0 表示不限制 ceph osd pool set-quota <pool-name> max_bytes <bytes> ceph osd pool set-quota <pool-name> max_objects <objects>POOL_NEAR_FULL
如果 Pool 数据存储量快要达到阈值时,会触发此告警信息。此告警出发的阈值由
mon_pool_quota_warn_threshold配置。OBJECT_MISPLACED
集群中存储的对象错位,即 object 未存储在集群期望存储的节点上。表示集群在最近的变化时,有些数据未完成迁移。错位的数据并不意味着数据本身存在问题。
OBJECT_UNFOUND
在集群内存在 object 不存在的现象。OSDs 知道新添加或更新后的对象存在,但是在当前在线的 OSDs 上未能找到对象副本的版本。对于此 object 的读写请求将被阻塞。理想情况下,下线的 OSDs 重新上线可以恢复处于 UNFOND 状态的对象的副本。
SLOW_OPS
OSDs 接受请求处理需要很长时间,这可能意味着性能不足的。
# 查看 OSDs 的 OPS ceph daemon osd.<id> ops # 查看最近慢请求的信息 ceph daemon osd.<id> dump_historic_ops # 查找 OSDs 的位置 ceph osd find osd.<id>PG_NOT_SCRUBBED
PGs 最近没有被清洗。PGs 的清洗时间间隔使用
mon_scrub_interval来配置,mon_warn_not_scrubbed_ratio配置参数表示清洗到期之后,已经超过时间间隔百分之多少之后还未开始清洗。如果 PGs 未在指定时间间隔内清洗,则 PGs 不会被标记为 clean。# 手动清洗 PGs ceph pg scrub <pgid>PG_SLOW_SNAP_TRIMMING
PGs 在修剪其快照的过程中队列超过配置指定的阈值会触发此告警信息。这可能是删除大量快照导致,OSDs 不能足够快速的修剪快照,这个速度慢于删除快照的速度。该告警信息的阈值由
mon_osd_snap_trim_queue_warn_on配置。此外触发此告警信息的原因还有:1、如果 OSDs 负载过高无法处理过多的请求。 2、OSDs 内部元数据碎片过多,严重分散。3、OSDs 存在其他性能瓶颈。OSDs 的队列信息可使用pg ls -f pretty-json命令查看snaptrimq_len字段查看。
e). 其他告警信息
RECENT_CRASH
在 Ceph 集群中存在故障停止的进程时会发出此告警信息,这可能是软件 bug 或硬件故障问题导致。
# 查看故障停止的服务列表 ceph crash ls-new # 检查指定奔溃进程的信息 ceph crash info <crash-id> # 通过存档的方式消除此告警信息 ceph crash archive <crash-id> # 存档所有故障服务 ceph crash archive-all“最近” 的周期使用
mgr/crash/warn_recent_interval选项配置。(即最近多长时间的故障停止的信息才会发出告警信息,默认为 2 周)# 0 表示禁用告警信息 ceph config set mgr/crash/warn_recent_interval 0AUTH_BAD_CAPS
存在 monitor 不能够解析用户权限的用户,通常可能是用户没有授权对任何进程的操作权限。还有可能发生在升级操作导致新版本的认证与旧版本不兼容。
# 删除用户或更新用户权限 ceph auth rm <entity-name> ceph auth <entity-name> <daemon-type> <caps> [<daemon-type> <caps> ...]TELEMETRY_CHANGED
telemetry(状态监测信息报告)功能启用,但要监测到的报告内容发生变化,Ceph 开发人员会定期修改遥测功能的有用信息。telemetry 功能会定期将集群整体简要信息 (池配置信息,节点 和 OSD 数量,以及 Ceph,OS,内核版本) 发送给 Ceph 项目。# 启用 telemtry 功能模块 ceph mgr module enable telemetry # 重新启用 telemetry 功能会消除告警信息 ceph telemetry on # 禁用 telemetry 功能 ceph telemetry offOSD_NO_DOWN_OUT_INTERVAL
mon_osd_down_out_interval配置选项值为 0 时,OSDs 失败后将不会自动执行任何修复或恢复操作。需要管理员手动标记 OSDs 为 ‘out’ 状态以触发恢复。通常需要重启服务器时,可事先设置此选项。# 禁用此告警信息 ceph config global mon mon_warn_on_osd_down_out_interval_zero false
9.3 集群监控
监控个集群的状态通常涉及 OSDs、monitor、PGs、metadata服务的状态信息。在节点之上监控 Ceph 集群的状态有两种方式,第一种是使用 ceph 程序自带的命令行,第二种是在 Linux 系统的命令行传递参数给 ceph 程序的方式。
# 检查集群状态
ceph status
ceph -s
# 查看 pool 读写 IO
ceph osd pool statsCeph 集群如何计算数据使用量?
ceph -s 命令显示的
usage: xxGiB user表示数据实际占用的容量,不包括副本、快照、克隆占用的空间。x.x / x.x TiB avail表示存储设备实际被占用的空间和存储设备总容量,包括副本、快照、克隆占用的容量。
除了各类守护进程的本地日志之外,集群还维持一个集群日志用来记录集群重要事件。默认情况下,此文件保存在 /var/log/ceph/{cluster-name}.log 文件中,同时也可以从命令行实时监控记录到此文件中的事件的变化。
ceph -w
# 此外还可以查看集群日志最近的 n 行
ceph log last <n-line>ceph df 命令显示结果解析?
RAW STORAGE: 部分
CLASS:设备类型,SSD、HDD。
SIZE:集群总计管理的存储容量,即磁盘总容量。
AVAIL:集群剩余可用裸容量。
USED:用户存储的数据总大小(包括副本等)。
RAW USED:用户总计使用的存储容量的原始大小,包括内部消耗和保留容量,通常和 USED 大小相似 ,略比 USED 大。
%RAW USER:已使用裸容量的比例。此数值和
full ratio和near full关联。POOLS: 部分 注:本部分不显示数据副本、克隆、快照等。
STORED:表示存储的数据本身大小,不包括副本、快照、克隆等。
OBJECTS:Pool 中存放的对象数。
USED:表示存储的数据本身大小,包括副本、快照、克隆等。
%USED:每个 Pool 使用总存储的百分比。
MAX AVAIL:Pool 可使用的最大存储空间大小。
OSDs 状态监控
ceph osd stat
ceph osd dump
ceph osd treemonitor 状态监控
ceph df stat
ceph mon dump
ceph quorum_status
ceph quorum_status -f json-prettyMDS 状态监控
ceph mds stat
ceph fs dump使用套接字管理
ceph daemon {daemon-name} help9.4 数据平衡
由于 CRUSH 算法使用伪随机函数有其本身的缺陷,进而导致 PG 分布不均匀的情况,尤其在小规模集群中 PG 不均衡导致的问题更为严重。目前 ceph 集群中可使用的平衡 PG 的方式有 reweight、upmap 、reweight-set 、balancer 这四种方式,这四种方式互相关联,例如 balancer 模块事实上使用的是 upmap、reweight-set 的机制,只是可以自动进行平衡 PG 的分布。在 CRUSH 算法分布数据时,会将元素 “磁盘/OSD” 比作 “签” ,首先计算签长,签长的将被选中放置数据 (每个元素被选中的概率趋于相同),签长的计算被 weight 和 reweight 两个值影响,进而影响到数据的分布。在执行数据平衡之前,需要了解几个名词的区别。
- weight:一个反映存储能力的属性,反映磁盘真实容量,可使用
ceph osd crush reweight <osd.id> <val>命令进行调整,尽管使用这种方式一定意义上也可以实现 PG 的平衡分布,但会损失存储容量不建议使用。( 例如磁盘容量为 5.43 TiB,则其 weight 为 5.43)。当我们要将 OSD 踢出集群时,可以多次小幅度调整此值,使数据迁移到其他 OSD 之后,删除此 OSD。- reweight:ceph 引入的一个迁移比重概念,用于调整数据平衡,范围是 [0-1] 。在分发数据时,每个 OSD 在被 CRUSH 算法选择时都会利用 rewight 进行负载测试,测试通过则被选中,通过增加这样一个步骤来影响 PG 的分布。rewieight 可以认为是一个临时生效的值,当 OSD 被 out 后再次加入集群后,其 reweight 值将被重置为 1。
9.4.1 balancer
由 ceph-mgr 托管的模块 balancer 能够自动调整 PGs 在 OSDs 之上的分布,以实现 PGs 的分布平衡。
# 启用模块
ceph mgr module enable balancer
# 查看 balancer 状态
ceph balancer status
# 启用|停止, balancer 默认使用 crush-compat 模式。
ceph balancer on|off
当集群处于降级状态,balancer 模块会停止 PGs 的重新分布。当集群在健康状态时,balancer 也会抑制平衡时迁移过多的 PGs 的数量。默认移动 PGs 的百分比阈值为 5%,也可进行配置。
ceph config set mgr mgr/balancer/max_misplaced .07当前支持两个平衡模式:分别为
crush-compat和upmap模式。
crush-compat:crush-compat 模式利用了 weight-set 特性(从 Luminous 引入)管理在 CRUSH 层级结构中设备的权重。通常某个设备或 CRUSH 中的层级的 weight 的值表示其设备可存储的容量总数(换算为 1TiB = 1 weight) ,以让 weight 值反映可在其设备上可存储的数据总量。balancer 模块就是通过优化调整此数值,并采用小幅度的向下或向上调整的策略,以达到理想的平衡分布状态。弊端:如果 CRUSH 层级结构复杂,有不同的规则使用相同的设备时,balancer 无法处理这种场景的数据平衡。当 OSDmap 和 CRUSH map 被旧客户端共享时,优化的权重将使用 “real” 表示。
upmap: 从 Luminous 版本之后,通过 PG 重映射的方式以提供更细粒度的控制。此模式通过优化 PG 的分布,实现更好的数据平衡。通俗的讲就是通过将 PG 移动到特定的 OSDs 之上,达到 PGs 分布平衡。开启此模式需要配置:ceph osd set-require-min-compat-client luminous。
# 切换平衡模式
ceph balancer mode upmap|crush-compat
# 查看当前集群数据分布情况,得分越低,平衡越好
ceph balancer eval {pool-name}
# 查看分布情况详情
ceph balancer eval-verbose {pool-name}
# 查看 balancer相关配置
ceph config-key dump
# 根据当前配置模式生成一个平衡计划
ceph balancer optimize {plan-name} <plan> {<pools> [<pools>...]}
# 管理某个平衡计划
ceph balancer ls|show|rm {plan-name}
# 计算某个计算执行后的预期得分
ceph balancer eval {plan-name}
# 执行平衡计划
cephbalancer execte {plan-name}注意:balancer 如果设置
ceph balancer on,则表示自动进行平衡,系统默认每分钟计算一次得分,如果可优化,则进行平衡操作。
9.4.2 upmap
从 luminous v12.2.z 版本中,在 OSDMap 中允许添加了一个新的 pg-upmap 列表,该表显式的表示了将特定 PG 映射到特定 OSDs(通常在使用 upmap 方式调整 PG 分布后,会在 OSDMap 中添加此列表,可使用 ceph osd dump 命令查看)。通过 upmap 的方式可以实现 PG 在 OSD 之间的完美分布。
注意:1、OSDMap 中的 pg-upmap 列表只能够被
luminous及之后版本的客户端识别。可使用ceph features命令查看客户端版本。2、mgr 中balancer模块的 upmap 模式也是使用此种方式自动调整。3、upmap 的方式可实现在线平衡调整。4、建议分别对每个 pool 进行优化,或者对一组属性及使用场景(一组使用相同设备且存储数据类型相似的 pool)类似的 pool 进行同时优化。5、 upmap 事实上使用的是 PG Temp 机制,有兴趣可进行深入了解。
# 获取当前 osdmap
ceph osd getmap -o {osdmap_file_name}
# 获取平衡方案
# --upmap-pool <poolname> 表示限定平衡指定 pool 的 PGs 分布
# --upmap-deviation <max-deviation> 表示与 PG 在每个 OSD 分布平均值的偏差值,默认为 5
# --upmap-max <max-count> 表示允许调整的最大的 PG 数量,默认为 10,当离线调整时应尽可能使用较大数量的 PG 调整
# --upmap <optimization-file> 指定生成的优化方案文件
# --upmap-active 表示不断轮询生成优化方案,直到达到完美分布为止
# --debug-osd 10 / --debug-crush 10 可显示更多的详细信息,观察具体优化工作细节
# 示例。生成有优化方案文件
osdmaptool om --upmap out.txt --upmap-pool vmdata-rbd --upmap-max 100 --upmap-deviation 1
# 执行优化方案
source out.txt
# 删除 pg-upmap-items
ceph osd rm-pg-upmap-items <pgid>9.4.3 reweight
也称为 osd reweight,CRUSH 在映射 PGs 到 OSDs 时会根据 OSDs 的权重进行映射,磁盘的存量容量直接反映了OSDs 的权重 weight 。平衡 PGs 时,不便于对 weight 进行直接更改,因此引入另一个概念 reweight,被称为 “迁移权重”。此种方法由于需要重复多次试错调整每个 OSD 的权重,迁出或迁入 PG 来达到分布平衡,这种方式会导致数据重复迁移。
# 调整单个 OSD 的 reweight。reweight 取值范围为 [0-1]
ceph osd reweight {osd_num} {reweight}
# 批量调整 reweight
'''
# overload 表示只有当某个 OSD 空间使用率大于 overload/100 时,才调整 reweight;max_change 表示调整 reweight 的最大幅度,[0-1]之间,默认为 0.05;
max_osd 默认为 4,表示单词调整 OSD 的个数;
--no-increasing 表示不允许 reweight 上调。
'''
ceph osd test-reweight-by-utilization|test-reweight-by-pg {overload} {max_change} {max_osds} {--no-increasing}9.4.4 weight-set
weight-set 是另外一种计算数据放置时使用的一种权重,与 rewight 作用于每一个 OSD 不同,weight-set 还可以作用与集群中的 Pool。weight-set 有兼容模式和非兼容模式两种,兼容模式可以兼容各版本客户端。当调整 weight-set 时,值的变化会表现在 ceph osd crush tree 显示的 (compat) 字段值,生成的 weight-set 信息会保存在 CRUSH map 中。和 weight 同样存在无法精确控制的问题,因此在生产环境中不存在兼容客户端的问题的情况下尽可能使用 balancer 模块自动平衡或使用 upmap 的方式来平衡 PG 的分布。
# 创建 weight-set(兼容模式)
ceph osd crush weight-set create-compat
# 调整 item weight
ceph osd crush weight-set reweight-compat {item} {weight}
# 删除 weight-set,(PG 会恢复到原来未平衡之前的状态)
ceph osd crush weight-set rm-compat9.5 CRUSH Maps
Ceph 通过使用 CRUSH 算法计算出数据存储位置然后确定数据存储及检索的位置。
9.6 OSDs 和 PGs 状态
对硬件或软件的容错能力是高可用和高可靠性的基础,Ceph 集群没有单点故障,即便在故障的情况下,集群以降级 (degraded) 的状态运行仍能够提供正常服务。在 Ceph 集群中,对用户呈现的视角并不是将数据直接放置在某个 OSD 的磁盘下,而是引入了 Pool 这样的中间层。因此,对于定位故障应该将视角放到 PG 和 OSD 的层面。
注:通常某一些故障影响的范围是局部的,如果某个 OSD 或 PG 发生故障或某个节点发生故障,通常集群会进入降级状态,但依然可以提供正常服务。有些情况可能只是影响到某一部分数据的访问。
9.6.1 OSDs 监控
OSD 的状态包括四种 in、out、up、down 。其中 in 和 out 表示 OSD 是否在集群中,up 和 down 表示 OSD 进程是否正常运行。当一个 OSD 为 up 状态时,其有可能是为 in 状态且可接受数据读写,也有可能是 out 状态。当 OSD 被标记为 out 时, CRUSH 不会将 PG 分派给此 OSD,意味着此 OSD 暂时停止在集群内为客户端提供读写请求,同时会触发 recovery,将此 OSD 上的数据迁移到其他 OSD 之上,如果数据恢复流量很大,可手动标记 OSD noout,避免数据迁移造成网络负载过大。如果 OSD 处于 down 状态,此时集群(PG)处于降级状态,OSD 合理的状态应该是 out,应尽快使数据恢复,避免二次故障造成数据丢失,因此我们应尽可能的避免 OSD 为 in 且 down 的状态 ,或者在 down 状态下标记 OSD 为 noout,事实上当 OSD down 的时间将超过 600s 时,会被自动标记为 out,并触发 recovery,将此 OSD 数据迁移至其他 OSD。
总结
- 如果 OSD 为 down 且 in 状态,故障波及范围内的数据将会停止读写操作,是一个非常严重的问题。因此在发现有 OSD 为 down 状态,在确定是一个临时性的故障时,可以在短时间内恢复,可标记此 OSD 为 noout,以免 OSD 超时被自动 out ,引起数据迁移。
- OSD 在未被删除并踢出集群的情况下,CRUSH Map 和 OSD Map 中都会保留其条目。
- 当有大范围的 OSD 处于 down 状态时,在确认剩余 OSD 可保证集群正常的情况下,即可确保是临时性故障时,可手动执行 noout 标记 OSD,避免数据的大量迁移。
- 当 OSD 大面积故障,且无法触发并完成数据迁移恢复时,集群中某些数据请求将会被阻塞掉,告警信息表现为
slow requests。- 执行
ceph osd stat命令查看当前集群中 up、in 状态的 OSD,如果 in 大于 up 数量,则表示有 OSD 处于 down 状态。- 当 OSD 大面积故障被标记为 down 状态时,moinitor 并不会将自动将所有故障 OSD 标记为 out,因为如果大量 OSD 被标记为 down 则可能会引起数据迁移风暴。moinitor 仅仅会将合适数量的 OSD 标记为 out。在这种情况下转移 OSD 的数量由由配置参数
mon_osd_down_out_subtree_limit决定。
9.6.2 PG 监控
当 CRUSH 算法在将 PG 放置到 OSD 上时,会将每个 PG 不同的副本放置到不同的 OSD 上。同时,CRUSH 算法会根据故障域的配置,把 PG 不同副本放置到不同故障域的 OSD 上。例如,在故障域为 host 的集群中,ceph CRUSH 算法会将 PG 的不同副本分发到不同 host 的 OSD 上。我们通常将放置同一个 PG 的三个副本的一组 OSD 称为 Acting Set。此外,称处理 client 读写请求的一组 PG 为 Up Set。通常情况下 Acting Set 和 Up Set 相同,否则集群可能正在迁移数据、OSD recovering 或集群可能存在其他潜在问题。
# 查看 PG 详细状态
# -f|--format {json,json-pretty,xml,xml-pretty,plain}
ceph pg dump
# 查看某个 PG 的 Acting set 和 Up Set
ceph pg map {pg_id}peering
在将数据写入 PG 之前,PG 的状态必须是 active 状态,且应该是 clean 状态。在实测过程中,一组 Up Set 的 OSD 的处于 Down 时,尽管某些情况下可以将数据写入集群,部分 PG 处于 no active 的状态,但此时依然非常危险,应尽快将故障 OSD 恢复将踢出集群。为了确认 PG 的状态,primary OSD 会和 secondary OSD、tertiary OSD 发出 Peer 请求,以对 PG 的状态达成一致。
9.6.3 PG 状态监控
以下情况都有可能使 PG 不处于 active+clean 状态,(在很多场景下,集群将自动恢复到 HEALTH_OK 的状态):
- 刚创建一个 pool,PG 还没有 map 完成。
- PG 正在 recovering。
- 添加或删除 OSD。
- 修改 CRUSH 。
- PG 的不同副本之间数据不一致。
- PG 处于 scrub 状态。
- 集群没有足够的可用存储空间完成 backfiiing。
此外 PG 可能处于 unclean PG 副本数未达到指定数量;inactive PG 无法处理数据的读写请求;stale PG 所在的 OSD 在指定时间内没有和 monitor 报告自身状态统计信息。
# 查看 PG 状态的统计信息 (同时返回当前数据总量、剩余存储容量、总容量,等同于 rados df )
ceph pg stat
# 查看特定 PG 的详细状态信息
ceph pg <PG_ID> query
# 定位指定状态的 PG
ceph pg dump_stuck <unclean|inactive|stale|undersized|degraded>9.6.4 PG 状态
creating
当创建一个 pool 后,集群将会创建指定数量的 PG 并按照 CRUSH 规则并将其分发到不同的故障域对应的 OSD 之上,此时集群将回显 PG 的 creating 状态,一旦创建成功,PG 的状态将转为 peering,之后转为 active+clean 状态。
peering
在 PG 的 peering 的过程中,ceph 会对包含了一组 PG 的不同 OSD 之上的数据和元数据版本达成一致。但是,达成一致并不意味着副本都持有最新的数据。因为在 peering 过程中,也可以接受数据写入请求,因此存在数据变化的情况。
Authoritative History
ceph 在对客户端的写入操作的确认机制是等所有的 OSD 之上的副本都写入数据并更新后,才会返回 ACK 给客户端。这种机制为了保障 actiing set 中至少有一个成员持有并记录了自上次 peering 成功之后的最新的写操作记录。通过准确记录每一个写操作的记录,ceph 能够传播 PG 的最新权威版本。
active
PG peering 完成之后,会转变为 active 状态。这种状态意味着 PG 可以接受客户端对数据的读写请求。
inactive
PG 不能够接受读写请求,可能正在等待同步最新的数据。
cleanclean 状态意味着 primary OSD 和 replica OSD 之间数据状态一致,且达到指定的副本数量。
unclean
PG 未达到指定的副本数量。
degraded
正常情况下,当客户端写入数据到 primary OSD 的 PG 时,primary OSD PG 会将数据复制到 replica OSD PG 之上。在 primary OSD PG 未收到 replica OSD PG 复制数据成功的 ack 之前,primary OSD PG 将一直处于 degraded 状态。因此,一个 PG 的状态可能处于 active+degraded 状态,此时客户端依然可以持续写入数据,例如当一个 OSD down 之后,其之上的所有 PG 就会转变为 active+degraded 状态,直到此 OSD 重新加入后再次进行 peering 操作。此外,当某个 PG 中的 object 损坏时,此 PG 也会处于 degraded 状态,但是此 PG 中的其他 object 依然可以被访问。例如主 OSD 在读写数据,副本OSD down 状态,之后 down 掉主 OSD,启动副本 OSD ,就会发生某些对象找不到的情况。此时,PG 也处于 degeaded 状态,尽管这个 PG 他可能是 active 状态,因为除了故障时更新的对象之外,其他对象是权威版本,依然可以接受读写。
recovering
当 OSD 故障再次加入集群后,其之上的数据可能落后于当前最新的版本,此时,OSD 会和权威版本的数据进行同步和更新自身的数据。在同步或更新完毕之前,会处于 recovering 状态。当集群中 OSD 大规模发生故障时,会引起巨大的恢复数据流量,因此 ceph 在数据请求和数据及 PG 恢复之间提供了平衡配置参数,以避免资源争用。参见 8.5.6 recovery。
backfilling
当给集群新添加 OSD 后,会触发 CRUSH 算法重新分配 PG 的分布,这个过程 PG 将处于 backfilling 状态。常见的几种 backfill 状态:
参见 8.6.6 OSD 配置
backfil_wait: 回填操作尚未开始,正处于等待状态。backfilling:回填操作正在进行。backfill_toofull:由于存储设备剩余存储容量不足,无法完成回填操作,此状态可能是短暂的,PG 进行平衡后,达到一定条件后可再次启动回填操作。当一个 PG 无法完成 backfill 时,可能被标记为incomplete。
remapped
当承载 PG 的一组 Acting Set OSD 发生变化时,意味是数据从旧的 Acting Set 迁移到新的 Acting Set 上去,此时 PG 处于 remapped 状态。在此过程中旧的 Acting Set 会一直处理数据请求,直到数据迁移成功后,由新的 Acting Set 接管。
stale
在某些情况下,例如网络故障可能导致 ceph-osd 进程无法报告自身的状态,默认情况下,OSD 进程每半分钟报告一次自身状态。
9.6.5 object 定位
客户端在存储一个 object 时,会请求的最新的 cluster map,然后利用 CRUSH 算法计算 object 映射到 PG 的位置。定位一个 object,只需要知道 object 的 pool 名称和 object_name 即可。
# 查看某个 pool 中的对象列表
rados -p <POOL_NAME> ls
# 查看某个 object 位置
ceph osd map <POOL_NAME> <OBJECT_NAME>
# 上传一个 object
rados put <OBJECT_NAME> <FILE_PATH> --pool=<POOL_NAME>
# 取出一个 object
rados get <OBJECT_NAME> <FILE_PATH> --pool=<POOL_NAME>
# 删除一个 object
rados rm <OBJECT_NAME> --pool=<POOL_NAME>9.7 用户管理
用户的范围可以是具体的客户端、应用程序、集群内守护进程。创建一个具有权限的用户决定了此用户对集群中的 Pool、进程、API 等有哪些操作及访问权限。Ceph 集群中有用户类型的概念,例如管理员的用户类型都为 client 。使用 . 符号将用户类型和用户 ID 即用户名隔开,其格式为 TYPE.ID,例如 client.admin 、osd.0 等 。引入此规则和概念是因为除 client 之外,mgr、osd、mds 等守护进程也使用 CephX 认证方式,但它们不是客户端。注意: 1、指定用户时尽可能使用 --name或-n 选项来同时指定类型和名称,例如 client.user1。2、Ceph 集群用户和对象存储用户、文件系统用户不同,对象存储的最终用户由对象网关自己的用户管理机制,对象存储和集群之间则使用的是 Ceph 集群的用户机制。
9.7.1 权限
Ceph 使用了术语 capabilities (caps) 来描述一个被授权的用户对 monitor、OSDs、CephFS 等的操作权限。此外,caps 还可以限制对 Pools 内的数据或名称空间的操作。或者基于应用的 tags 来授权。
mon capsMonitor 权限包括r|w|x和预配置权限模板profile <name>。
9.8 pool 操作
9.8.1 创建池
基本格式:
9.9 CRUSH Map 基础
ceph 集群通过使用 CRUSH 算法来存储和检索数据的位置,之后授权 client 直接和 OSD 进行数据交互,而不是通过代理中央服务器来进行数据交互。ceph 的无单点故障、性能线性扩展等特性都依赖于 CRUSH 算法实现。cluster map 包括 CRUSH map 和 OSD map。CRUSH map 包括了集群拓扑结构和计算寻址的 CRUSH 规则,OSD map 则是一个所有 OSD 信息的列表。CRUSH map 主要包括:OSD 列表、bucket 列表(元素位置信息/集群拓扑结构)、rules(数据放置规则)。CRUSH 算法通过对物理设备的拓扑结构进行选择,从而避免硬件故障带来的业务中断,例如将不同副本放置于不同的故障域内。默认情况下,CRUSH 的默认故障域为 host,即会将不同的副本放置于不同的 host 下的 OSD 之上。
9.9.1 CRUSH location
OSD 在 CRUSH map 中层级结构的位置被称为 crush location,即可理解为 crush location 描述了 OSD 在集群拓扑结构中的具体位置。crush location 使用键值对的列表形式来描述。例如 OSD 的位置可能是 row、rack、host(CRUSH 默认 location)等。
# crush location 描述形式
root=default row=a rack=a2 chassis=a2a host=a2a1
# 查看 osd crush location
ceph osd find osd.X注意: 1. 键值对无顺序之分。 2.
键必须是 CRUSH type 中的值,也可以自定义 CRUSH 中的 type 的值。 3. OSD 的 crush location 的值必须指定,不可空缺。默认情况下, ceph-osd 进程会自动获取值为root=default host={hostname -s}的 crush location。也可在 ceph.conf 配置文件中指定 crush location 的值,当 ceph-osd 进程启动时,会使用ceph-crush-location工具获取每个进程的 CRUSH location 信息(获取 CRUSH location 信息的生效优先顺序 ceph.conf_crush_location > ceph.conf crush_location > default root=default host=HOSTNAME),并检查 CRUSH map 中的位置是否匹配,如果验证不通过,则会移动自身在 CRUSH 中的位置。可禁用自动移动 OSD 位置的功能:
>[osd] >osd crush update on start = false ># 手动获取 crush location >ceph-crush-location --cluster <cluster-name> --id <OSD_ID> --type osd
9.9.2 CRUSH 结构
devices
devices 通常是一个磁盘设备,相对应一个 ceph-osd 进程。每一个 devices 由非负整数 ID、名称(osd.N)、class(hdd/ssd)三个元素标记。device 0 osd.0 class hdd,在 CRUSH 层级结构中是叶子结点。
types
是 CRUSH map 中实现定义物理拓扑的层级结构的术语,默认包括 osd、host、chassis、rack、row、pdu、pod、room、datacenter、zone、region、root 十种类型。
buckets
除叶子结点以外的其他层级都统称为 bucket。在 CRUSH map 中的所有层级结构,例如 root、host、osd 等都关联一个权重 weight,表示设备或层级结构能存储的全部数据的比例,其中每一个 bucket 的权重是所有叶子结点的权重之和。
># 查看 CRUSH 层级结构及其 weight >ceph osd crush tree
rules
rules 定义了在层级结构中放置数据及其副本的策略,大多数关于 rules 的定制可通过命令行进行配置。
># 查看规则当前的 rules 的列表 >ceph osd crush rule ls ># 查看某个规则详细信息 >ceph osd crush rule dump <rules_name>
device classes
每一个设备都可以根据其物理属性设置一个 classes 标签,例如 HDD、SSD、NVMe等。默认情况下,OSD 将根据 Linux 内核公开的硬件属性给 OSD 一个 classes 标签。
># 删除 OSD 原有 classes 标签 >ceph osd crush rm-device-class osd.N osd.M ># 添加标签 >ceph osd crush set-device-class <classes-name> osd.N osd.M ># 创建针对特定设备 classes 的数据分布规则 >ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class> ># 查看当前 OSD 的标签信息 >ceph osd crush tree --show-shadow
weight setsweight set 是不同于 weight 的另外一组影响放置数据的权重集。传统的 weight 数值关联并表明了 CRUSH map 中设备实际存储数据的能力,然而,CRUSH 算法是伪随机的机制,因此 PG 的分布总不能够达到一个完美的平衡状态。weight set 允许根据集群的层级结构、pool 等进行权重优化,进而达到数据的平衡分布。weight-set 的配置支持两种模式:参考 9.4.4 weight-set
- compat
compat模式下,weight-set 是集群层级结构和设备的 weight 的另一种替代。这种模式有一个弊端,即便可以保证 PG 在 OSD 上的分布均衡,但无法保证每个 pool 的 PG 在 OSD 上的分布平衡。但 compat 模式向后兼容旧版本的 ceph 客户端。 - per-pool
per-pool模式下,允许针对每个 pool 进行 PG 分布均衡。此种模式下,又分为 flat 和 positional 形态。不建议在生产环境使用此种方式进行数据平衡。

9.9.3 CRUSH 命令行修改
replicated rule
在副本 pool 中,其关键就是故障域的设置,例如故障域设置为 host,则 rule 规则会保证将副本放置到不同 host 的 OSD 之上,同理如果故障域设置为 rack,则 CRUSH 规则保证将副本分发到不通 rack 的 OSD 之上。故障域的配置除了可以配置为某个 host、rack 上的不同 OSD 之外,还可以进一步配置将副本分发到故障域下某个特定类型的存储设备上,例如 ssd、hdd、nvme等。
># 创建一个 CRUSH rule,root-name 默认值为 default >ceph osd crush rule create-replicated <rule-name> <root-name> <failure-domain-type> {<class>}
erasure rule
在纠删码 pool 中,同样需要配置故障域,数据放置在 CRUSH 中的那个层级结构中,以及那个设备类中。和创建副本池不同,在创建纠删码池时需要根据 erasure code profile 文件来创建,而 CRUSH rule 将会被自动创建。erasure-code-profile 文件由多个键值对组成,其中大多数控制 pool 的编码行为,其中以 crush- 开头的配置项将影响 CRUSH rule 规则。
># 列出当前存在的 erasure-code-profile >ceph osd erasure-code-profile ls ># 查看 erasure-code-profile 内容 >ceph osd erasure-code-profile get <profile-name> ># 创建一个 erasure-code-profile >ceph osd erasure-code-profile set <profile-name> <key-value> <key-value> ... ># 手动创建 erasure-code rule >ceph osd crush rule create-erasure <rule-name> <profile-name>
其他修改
># 手动 ceph osd crush rm osd.X 一个 OSD 之后,需要将它添加到集群拓扑结构中时,执行以下操作 >ceph osd crush set <osd-id> <weight> root=default <bucket-type>=<bucket-name> ... ># 调整 OSD weight >ceph osd crush reweight <osd-id> <weight> ># 添加一个 bucket。例如可将每个节点的几块硬盘组成一个单独的 bucket,放置不同的数据 >ceph osd crush add-bucket <bucket-name> <bucket-type> ># 删除一个 bucket,一个空的 bucket 才允许被删除 >ceph osd crush remove <bucket-name>
9.9.4 CRUSH tunable
在 CRUSH 算法中,支持可调参数以改变 CRUSH 算法的行为,并能够兼容新旧版本的 CRUSH 算法。对于 CRUSH 算法的某些新特性,需要客户端和服务端的支持。Ceph 提供了预配置模板 profile,不同 profile 的 CRUSH 配置参数不同。可使用 ceph osd crush tunables <tab> 查看,例如名称为 firefly 的 profile 配置参数仅仅支持 firefly 版本,ceph-mon、ceph-osd 进程将拒绝接受旧版本客户端的连接。
- 各版本 profile 变化参见: https://docs.ceph.com/docs/master/rados/operations/crush-map/#tunables
- 调整 CRUSH 参数可能会导致 PGs 在节点间迁移。
- 更新变化参数后,新连接的客户端将使用新变化后的参数,此前持续连接的客户端如果不支持新特性,将会表现为异常。
9.10 CRUSH Map 详解
9.10.1 基本操作
# 获取 CRUSH Map
ceph osd getcrushmap -o <crush_bin>
# 反编译 CRUSH Map
crushtool -d <crush_bin> -o <crush_txt>
# 编译 CRUSH Map
crushtool -c <crush_txt> -o <crush_bin>
# 注入新的 CRUSH Map
ceph osd setcrushmap -i <crush_bin>9.10.2 组成部分
CRUSH Map 由 6 部分组成:tunables 所有可调参数,这些参数影响 CRUSH 算法的行为,用来纠正和优化以前 CRUSH 版本的错误和不合理。devices 单个 ceph-osd 进程可以存储数据的设备。type 定义了在 CRUSH Map 层级结构中 bucket 的类型。buckets 指定了层级结构中包含的元素、类型、权重等信息。rules 定义了数据分发策略。choose_args 指定 ceph 中的另外一种权重集 weight-set。
devices
每一个 device 都被一个非负整数 id 唯一标记,通常此 id 和 osd.N 中的 N 相同,此外每一个 device 都有一个 class 标签,使得 rule 更方便的分发数据。
># devices >device 0 osd.0 class hdd
type
定义了层级结构中 bucket 的类型,bucket 可以聚合例如 host 等的叶子节点,也可以是无叶子节点的 bucket,例如 OSD。bucket 在 CRUSH 语境中表示一个节点,此节点可以是一个位置也可以是具体的硬件设备。添加 bucket type 需要手动编辑 CRUSH Map。
Bucket
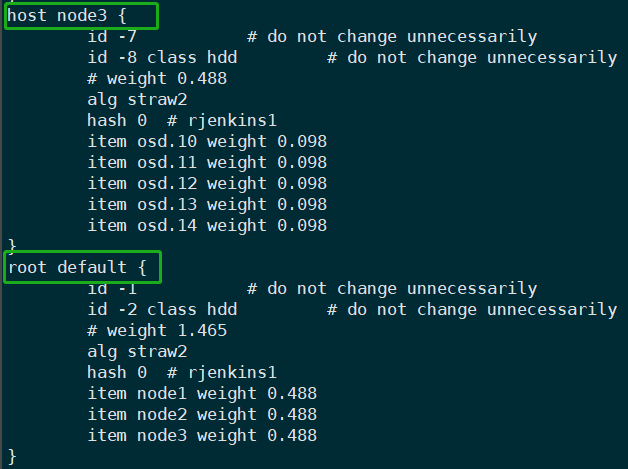
CRUSH 算法通过设备的 weight 值计算权重,之后根据 CRUSH Map 中定义的层级结构和存储设备在设备之间进行分发数据,实现数据均衡的发布。通过将 PG 映射到故障域的 OSD 之上来实现数据冗余,故障域的实现则依赖于 Bucket 的层级结构,层级结构的类型在 CRUSH Map 中的
#type下被定义,目的是通过 bucket 的层级结构来实现将叶子节点隔离到不同的故障域中。在定义一个 bucket 实例时,需要指定 type、name、ID(负整数)、weight、算法(通常为straw2)、hash(hash 算法,通常为 rjenkinsl)、item。
# 示例 # buckets <bucket_type> <bucket_name> { id <num> id <num> class <class_name> # weight 0.488 alg <select_algorithm|uniform | list | tree | straw | straw2> hash 0 # rjenkins1 item osd.x weight x.xxx item osd.2 weight 0.098 item osd.3 weight 0.098 item osd.4 weight 0.098 item osd.1 weight 0.098 }注意
- bucket 中的 weight 值是用物理设备存储容量来衡定的,1 weight = 1TB。
- 较高级别的 bucket 的 weight 是其包含元素的 weight 之和。
rules
CRUSH Map 中定义了数据的放置规则,默认情况下每一个 Pool 都关联了 CRUSH Map 的 rules。根据使用场景,可为不同的 Pool 制定不同的 rules。默认情况创建的 Pool 将关联 id 为 0 的 rules。
rule <rulename> { id [a unique whole numeric ID] type [ replicated | erasure ] min_size <min-size> max_size <max-size> step take <bucket-name> [class <device-class>] step [choose|chooseleaf] [firstn|indep] <N> type <bucket-type> step emit }rule 配置项说明:
id一个非负整数,旨在唯一确定一个 rule。type用来确定用于复制池或纠删码池,可选值有replicated和erasure。min_size如果 Pool 的副本数设置小于此值,则 CRUSH 算法将拒绝使用此条规则分发数据。max_size如果 Pool 的副本数设置大于此值,则 CRUSH 算法将拒绝使用此条规则分发数据。step take <bucket-name> [class <class-name>]分发数据的动作起始点,此处指定了一个 bucket,用来选择一个 bucket 并进行迭代进而分发存储数据。此外还可以指定 class 类,并在选择时排除所有不属于此类的设备。step chooseleaf|choose firstn <num> type <bucket-type>从上一步 take 选出的 bucket 中使用深度优先遍历算法选出指定类型和数量的 item,如果 item 对应的设备故障、过载等因素无法被选中时,会触发 chooseleaf 重新进行选择。目前支持的选择算法有firstn和indep,分别用于副本和纠删码场景,两种算法在发现分发的目标设备出现故障无法选出足够的数量时(以4为例),firstn 将返回 [1,2,4] 类型的形式,CRUSH 算法将选择其他设备再次返回 [1,2,4,6] 形式,indep 算法将返回 [1,2,none,4] 的形式,CRUSH 算法再次选择分发数据时会返回 [1,2,6,4] 的形式。其大致过程为:选择一组指定了 bucket-type 的 bucket,bucket 的数量通常是 Pool 的副本数量,并从树中的每个 bucket 中选择叶子节点。chooseleaf 为故障域模式,choose 为非故障域模式,type 表示在 chooseleaf 模式下规定输出为 type 指定的类型中不同的 bucket 下的叶子节点。set emit输出选择结果。
9.11 Placement Group
9.11.1 PG 自动调整
PGs 是 Ceph 集群实现数据分发的一个逻辑组件,可以手动指定 PG 数量或启用 pg-autoscale 特性来自动调整 PG 数量。每一个 Pool 都可以设置一个 pg_autoscale_mode 属性来配置 PG 的自动调整,pg_autoscale_mode 的配置值有三个:off|on|warn ,off 表示关闭自动调整特性,on 表示开启,warn 表示当 PG 数量不合理时,发出告警信息。
# 针对某个 pool 启用自动调整特性
ceph osd pool set <pool-name> pg_autoscale_mode <off|on|warn>
# 全局配置自动特性
ceph config set global osd_pool_default_pg_autoscale_mode <off|on|warn>查看调整状态
ceph osd autoscale-status显示信息解释:
SIZE: Pool 中的数据总量。TARGET SIZE:指指定的预期数据存储总量配额。RATE:实际数据量和占用裸容量的比例。例如 3 副本 Pool 的 RATE 值为 3.0,纠删码 Pool 中 k=4,m=2 时,RATE 值为 1.5。RAW CAPACITYPool 占用的总的裸容量。RATIO:占用裸容量占总裸容量的百分比。RARGET RATIO:预期数据存储总量配额百分比。PG_NUM|NEW PG_NUM|AUTOSCALE:表示当前 PG 数量和预期调整后 PG 数量,以及自动调整特性当前启用状态。
自动调整
最简单的方式是让集群通过总可用容量和期望 PG 的数量对 PG 数量进行自动调整,根据每个 Pool 占用的存储空间并尝试重新分配 PG。自动调整的方式相对比较保守,只有当前 PG 数量偏离目标 PG 数量的三倍以上时才会触发进行调整,当然期望每个 OSD 承担的 PG 数量是可调整的。自动调整进程将分析 pool 和 CRUSH 层级结构中的每个层级的利用率进而做出最佳的调整策略。
# 默认值为 100
ceph config set global mon_target_pg_per_osd NPool 容量限制
# 新版本中支持限制 Pool 使用的容量
ceph osd pool set <pool-name> target_size_bytes <size>
ceph osd pool set <pool-name> target_size_ratio <ratio>
#配置每个 Pool 的 PG 数量最小值
ceph osd pool set <pool-name> pg_num_min <num>9.11.2 PG 放置组
PG 是一个逻辑概念,是对象的集合。在 Ceph 集群中有成千上万对象,基于对象的粒度追踪数据其代价是巨大的,因此在保证数据安全可靠的前提下,Ceph 基于 PG 的粒度追踪数据。Ceph 客户端在访问数据时,计算 PG 的位置进而查找 object 的位置,更多的 PG 数量意味着能够在 OSD 之间更均匀的分布,但同时这也会增加额外的性能成本。参见 2.3.2 PG 和 object 映射、2.3.3 PG ID 计算
数据持久
单个 PG 内的对象可能永远丢失的场景:
一个 OSD 故障,其之上的 PG 和 对象副本数量从 3 变为 2,Ceph 集群选择一个新 OSD 并开始恢复重建降级的数据,从剩余的数据副本复制第三个副本。在恢复复制期间,剩余的 2 个副本所在的 OSD 也发生故障,数据的副本有可能只幸存一个。此时,Ceph 将继续选择一个新的 OSD 进行复制恢复数据,以保持指定的数据副本数,如果在恢复期间第三个副本所在的 OSD 也发生故障,则会导致数据永久性丢失。
假设在 10 个 OSD 规模的三副本 512 个 PG Ceph 集群中,CRUSH 算法会将数据分别分发到故障域下的 3 个 OSD 之上,每个 OSD 承载的 PG 数量为(512*3)/10=150。当某个 OSD 发生故障后,Ceph 将故障 OSD 上的数据均匀的分发复制到剩余的 9 个 OSD 上。剩余的 9 个 OSD 可能会接受新的数据和恢复故障 OSD 上的数据。而数据恢复的速度完全取决于集群组网方式和网络设备,在网络环境环境一定且网络不是瓶颈的情况下,增加 OSD 数量将提高数据恢复速度,因为剩余的每个 OSD 负责接收的恢复 PG 数据量减少。此外,在这种场景下,恢复速度不一定随 OSD 数量增加而线性增长,如果 OSD 过多,但 PG 数量很少,假设每个 OSD 承载 20 个 PG,但 OSD 有 200 个,则当有 OSD 故障后,剩余的 OSD 不能够全部参与分担数据恢复,因此此时有应该增加 PG 数量。另外,在上面假设的永久丢失数据的场景下,增加 OSD 数量,可以有效减少数据丢失风险,因为丢失一个 OSD 其所丢失分担 PG 数量将降低。
PG 数量计算
$$
\frac{(每个OSD承载 PG 数)\times OSD个数\times(Pool预计所占总容量百分比)}{副本数|K+M}=Pool的PG数
$$
注意:1. 取计算值四舍五入后取最接近 2 的幂的方值。2. 如果最接近的 2 的幂的值比计算所得值低25% 以上,则使用下一个更高的 2 的幂。3. 不建议使用空池来预留预先占用 Pool ,以达到未来增加 Pool 导致的 PG 数量变化。4. 空 Pool 关联的 PG 会额外占用内存和 CPU 资源。
PG 数量设置
通常在创建 Pool 时指定 pg_num 和 pgp_num,或者使用默认值 osd pool default pg num osd pool default pgp num。也可在创建之后进行调整,Luminous 版本之后,可以减小 PG 数量,但不建议减小 PG 数量,会增加丢失数据的风险。
ceph osd pool set <pool-name> pg_num <pg_num>
ceph osd pool set <pool-name> pgp_num <pgp_num>当增加 pg_num 后,PG 会被分裂,但在 pgp_num 增加之前,数据并不会立刻迁移到新的 PG。当减少 pg_num 时,pgp_num 会自动减少。
PG scrub
Ceph 通过检查主 PG 和副本 PG,对所有的 object 生成一个索引目录然后进行比较,确保所有 object 数据内容一致。
# srub 指定 PG
ceph pg crub <pg_id>
# Luminous 版本之后可针对某个 pool 中的所有 PG 进行 scrub
ceph osd pool scrub <pool_name>backfill/recovery PG
在某些情况下,集群可能面临大量 PG 需要 backfill/recovery,客户端可能急需使用某些 PG 内的数据,这种场景下,可以考虑优先手动恢复指定的 PG。此操作不会中断当前正在恢复的 PG 操作。
# 执行优先 backfill/recovery 操作
ceph osd force-revocery <pg_id> <pg_id> ...
ceph osd force-backfill <pg_id> <pg_id> ...
# 取消操作
ceph osd cancel-force-revocery <pg_id> <pg_id> ...
ceph osd cancel-force-backfill <pg_id> <pg_id> ...
nautilus 14.2.0版本新添加针对指定 Pool 的 force-backfill/recovery 操作
# 执行优先 backfill/recovery 操作
ceph osd pool force-revocery <pool-name>
ceph osd pool force-backfill <pool-name>
# 取消操作
ceph osd pool cancel-force-revocery <pool-name>
ceph osd pool cancel-force-backfill <pool-name>注意:此操作可能打破 Ceph 内部本来 backfill/recovery 的队列顺序,慎重使用!建议对 pool 设置 backfill/recovery 的优先级。
# 例如有 10 个 pool,可将最重要的 pool 恢复优先级设置为 10
ceph osd pool set <pool_name> recovery_priority <value>9.12 缓存分层 (1)
9.13 纠删码池 (1)
10. 相关故障排查
10.1 Monitor 故障排查
10.1.1 排查思路
- monitor 节点网络是否能够正常连接?
- mon-ceph 进程是否在运行?
- 使用 telnet 工具确认 mon-ceph 监听的
3300和6789端口是否监听且能够正常连接?ceph -s命令是否能够查看集群信息,如果返回集群状态信息,说明 monitor 集群是正常运行的,即 monitor 节点形成了法定人数。如果不能够返回集群状态信息,则说明 monitor 集群没有在正常运行,即有可能没有形成法定人数。- 如果确定 ceph-mon 进程正在运行,则在Emperor 版本之后,将可以分别连接单个 ceph-mon 节点查看状态,无论是否形成法定人数。可以使用
ceph ping mon.*命令显示 mon 节点的状态。
10.1.2 套接字管理
当 ceph-mon 进程在运行状态时,可使用管理套接字进行管理,如果进程未运行,则会返回 111 错误码。
# 查看 mon-ceph 套接字存放路径
ceph-conf --name mon.ID --show-config-value admin_socket
# 使用套接字管理,help 子命令可查看支持的命令
ceph daemon mon.<id> <command>10.1.3 monitor out of quorum
- 此方法适用于 monitor 节点数据未损坏时适用。
- 首先确保 ceph-mon 进程处于运行状态;
- 确保 ceph-mon 监听端口是可以被访问的;
- 如果一个或多个 moinitor
out of quorum,只要有一个 monitor 处于运行状态,其 socket 可以通信,则使用ceph daemon mon.id mon_statu查看其状态应该是probing、electing、synchronizing之一,如果运行中的 monitor 正好是leader或peon,则可以达到法定人数,正常运行。- 如果 montor 处于 probing 状态,则意味着每次启动 monitor 时,该 monitor 将在此状态下保持一段时间,同时尝试查找monmap 中指定的其余 monitor。在只剩下一个 monitor 节点时,此节点将无限期保持这种状态,直到有其他 monitor 节点加入。此时,就需要排查其他 monitor 节点的问题,首先排查时间是否同步?其他 monitor 节点是否能够被正常连接?地址是否正确?如果到此还不能回复 monitor 节点,则可以考虑恢复 monitor 节点的 monmap 等数据。
- 如果可运行的 monitor 节点处于
electing状态,这意味着 monitor 在选举状态,在选举状态的 moinitor 集群很快就能完成,此状态不是一个持续的状态。- 若果 monitor 处于
synchronzizing状态,这意味着 monitor 正在与其他节点进行同步数据,这个过程很快。- 如果 monitor 处于
peon状态,通常很少见这种状态,通常可能是时钟偏移造成的。
- 如果此种方法还未能恢复 monitor 节点状态,还可以考虑使用两种方法来恢复。1、报废故障 monitor 节点,重新创建并加入集群。2、重新注入 monmap,以下方法为重新注入。
10.1.4 重新注入 monmap
如果 monitor 集群达到法定人数,则可以使用此种方法导出 monmap:
ceph mon -c /path/to/cluster-name.conf getmap -o /tmp/monmap如果 monitor 集群没有达到法定人数,且无法正常连接,则可以使用以下方法导出 monmap, ceph-mon 进程需要停止:
# 注意:导出前需要关闭 cpeh-mon 进程
ceph-mon -c /path/to/cluster-name.conf -i ID-MON --extract-monmap /tmp/monmap给故障 monitor 节点导入 monmap:
ceph-mon -c /path/to/cluster-name.conf -i ID-MON --inject-monmap /tmp/monmap然后启动 monitor 节点进程。
10.1.5 恢复 monitor 数据
- 如果部分节点的数据损坏,则可以重建一个 monitor ,数据将会自动同步。如果所有的 monitor 节点故障,且数据全部丢失,则使用以下方法。
思路
- 从各个节点中的 osd 中搜集 cluster map 信息,叠加恢复
store.db数据库。- rebulid 数据库,然后添加到 mon 节点数据目录下。
- 添加丢失的各进程认证密钥。
- 配置 dashboard、mgr、rgw 等丢失的配置参数。
10.1.6 monitor 节点恢复
在三个 monitor 节点的集群中,删除其中两个 monitor 节点的数据,此时,monitor 达不成法定人数,集群陷入全面瘫痪状态,客户端无法连接到集群,从其中正常的一个 monitor 节点上查看正常的 monitor 节点的状态。只需要初始化故障节点,并启动,之后会从正常的节点同步数据。

此时 monitor 节点将会长时间处于 probing 状态,直到有新的 monitor 节点加入集群。
恢复过程如下:
# 从正常的 monitor 节点提取 monmap,此时 mon 集群未达成法定人数,所以使用 ceph-mon 工具导出monmap。注意:导出之后,mon数据目录下的文件权限会被修改,需要手动修改回属组属主为ceph
ceph-mon -c /etc/ceph/test-ceph.conf -i node1.ceph.com --extract-monmap /tmp/monmap
# 在故障节点创建数据目录
mkdir test-ceph-node2.ceph.com
# 注意:在需要恢复的节点上准备好 monmap 和 {cluster-name}.mon.keyring 文件,之后初始化故障节点
ceph-mon --cluster test-ceph --mkfs -i node2.ceph.com --monmap /tmp/monmap --keyring /etc/ceph/test-ceph.mon.keyring
# 修改数据目录属组属主
chown -R ceph:ceph test-ceph-node3.ceph.com/
# 启动故障节点 ceph-mon 进程
systemctl start ceph-mon@node2.ceph.com
# 此后 mon 集群即可形成法定人数,ceph -s 可查看状态信息,客户端访问恢复正常10.1.7 数据全部丢失恢复
10.2 OSD 故障排查
排查思路
- 在排查 osd 故障之前,首先检查 mon 集群和网络是否正常,使用
ceph -s、ceph health detail命令查看 mon 集群状态,如果能够正常返回集群状态,则进行下一步排查工作,如果不能正常返回,则首先恢复 mon 集群。- 使用
ceph osd tree、ceph osd stat,甚至查看 pg 的状态来了解足够多当前 osd 的状态。- 查看日志
/var/log/ceph,必要的情况下将 osd 的日志级别调整高,然后输出足够多的日志信息进行排查故障。- 从 OSD socket 查看运行信息,
ceph daemon osd.X help命令查看子命令。从 socket 可获取运行时配置、历史操作、队列信息、性能等信息。- 使用 df、iostat 等命令查看文件系统、磁盘等状态信息。
- 重启 OSD 进程。
维护 OSD
ceph osd set noout
systemctl stop ceph-osd@X
# =====维护
systemctl start ceph-osd@X
ceph osd unset noout磁盘空间不足
11. 相关概念解释
部分内容引用自维基百科和百度百科
脏数据
以Linux脏页为例,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。readahead
提前读入,推测性的将文件数据提前读取到缓存中,消除等待时间,增大IO传输单元,提高性能。QOS(Quality of Service) 服务质量
网络中的一种流量控制机制,用来解决网络延迟和阻塞的一种技术。IOPS(Input/Output Operations Per Second)
一种用于存储的性能测试的方式,每秒的读写次数。最常用的测试指标是在随机读写和顺序读写的IOPS。QEMU
虚拟化技术类型:平台虚拟化、资源虚拟化、应用程序虚拟化。
平台虚拟化技术分类:1、全虚拟化(Full Virtualization),虚拟机完整的模拟完整的底层硬件,全虚拟化解决方案有VMM、Microsoft Virtual PC、VMware Workstation、Virtual Box、QEMU。2、超虚拟化(Paravirtualization),客户机内核需要被特殊修改以运行在VMM之上, 例如XEN。3、**硬件辅助虚拟化(Hardware-Assisted Virtualization)**,利用硬件(主要是CPU)辅助处理敏感指令以实现完全虚拟化的功能,客户操作系统无需修改,例如KVM。
QEMU-KVM中,KVM负责CPU、内存的虚拟化,但KVM并不能模拟其他设备,QEMU模拟IO设备等。
POSIX
可移植操作系统接口(Portable Operating System Interface),在不同内核操作系统之间系统调用存在差异,造成应用在不同内核操作系统之间的移植的困难,为了解决这个问题,IEEE 为各类UNIX操作系统定义了一系列API,各类操作系统只要遵守这组标准的API即可。DIO
DIO = Digital Input/Output,Direct I/O是系统范围的功能,它通过绕过系统的读/写缓冲区高速缓存来支持从磁盘到应用程序内存空间的直接读/写操作。文件只是存储在媒体上的数据的集合。当某个进程想要从文件访问数据时,操作系统会将数据带入主内存,该进程将读取它,对其进行更改并存储到磁盘上。操作系统可以针对每个请求直接在磁盘上读写数据,但是由于磁盘访问时间较慢,所以响应时间和吞吐量都很差。因此,操作系统尝试通过在称为文件缓冲区高速缓存的结构中并在主内存中缓冲数据来最大程度地减少磁盘访问的频率,减少CPU消耗并消除两次复制数据的开销。AIO
异步事件非阻塞I/O: 也叫做异步I/O(AIO),用户程序可以通过向内核发出I/O请求命令,不用等带I/O事件真正发生,可以继续做另外的事情,等I/O操作完成,内核会通过函数回调或者信号机制通知用户进程。这样很大程度提高了系统吞吐量。
页面
内存划分的单位,即分配内存的最下单位。在 Linux 中,每个页面的大小为 4K,在 Windws 中,使用 256KB 大小的视图表示。
页面缓存
在内存中保存的以页面大小为单位(Linux 系统此大小通常为 4K,可使用getconf PAGE_SIZE命令查看配置)的文件块。页面帧
内存的物理地址页面,一个页帧的大小和一个页的大小相同。巨型帧 (jumbo frames)
有效负载超过IEEE 802.3标准所限制的1500字节的以太网帧。
12. 硬件及系统
12.1 系统分区
注意 / 说明:
- 服务器挂载磁盘容量规格为 6TB,鉴于 MBR 分区方式只能管理 2TB 以内磁盘,因此选用 UEFI+GPT 的引导方式和磁盘分区格式。
- UEFI 引导方式需要单独将 efi 分为一个独立分区,在安装操作系统前手动创建分区时需要格外注意,否则可能导致安装失败。
- 考虑到未来可能涉及 ceph 版本升级,需要系统内核升级,因此 /boot 分区容量可以略微大一点。
- 在系统根目录下,变化最频繁和增长最快的目录是日志文件,为了避免日志累积无剩余容量导致文件系统奔溃,因此将 log 目录挂载至一个单独且较大的分区。
- 系统内其他数据变化频繁的目录都将挂载单独的硬盘设备,例如
/var/lib/ceph/mon等。
12.2 NetworkManager
说明:经测试,使用 CentOS 新的网络管理 NetworkManager 服务已趋于稳定,在新版本的 CentOS 中,ifcfg 的方式已被弃用。截止目前测试,未发现不稳定现象,且更易于管理和不容易出错。因此放弃传统的 ifcfg 网络管理方式,尽管 NetworkManager 这样的工具略有悖于 Linux 一切皆文件的哲学理念。
在 CentOS7 网络管理由 NetworkManager 服务负责,它是一个动态的网络控制和配置守护进程。依然向下兼容 ifcfg 配置文件的配置方式。NetworkManager 在检测到系统中没有网络配置但有网络设备时,它会创建临时连接。NetworkManager 提供了命令行工具 nmtui、nmcli。
由于早期的网络配置服务脚本的局限性,网卡配置并不能通过 reload 来加载更改的配置信息,只能重新启动 network 服务,重新启动意味着需要重新启动所有网卡设备,并可能带来短暂的网络中断。
在 Centos7 中,如果编辑
ifcfg文件,NetworkManager 服务不会自动加载变化后的信息。如果手动编辑了 ifcfg 配置文件,则必须手动通知 NetworkManager 服务来加载此配置文件。
# 通知加载变化的 ifcfg 配置文件
nmcli connection reload
# 通知加载指定 ifcfg 配置文件,可以指定多个配置文件
nmcli con load /etc/sysconfig/network-scripts/ifcfg-ifname当使用 nmcli 命令修改配置信息后,需要重新停止后启用连接,才能生效。但 nmcli 命令会立即将更改写入 ifcfg 文件。
nmcli device disconnect interface-name
nmcli con up interface-name注意:NetworkManager 不会触发任何网络脚本的执行。使用 NetworkManager 服务时,使用 nmcli、nmtui 工具进行配置。不使用 NetworkManager 时,使用手动配置 ifcfg 文件和使用 ip 命令(临时生效)进行修改。
概念:connection 是为一个网卡设备创建的一个连接; device 则为一个硬件接口设备或 bond、网桥设备。
注意:设备在重启时,会自动生成 connection,可设置为
nmcli device set {interface} autoconnect false手动关闭自动连接。
nmcli 工具
nmcli (NetworkManager Command Line Interface) 是在命令行控制和监控网络的工具。其可以创建、显示、编辑、删除、启用、停用连接网络,同时也可以监控网络状态。
# 命令基本格式
nmcli [OPTIONS] OBJECT { COMMAND | help }[OPTIONS] : -t,terse 输出简洁的内容; -f,field 显示指定的字段值,可以是一或多个,例如nmcli -f DEVICE,TYPE device;-p,pretty 将显示标题和美化输出格式。
# 停止或启用某个连接
nmcli con up interface-name
nmcli dev disconnect interface-name # 此命令会禁止设备被自动激活connection.type:网络连接类型
adsl, bond, bond-slave, bridge, bridge-slave, bluetooth, cdma, ethernet, gsm, infiniband, olpc-mesh, team, team-slave, vlan, wifi, wimax
connection.interface-name:连接关联的设备名称
connection.id:用于连接配置文件的名称,对应于配置文件中的
DEVICE配置字段。
# 示例
# 添加动态获取 IP 的连接
nmcli connection add type ethernet con-name {connection-name} ifname {interface-name}
# 添加静态获取 IP 的连接
nmcli connection add type ethernet con-name {connection-name} ifname {interface-name} ip4 {address} gw4 {address}
# 替换或添加 DNS
nmcli connection modify {connection-name} ipv4.dns "8.8.8.8 8.8.4.4"
# 添加 DNS
nmcli connection modify {connection-name} +ipv4.dns "8.8.8.8 8.8.4.4"
# 断开一个连接
nmcli connection down {connection-name}
# 启用一个连接
nmcli connection up {connection-name}
# 配置静态路由
nmcli connection modify {connection-name} +ipv4.routes "192.168.122.0/24 10.10.10.1"
# 配置网卡自动连接
nmcli connection modify {connection-name} connection.autoconnect yes12.3 hostname
主机名分为三类:static、pretty、transient。static 是传统的主机名,保存在 /etc/hostname 文件中。transient 主机名是一个动态主机名由内核使用和维持。pretty 是一个向用户展示的自由格式的字符串。主机名被限制在 64 个字符长度,建议将 static 和 transient 设置为 FQDN 的格式,并限制为小写字母。
hostnamectl set-hostname {host_name}12.4 bonding
bonding 是将多个网络设备绑定为逻辑上的一个设备,增加带宽和冗余能力。bonding 的 active-backup、balance-tlb、balance-alb 模式不需要交换机额外的配置。
使用 NetworkManager 服务管理 bond 设备时,需要注意以下两点:
- 启用 master 接口设备不会自动启动 slave 接口设备,反之亦然。
- 停止 master 接口设备不会自动停止 slave 接口设备,反之亦然。
12.4.1 nmcli 管理
# 创建 bond 接口,注意:如果 con-name 参数未指定,则自动以类型为前缀,后面使用 ifname 名称
nmcli connection add type bond ifname {mybond1}
# 同时传递 bond 内核模块参数
nmcli connection add type bond ifname {mybond0} bond.options "mode=balance-rr,miimon=100"# 给 bond 设备添加 slave 设备连接。可重复执行添加不同的设备给 bond 设备
nmcli connection add type ethernet ifname {ifname} master {mybond0}
# active-backup 模式下,启动并激活 slave 设备和连接
nmcli connection up {ifname}
# active-backup 模式下,更改 master 和 slave 属性
nmcli device modify {mybond0} +bond.options "active_slave={ifname}"
nmcli device modify {mybond0} +bond.options "primary={ifname}"bond 功能由 Linux 的内核模块 bonding 提供,Linux 默认没有加载此模块。如果在 bond 设备配置文件中使用了 BONDING_OPTS ,则 bonding 模块会被自动加载。
# nmcli 立即生效方法
nmcli connection up {con-name}
# 查看 NM 纳管状态
nmcli networking12.4.2 手动管理
在
/etc/sysconfig/network-scripts/目录下创建ifcfg-bondN配置文件:
DEVICE=bond0
NAME=bond0
TYPE=Bond
BONDING_MASTER=yes
IPADDR=x.x.x.x
PREFIX=24
GATEWAY=x.x.x.x
ONBOOT=yes
BOOTPROTO=none
BONDING_OPTS="miimon=100 mode=balance-alb"
# 表示此设备配置不由 NetworkManager 服务管理,如果未设置,则 NetworkManager 可能会更改覆盖此文件的内容
NM_CONTROLLED="no"创建 SLAVE 接口配置文件,在被 bond 设备的成员设备中需要配置
MASTER=bondN和SLAVE=yes来确定被绑定的设备:
DEVICE=ethN
NAME=bond0-slave
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
NM_CONTROLLED="no"激活 bond 设备:
# 激活 SLAVE 设备,将自动激活 bond 设备
ifup ifcfg-{ifname1}
ifup ifcfg-{ifname2}测试 bond 是否生效及有冗余能力:
# 从 bond 设备发出 ping
ping -I bond0 x.x.x.x
# 查看 bond 内核临时文件
/sys/class/net/bondN/bonding/active_slave
/proc/net/bonding/
# 停止某一个接口
ip link set {ifname} down
nmcli connection down {ifname}
# 运行时修改 bond 模式
echo balance-alb > /sys/class/net/bond0/bonding/mode12.5 硬件管理
12.5.1 CPU和内存
对 CPU 和内存性能参数的了解,有助于根据硬件信息配置应用的相关参数。
# CPU
lscpu
# 内存监控
free -h预计分布式存储单节点最大内存使用量为 130G。
12.5.2 硬盘定位
因 Linux 本身 kernel 加载磁盘机制的问题,在系统下使用 lsscsi 命令查看磁盘设备盘符时,盘符识别中会概率性存在漂移问题。Ceph 存储节点服务器槽位如图:

smartctl 工具使用
smartctl 是一个磁盘分析工具,使用工具可以读取磁盘众多的参数信息。其中 SMART 功能需要 BIOS 功能支持。smartd 程序可作为守护进程运行,定期检查磁盘状态并报告检测结果。
# 显示设备简要信息
smartctl -i /dev/sdX
# 显示磁盘全部状态信息
smartctl -H /dev/sdX
# 显示磁盘所有信息
smartctl -H /dev/sdX磁盘自检:注:谨慎执行
# 检查该设备是否已经打开SMART技术
smartctl -a /dev/sdX
# 如果没有打开SMART技术,使用该命令打开SMART技术
smartctl -s on /dev/sdX
# 后台检测硬盘,消耗时间短
smartctl -t short /dev/sdX
# 后台检测硬盘,消耗时间长
martctl -t long /dev/sdX
# 前台检测硬盘,消耗时间短
smartctl -C -t short /dev/sdX
# 前台检测硬盘,消耗时间长
smartctl -C -t long /dev/sdX
# 中断后台检测硬盘
smartctl -X /dev/sdX
# 显示硬盘检测日志
smartctl -l selftest /dev/sdX
# 显示硬盘错误汇总
smartctl -l error /dev/sdXsas3ircu 工具
sas3ircu 支持现有的符合 SCSI 标准的存储设备。sas3ircu 程序可以实现在命令行创建和管理 RIAD。磁盘是指硬盘驱动器(HDD)和固态驱动器(SSD),并且 HDD 或 SSD 可以支持 SAS 或 SATA 协议。sas3ircu 程序支持 LSISAS3008、LSISAS3004 RAID 控制器。此处我们主要使用这个工具查看磁盘槽位。
下载此工具时需要格外注意 RAID 控制器型号及固件版本信息。
硬盘定位思路
安装
smartmontools软件包及sas3ircu工具。可停止 smartd 守护进程。
使用 首先使用 smartctl 查找硬盘 Serial Number 唯一序列号,然后使用 sas3ircu 工具查找 RIAD 卡信息进而查到硬盘 slot 信息,最后通过闪烁或常亮硬盘指示灯定位到硬盘的具体物理位置。
# 将 sas3ircu 程序移动到 /usr/bin 目录下
# 列出 RAID 卡信息
sas3ircu list
# 查看某个 RAID 控制器信息
sas3ircu {N} display
# 根据盘符查找 SN 码
smartctl -a /dev/sdX | grep "Serial Number"
# 根据 SN 码确定槽位
sas3ircu 0 display | grep -B 12 -A 4 BTYF94740B8Q480BGN
# 点亮磁盘指示灯
sas3ircu {RIAD_NUM} locate {Enclosure#}:{slot} on
sas3ircu {RIAD_NUM} locate {Enclosure#}:{slot} off12.5.3 内核参数
SCSI 子系统可以在系统其余部分还在引导时就探测存储等设备,甚至可以并行(异步)探测不同总线上的设备,从而显着提高了速度。可以通过修改内核参数在探测存储设备时不是异步进行,而是同步探测存储设备,即将磁盘扫描方式修改为同步。
# 修改内核参数,添加给内核传递的参数 scsi_mod.scan=sync
vim /etc/default/grub
GRUB_CMDLINE_LINUX="crashkernel=auto scsi_mod.scan=sync
# 重新生成 grub.cfg 文件
grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg
# 重启系统,进入系统后,查看内核参数是否变化
cat /sys/module/scsi_mod/parameters/scan12.6 系统初始化
主机名
hostnamectl set-hostname node0X.cregcloud.com
node01.cregcloud.com
node02.cregcloud.com
node03.cregcloud.com密码
使用 12 字节大小的随机密码,符合密码学密码强度。使用
openssl rand 16 --base64生成。
bash 环境变量
# 为了易于区分两条命令执行结果的分界线,故将 bash 提示符颜色高亮,此外显示当前目录的全目录,避免操作失误,设置 PS1 环境变量如下。编辑 /root/.bashrc
PS1="\[\e[1;31m\][\[\e[0m\] \[\e[1;33m\]\u@\h\[\e[0m\] \[\e[1;36m\]\w\[\e[0m\]\[\e[1;31m\] ]\[\e[0m\]\[\e[1;32m\]\\$ \[\e[0m\]"
# 为了误删除文件,将 rm 命令的执行方式替换为 \rm /path/to/file,并给出警告提示
alias rm="echo -e '\033[31mPrudent operation!!!\033[0m'"
# 历史命令
vim /etc/profile
HISTSIZE = 20000
# 格式化输出时间,备份文件方便格式化输出精确的时间
alias filedate='date "+%Y%m%d%I%M"'vim 环境变量
编辑 vim 环境变量,配置 vim 显示方式,更易于缩进和高亮颜色的显示。
# 编辑 /root/.vimrc
set nu
set ruler
set bg=dark
set nohlsearch
set ts=4
set smyum 源配置
使用阿里相应版本的阿里镜像。
工具安装
yum install wget htop net-tools ntpdate bash-completion telnet tree screen numactl smartmontools vim expect nload sysstatfirewalld | SElinux
1、关闭 postfix 服务;2、为了在部署前为了便于排查问题,暂时将 firewalld 和 SEliux 关闭。未来是开启,有待讨论。
时间同步
使用阿里 NTP 公共时间服务器,后期可考虑部署本地时间服务器,或集群内互相同步时间。
# 修改 /etc/chrony.conf
server ntp.aliyun.com iburst
stratumweight 0
driftfile /var/lib/chrony/drift
rtcsync
makestep 10 3
bindcmdaddress 127.0.0.1
bindcmdaddress ::1
keyfile /etc/chrony.keys
commandkey 1
generatecommandkey
logchange 0.5
logdir /var/log/chrony
# 重启服务
systemctl restart chronyd
# 设置时区
timedatectl set-timezone Asia/Shanghai进程及文件最大打开数
vim /etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800sshd 配置
vim /etc/ssh/sshd_config
# IP
ListenAddress 0.0.0.0
# DNS解析
UseDNS no
# 日志级别
LogLevel INFO工作目录
# 操作目录
operational_CephCluster
# 备份目录。对备份目录进行分类,并按照日期进行命名
backup_CephCluster
# 临时应用
temp_CephCluster禁用 swap 分区
# 关闭 swap 分区
swapoff -a
# 注释 fstab swap 分区自动挂载
# /dev/mapper/centos-swap swap
# 临时生效配置
echo 0 > /proc/sys/vm/swappiness
# 修改内核参数,见14.8内容12.7 网络配置
光纤网卡型号为
Intel 82599ES,电口网卡型号为Intel X540-AT2。可使用lspci命令查看 PCIE 网卡设备,lspci -s {00:00.0} -vvv命令查看设备详细信息。

# 点亮网口指示灯,需拔掉网线
ethtool -p {if-name}网卡信息

网卡绑定
创建 bond0
# 创建 bond0 设备
nmcli connection add type bond bond.options "mode=6,miimon=100" con-name bond0 ifname bond0
# 配置 IP 地址
nmcli connection modify bond0 ipv4.method manual ipv4.addresses 10.255.0.1/24
# 修改 MTU 大小
nmcli connection modify bond0 mtu 9216
# 禁用 ipv6
nmcli connection modify bond0 ipv6.method ignore
# 重启连接
nmcli connection up bond0
# 添加网卡接口到 bond0
nmcli connection add type ethernet ifname enp94s0f1 con-name bond0-enp94s0f1 master bond0
nmcli connection add type ethernet ifname enp95s0f1 con-name bond0-enp95s0f1 master bond0创建 bond1
# 创建 bond0 设备
nmcli connection add type bond bond.options "mode=6,miimon=100" con-name bond1 ifname bond1
# 配置 IP 地址、mtu、禁用 ipv6
nmcli connection modify bond1 ipv4.method manual ipv4.addresses 10.255.1.1/24 mtu 9216 ipv6.method ignore
# 重启连接
nmcli connection up bond1
# 添加网卡接口到 bond1
nmcli connection add type ethernet ifname enp94s0f0 con-name bond1-enp94s0f0 master bond1
nmcli connection add type ethernet ifname enp95s0f0 con-name bond1-enp95s0f0 master bond1创建 bond2
# 创建 bond2 设备
nmcli connection add type bond bond.options "mode=6,miimon=100" con-name bond2 ifname bond2
# 配置 bond2 参数
nmcli connection modify bond2 ipv4.method manual ipv4.addresses 10.53.120.12/22 mtu 9216 ipv6.method ignore ipv4.dns "10.1.0.1 223.6.6.6" ipv4.gateway 10.53.120.1
# 添加从设备
nmcli connection add type ethernet ifname enp175s0f0 con-name bond2-enp175s0f0 master bond2
nmcli connection add type ethernet ifname enp175s0f1 con-name bond2-enp175s0f1 master bond212.8 内核参数
# 编辑 sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_syncookies = 0
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
kernel.pid_max = 4194303
vm.swappiness = 0 # 禁用 swap 分区
# 加载文件
sysctl -p 12.9 磁盘 I/O 优化
read_ahead_kb ,其运行时参数值在 /sys/block/sda/queue/read_ahead_kb 文件中。
scheduler,其运行时参数值在/sys/block/hda/queue/scheduler 文件中。
具体参数含义不在赘述,详情请参考 RedHat 官方文档。
# 开机执行脚本自动配置,在 rc.local 脚本执行,配置 rc.local 可执行权限,/usr/bin/tuning_for_disk.sh set。将 tuning_for_disk.sh 放置于 /usr/bin 目录下。
/usr/bin/tuning_for_disk.sh set
# 脚本如下
#!/bin/bash
# tuning disk read_ahead_kb and scheduler
if [ $1 == "set" ]; then
for I in `echo {a..z}`;do
echo "2048" > /sys/block/sd$I/queue/read_ahead_kb
echo "cfq" > /sys/block/sd$I/queue/scheduler
done
elif [ $1 == "cat_read" ]; then
echo "Val block_name"
for I in `echo {a..z}`;do
echo "`cat /sys/block/sd$I/queue/read_ahead_kb` sd$I"
done
elif [ $1 == "cat_scheduler" ]; then
echo "Val block_name"
for I in `echo {a..z}`;do
echo "`cat /sys/block/sd$I/queue/scheduler` sd$I"
done
elif [ $1 == "--help" ]; then
echo "set | cat_read | cat_scheduler"
else
echo "error"
fi12.10 网络性能测试
网络性能可以有几个性能标准:
可用性、带宽(传输最大速率)、吞吐量(实际速率)、延迟(发送和接收之间的时间间隔)、抖动(接收处延迟的变化)、误码率(发送总位数除以损坏位数的百分比)。
可用性测试
ping -I|-c|-s x.x.x.x
# 示例。-c 指定发送 1000 个包,-I 指定指定网络的设备名称,-s 指定每次发送数据包的大小。观察连通性可检测可用性和丢包率和 time 参数可反映大致响应时间。
ping -c 1000 -I bond1 10.255.1.2其他标准测试
iperf 网络性能测试工具主要可测试网络中不同协议的传输能够达到的最大带宽值。支持 TCP、UDP 协议。测试报告中包括带宽值、丢包率等其他参数。iperf 最初由 NLANR/DAST 开发,iperf3 主要由 ESnet / Lawrence Berkeley National Laboratory 开发,是对 NLANR/DAST 开发的最初的版本的重新设计,此版本中包含了其他工具诸如 netpref 中的许多功能。
iperf 工具使用简单,参数较少,就不一一罗列,移步官方文档使用手册参考具体参数使用。
13. ceph-volume
ceph-volume 是一个将 LVM 逻辑卷部署为 OSDs 所用的数据设备的命令行工具。从 Ceph 13.0.0 版本开始,不再推荐使用 ceph-disk 工具,预示着此工具将被弃用。此外,还强烈建议将 ceph-disk 管理的 OSDs 迁移为 ceph-volume 托管。迁移方式包括使用 ceph-volume simple 子命令接管和重新部署 OSDs。
无论使用 ceph-disk 还是 ceph-volume 部署 OSD,在激活 OSD 时,都需要明确知道一些信息用来激活和发现设备例如 DATA 设备、DB 设备、WAL 设备、是否加密等等。ceph-disk 处理的方式是使用 UDEV 规则匹配 GUID ,然后由 ceph-disk 和 systemd-udevd 共同执行激活 OSD,这个过程非常不可靠且可能消耗很多时间,导致 OSDs 无法快速激活甚至无法激活。此外,ceph-disk 部署时是将磁盘创建为 GTP 分区,并标记很多复杂的特殊的标记。而 ceph-volume 工具利用 LVM tags 特性,用来激活和发现 OSDs 设备,这也带来另外一个好处是可以使用基于 LVM 的技术,例如 dm-cache 等。
官方宣称:LVM 的使用并没有发现带来任何性能上的损耗。(事实上也好理解,ceph-volme 仅仅使用是 tag 功能,更便于管理和发现激活设备)
systemd
systemd unit 使用 OSDs 的 id 和 uuid 作为传入服务脚本执行的参数,系统启动时,这些 systemd unit 将被执行并通过 ceph-volume 子命令激活相应的设备。
prepare
LVM 逻辑卷需要在 prepare 过程之前提前创建,此过程会给逻辑卷元数据区域写入 tag 信息。--bluestore 子命令可接受物理磁盘、分区、LVM逻辑卷,对于 block 设备如果提供物理磁盘设备则会自动创建一个逻辑卷,以 <CephName-fsid>/osd-block-<osd_fsid> 命名卷组和逻辑卷。对于 db 和 wal 设备,则不会创建逻辑卷,因为其可以使用单独的设备而不使用逻辑卷的 tag。
ceph-volume lvm prepare --bluestore --data <vg_name>/<lv_name>|/path/to/dev_name --block.db <vg_name>/<lv_name> --block.wal <vg_name>/<lv_name>activate
systemd unit (例如:ceph-volume@lvm-0-8715BEB4-15C5-49DE-BA6F-401086EC7B41) 随系统启用之后启动并执行,通过 unit 名称传递 id 和 uuid 两个参数,之后调用 ceph-volume 程序并通过 id 和 uuid 匹配 OSDs 设备,然后查找 LVM tags,通过 LVM tags 执行几个步骤:
创建并挂载 tmpfs 文件系统到
/var/lib/ceph/osd/<cluster_name-osd_id>目录下。重新生成所有OSD 目录下所需的所有文件。
ceph-bluestore-tool prime-osd-dir --dev /dev/<VG_NAME>/<LV_NAME> --path /var/lib/ceph/osd/<cluster_name-osd_id>确认 OSD 所用的设备处于可用状态,创建设备软链接,每次激活都会重新创建软链接。
启动
ceph-osd@<ID>systemd unit 启动 OSDs 进程。此过程由 ceph-volume lvm trigger 子命令处理,该子命令仅负责解析来自 systemd 和启动的元数据,然后分派到 ceph-volume lvm activate 并继续激活。
# 手动激活所有 OSD,可重复执行
ceph-volume lvm activate --all其他子命令
ceph lvm list --format json|pretty
ceph-volume lvm zap <VG_NAME>/<LV_NAME> |--destroy