
- Ceph 文档

Ceph 文档
1. Ceph 基础
1.1 Ceph简介
Ceph是加州大学圣克鲁兹分校的Sage Weil博士论文的研究项目 ( 2004年6月份 ),是一种软件定义存储的技术方案(Software Defined Storage,SDS)。ceph 集群可以同时提供 Object Storage、Block Storage、File System三种存储方式,ceph 完全去中心化的设计理念是高可扩展和高性能实现的基础。
1.2 专业术语
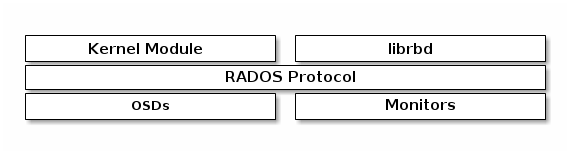
OSD(Object Storage Device):负责相应客户端的数据请求组件,并返回数据的组件,在Ceph集群中, OSD可以有多个。数据复制、恢复、回填、重新调整、和其他OSD进程通信并报告 Monitor。
PG(Placement Groups):归置组, 一个逻辑概念。ceph 集群以对象为单位存储数据,为了更好的实现数据动态平衡及随机分布,因此一个对象的大小不适合过大,因此即便是一个很小的 ceph 集群中也存在成千上万的对象数量,而在如此小的粒度上管理对象成本是非常昂贵的,因此引入 pg 的概念,即 pg 是一些对象的集合。此外,pg 的引入使得在数据和 osd 之间形成一个中间层,降低耦合度。
RADOS(Reliable Autonomic Distributed Object Store):是 ceph 集群实现所有重要功能的组件,主要实现数据存储的组件。
Librados:它是对 RADOS 存储集群进行的抽象和封装,并向上层提供 API,支持 C++、Java、Python、Ruby 和 PHP 等编程语言。
CRUSH(Controlled Replication Under Scalable Hashing):数据分发算法。Ceph 将数据保存为存储池内的对象,Ceph 能够使用算法计算出那个归置组(PG)持有指定的那些对象(Object),然后进一步计算 PG 属于那个 OSD 守护进程。
RBD(RADOS Block Device):Ceph 用于提供块存储的组件,数据以顺序条带化的形式存放在 ceph 集群中的多个 OSD 之上,有多种方式集成 RBD。
RGW(RADOS Gateway):向外提供对象存储的组件。Ceph RGW(即RADOS Gateway)是 Ceph 对象存储网关服务,是基于 LIBRADOS 接口封装实现的,对外提供存储和管理对象数据的 Restful API。对象存储适用于图片、视频等各类文件的上传下载,可以设置相应的访问权限。目前 Ceph RGW 兼容常见的对象存储 API,例如兼容绝大部分 Amazon S3 API,兼容 OpenStack Swift API。
MDS(RADOS Metadata Server):Ceph提供元数据存储的组件。只在Ceph提供文件系统的服务时使用 MDS 节点。
CephFS(Ceph File System):Ceph提供文件系统的组件。
Monitor:进程名称为
ceph-mon。 Ceph Moniter节点负责集群状态的映射,包括 Monitor map、OSD map、CRUSH map。这些映射是 ceph 守护进程相互协调所需要的关键重要信息,Monitor 同时也负责管理进程之间以及客户端的认证工作。通常需要三个节点保证 Monitor 的高可用。Manager: 进程名称为
ceph-mgr。ceph-mgr 进程负责追踪和监控当前集群运行状态和参数指标,包括存储使用率、当前性能指标、系统负载等。此外,还负责托管基于 Python 的 ceph Dashboard 和 REST API。
1.3 硬件推荐
当在规划一个 Ceph 集群时需要充分考虑硬件的选型和未来可能存在的性能问题。主要从以下几个方面进行规划和衡量:
CPU
Cpeh 集群 MDS(RADOS Metadata Server) 元数据服务需要动态分配负载,这会占用大量的 CPU,因此元数据服务器相对需要更强大的 CPU 处理能力。Ceph OSD 负责数据复制、恢复、回填、重新调整、以及其他OSD进程通信并报告监视器,因此也需要 CPU 强大的 CPU 处理能力。Monitor 节点仅仅维护集群映射的主副本,相对不会占用太多的 CPU 。
RAM
Monitors(ceph-mon) and Manager(ceph-mgr) 进程所需要的内存和集群规模大小成正相关,大规模集群通常5-10GB内存,可通过mon_osd_cache_size or rocksdb_cache_size两个参数进行配置。
Metadata Server(ceph-mds) 进程占用内存大小取决于为其配置缓存的元数据大小,通常最小为 1GB,可使用mds_cache_memory进行配置。
osd(ceph-osd) 进程在使用 BlueStore 存储后端时默认占用 3 - 5GB 内存,也可以使用 osd_memory_target 参数进行配置。使用旧版 FileStore 存储后端时,操作系统页面缓存用于缓存数据,因此通常不需要进行调整,并且 OSD 内存消耗通常与系统中每个守护程序的 PG 数量有关。
机械硬盘
OSD需要有足够的存储空间来存储数据对象,推荐最小的硬盘为 1TB,在一定范围内存储空间越大,性价比越高,因此推荐空间较大的单个硬盘。但并不是空间越大越好,因为 OSD 所对应的存储空间越大,在数据回填、恢复、重平衡过程需要更大的内存且消耗更多的时间,通常情况下 1TB 硬盘空间需要 1GB 内存。此外,不建议在单个硬盘上运行多个 OSD。
机械硬盘可能会受其物理限制影响整个 Ceph 集群性能,因此建议对于操作系统和 OSD 进程等尽可能使用单独的硬盘。此外,如果存储引擎元数据及日志数据和对象数据存储在同一个硬盘上时,会增加写入时间,Ceph 必须先写入日志才能确认写入数据。
建议:1、分别在单独的硬盘上运行操作系统、OSD、OSD 元数据。2、使用相同配置的硬盘能够简化配置和利于故障排查。3、尽量避免使用 raid 来组织硬盘,因为 raid 会带来额外的性能损耗,降级的 raid 还会带来性能浪费。
固态硬盘
固态硬盘可以减少随机访问时间和读取延迟,增加吞吐量,能够增加上百倍的性能。在 Ceph 集群中,给日志记录使用固态硬盘可大大增强集群性能。filestore 存储引擎模式下,Ceph集群的 OSD 记录日志通常保存在 /var/lib/ceph/osd/$cluster-$id/journal 路径下,可以单独将 SSD 分区挂在至此路径下。此外,使用 CephFS 的场景下,也建议将元数据存储在 SSD 存储介质上。
注意事项:
- 写密集型:日志记录及元数据是写密集的场景,因此对于日志的需要尽可能使用质量好且性能更好的固态硬盘。
- 顺序读写:当有多个 OSD 的日志写到固态硬盘上时,需要考虑 SSD 的顺序读写性能。
- 分区对齐:保证 SSD 分区对齐,避免性能丢失。
- 吞吐量:OSD 硬盘的总吞吐量之和不超过客户端读取或写入数据所需要的网络带宽。(存疑)
- 对于高 iops 的优化场景,建议每 4 个 osd 配置一个 NVMe SSD,或以 1:4/5 的数量比例配置 SSD。对于高吞吐量场景,1:4/5 的比例配置一个 SSD,或者 1:12/18 的比例配置 MVMe 配置 SSD。
- 在条件允许的情况下,给 ceph-mon 进程的数据目录配置单独的 SSD 分区。
- 硬盘控制器吞吐量也能会影响到整体集群性能,选择硬件时要谨慎选择。
网络
- 建议每个节点配置两个万兆网卡,避免网卡成为数据传输的瓶颈。两个网卡一个作为集群前端网络,处理客户端请求;一个作为集群后端网络,处理数据传输,此外为了安全起见,不连接到互联网。通常在万兆网络的架构中,复制 1TB 和 3TB 数据需要大约分别需要 20 分钟和 1 个小时。此外,建议在网络中使用巨型帧。
- 网络带宽尽可能的能够处理节点上磁盘的 I/O 流量。
故障域(failure domain)
故障域为一个区域范围的概念,这个范围可以是一个 osd、host、chassis(机箱)、rack(机架)、row(机柜排)、pdu(配电柜)、pod(多个机柜排)、room(机房)、datacenter(数据中心)、region(区域)、root(根、最顶级)。
理解:如果将故障域设置为 host,则同一个数据对象的副本不会同时放到同一台 host 的 osd 上,保证如果某一台 host 故障的情况下,数据不丢失。同理,如果将故障域设置为 osd,则一个数据对象的几个副本可能放置到同一台 host 的不同 osd 上,如果此 host 故障,则这个数据就会丢失。
确定ceph使用场景
考虑读写带宽、存储容量、IOPS 三个指标。计算提供给客户端总带宽、总 IOPS ,然后叠加计算考量组网负载能力。
- 高 IOPS 。在云计算场景中,更需要高 IOPS 的存储后端,例如将 MySQL、MariaDB 等数据库运行在虚拟机中。因此,意味着也需要更好性能的硬件支持,例如 15K rpm 的 SAS 硬盘和更快的 SSD 作为日志盘来支撑更快的写操作,SSD 能够大幅度提高写入性能。
- 高吞吐量。高吞吐量的场景下,适用于图形、音视频等内容的存储访问,需要有可接受高吞吐量的硬件支持。
- 高存储容量。可使用价格低廉的 SATA 盘并和 journal 共使用一个硬盘。
存储密度
尽量避免在在规模较小的集群中使用过高存储密度,通常单节点的容量占总存储容量的 20% 以下,如果在小型集群中使用高密度的存储容量,可能在硬件故障期间数据恢复时造成网络过载。此外,journal/存储引擎元数据盘和数据盘的比例应小于 1:5 的比例。journal/存储引擎元数据的容量占比为数据盘的 1% - 4% 之间。
2. Ceph 架构
2.1 Ceph 各组件介绍
参考 1.2 专业术语解释
ceph 可以在一个存储集群系统中提供 Object、Block、File System 三种存储方式。ceph 是一个可靠性高,易于管理且是一个开源的软件定义存储的软件系统。它能够轻松的完成企业或公司的 IT 基础设施并能够管理海量数 据。一个稳定的 ceph 存储集群能够轻松的应对成千上万的客户访问 PB 级数量的数据。集群中的每个节点上运行智能守护进程,节点之间互相通信动态的平衡数据和复制数据。
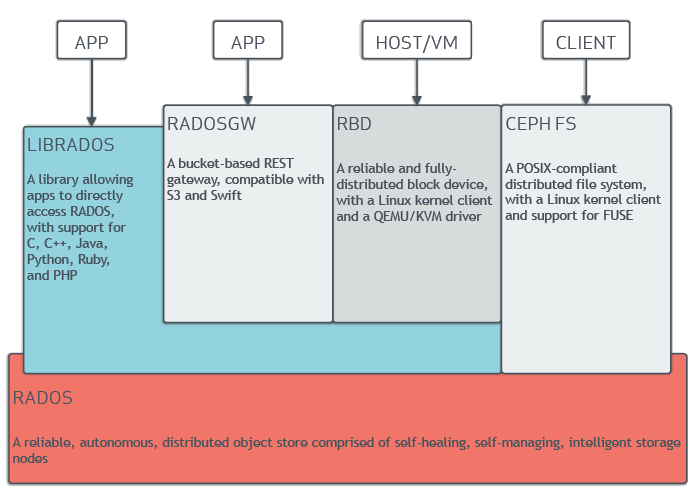
RADOS (Reliable Autonomic Distributed Object Store)
是 Ceph 集群实现所有重要功能的组件,主要实现数据存储的组件。
LIBRADOS
它是对 RADOS 组件进行的抽象和封装,并向上层提供 API,支持C、C++、Java、Python、Ruby和PHP等编程语言。
RADOSGW (RADOS Gateway)
Ceph 向外提供对象存储的组件。构建在 librados 之上的对象存储接口。提供了与 Amazon S3 和 OpenStack 兼容的 RESTful API。
RBD (RADOS Block Device)
Ceph 用于提供块存储的组件,同样是构建在 librados 之上的存储接口。将数据顺序条带化的形式存放在 Ceph 集群中的多个 OSD 之上。RBD 驱动被集成在 Linux 内核,此外还有多种集成使用方式。
CephFS (Ceph File System)
Ceph提供文件系统的组件。
2.2 Ceph Storage Cluster
Ceph 基于 RADOS 提供了强大的可扩展性。ceph 节点上运行最重要的两个守护进程是 ceph-mon 及 ceph-osd。ceph-mon 主要负责维护集群映射、monitor 节点的高可用性、客户端从 monitor 节点检索集群映射关系。Ceph-osd 守护进程检查自己的状态和其他 OSD 的状态,并向监视器报告。客户端及 ceph-osd 进程通过 CRUSH 算法有效计算数据的存储位置,而不依赖于中心元数据服务器。
2.2.1 数据存储
ceph 集群的客户端无论通过块存储、对象存储、文件系统存储甚至是基于 librados 自定义实现的存储请求,ceph 集群都将数据存储为对象。每个对象都对应于文件系统之上的文件,文件又存储在对应的磁盘设备上。ceph-osd 负责数据在磁盘上的读/写操作。
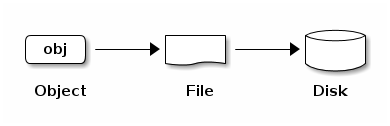
ceph-osd 守护进程将所有数据作为对象存储在一个平面的命名空间中,从而避免了目录层级结构。每一个对象由 ID(在所有的对象当中是唯一的)、Binary Data、Metadata(键值对元数据) 组成。Metadata 的键值数据则完全由客户端来决定,例如 CephFS 的客户端会使用元数据来存储文件属性、所有者、时间戳等。

对象存储实现方式
Cpeh 集群中 OSD 实现存储方式都为 ObjectStore,ObjectStore 实现方式有两种。从 Luminous 12.2.z 版本之后,后端使用实现对象存储的方式默认是 BlueStore。在 Luminous 之前,使用的对象存储方式都是 FileStore。
BlueStore功能特点
- 直接管理使用存储设备。避免了本地文件系统如 XFS 等复杂抽象层对性能的限制。
- 元数据的管理存储使用 RockDB。RockDB 是一种嵌入式 Key-Value 数据库,相对于传统的关系型数据及其他嵌入式数据库有着更好的性能表现。
- 更强大的元数据和数据的校验和机制。默认写入 BlueStore 的所有数据都需要一个或多个校验和进行校验保护,返回给用户的元数据和数据都经过严格的校验和验证。
- 压缩机制。写入的数据在存储到磁盘时可以选择将数据进行压缩。
- 多设备分层使用。BlueStore 允许单独的将内部日志或元数据写入高速的存储设备上去。
- 写时复制,copy-on-write。Ceph 中 RBD 和 CephFS 的快照功能都依赖于高效的写时复制功能。
FileStore 与 BlueStore 比较
- FileStore 依赖于抽象的文件系统。
- FileStore 使用 LevelDB 管理和存储元数据。
- 官方只建议在 XFS 文件系统之上使用 FileStore。
2.2.2 扩展性和高可用性
在传统架构中,客户端与中心组件(例如,网关,代理,API等)通信,该集中式组件充当复杂系统的单个入口点。这对性能和可扩展性都施加了限制,同时引入了单点故障(即,如果集中式组件发生故障,整个系统也会出现故障)。Ceph 消除了集中式网关,使客户端能够直接与 Ceph OSD Daemons 进行交互。Ceph OSD Daemons 在多个 Ceph 节点上创建对象副本,以确保数据安全性和高可用性。Ceph 还使用一组监视器来确保高可用性。CRUSH 的算法的使用,是消除集中式的最重要方法。
CRUSH 介绍
Ceph 客户端和 Ceph OSD 守护进程都使用 CRUSH 算法有效地计算有关对象位置的信息,而不必依赖于中心服务器。CRUSH 提供了相对于传统更好的数据管理机制,并在集群中通过干净的分发任务到客户端和 OSD 守护进程来实现大规模扩展。CRUSH 通过智能的分发数据来确保集群中数据的可用性和扩展弹性,这种方式更适用与大规模的集群。
Cluster MAP
Ceph 集群正常运行依赖于 5 个 Map,这 5 个 Map 统称为 Cluster Map,包括:
- Monitor Map:包含信息有 cluster-fsid、节点IP地址信息、当前 Map 版本、创建时间、上次更改时间。可以使用
ceph mon dump命令查看。
- OSD Map:包含信息有 cluster-fsid、创建时间、上次更改时间、存储池信息、pg_num、osd 状态、告警阈值、flag 等。可以使用
ceph osd dump命令查看。
- CRUSH Map:包含信息有存储设备信息、故障域、数据存储结构。查看 CRUSH Map 方法如下:
# 导出 CRUSH Map ceph osd getcrushmap -o crushmap.file # 反编译 CRUSH Map 文件 crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}
- MDS Map:包含信息有 MDS map 版本、创建时间、metadata pool 信息、mds server 状态信息。使用
ceph fs dump命令查看。
- PG Map:包含 PG 版本,时间戳,最后一个 OSD 映射时期,完整比率以及每个放置组的详细信息,例如 PG ID,Up Set,Acting Set,PG 的状态(例如,活动+清除),以及每个池的数据使用统计信息。
Monitor 高可用性
ceph 客户端在读取或写入数据时,首先和 Monitor 节点通信以获取集群映射的最新副本。ceph 集群可以使用单个 Monitor 节点,但这引入单点故障因素,如果一旦 Monitor 节点故障,则整个集群将处于不可用状态。为了保证 Monitor 的高可用性,ceph 集群支持多个 Monitor 节点共同保证集群的高可用性。在 Monitor 集群中,网络延迟或故障都有可能造成一个或多个 Monitor 节点维持的 Map 信息落后于集群当前煮状态。为了保证集群 Map 信息的一致性,Ceph 使用 Paxos 算法保证集群当前状态处于一致性。
认证高可用性
为了识别用户并防止中间人攻击,Ceph 提供了 cephx 身份验证系统来验证用户和守护进程。注:cephx 协议不解决传输中的数据加密(例如,SSL / TLS)或静态加密。
Cephx 使用共享密钥进行身份验证,这意味着客户端和监控集群都拥有客户端密钥的副本,而无需透露密钥。认证协议使得双方能够彼此证明他们具有密钥的副本而不泄露密钥。为了保护数据,该认证系统对运行 Ceph 客户端的用户进行身份验证。cephx 协议原理和 Kerberos 类似。
当客户端和 Monitor 发起请求后, Monitor 返回一个认证信息其中包含获取 ceph 服务的会话密钥,此会话密钥本身使用用户的永久密钥加密,因此只有用户才能从 Ceph 监视器请求服务。然后,客户端使用会话密钥从监视器请求其所需的服务,监视器为客户端提供一个票证,该票证将客户端验证到实际处理数据的OSD。
认证过程
1. Monitor 进行身份认证,Client 首先通过用户名向 Monitor 发起请求;2. Monitor 会生成一个会话密钥并使用与用户名相关联的密钥对会话密钥进行加密;3. Client 使用与 Monitor 共享的密钥对会话密钥进行解密,此会话密钥标识当前与 Monitor 通信的客户端;4. 之后,客户端使用会话密钥签名的用户向 Monitor 发起一个凭证请求;5. Monitor 生成有一个凭证并使用用户的密钥进行加密之后返回给客户端;6. 客户端对这个凭证进行解密,在之后的整个通信过程中客户端都使用此凭证来签署和 osd 及元数据服务器的请求。
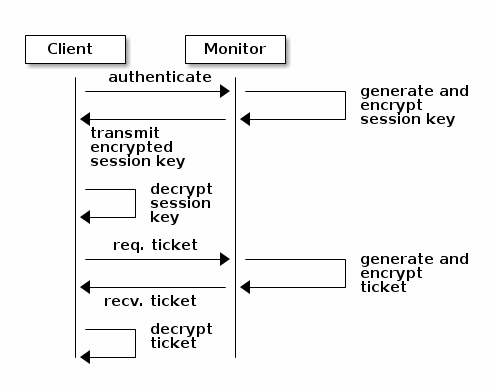
cephx 协议对 client 和集群之间的同行进行身份验证,集群中的其他服务,例如 osd、osd 等可以共享客户端密钥信息。在对客户端认证之后,客户端都使用认证之后获得的凭证进行验证。
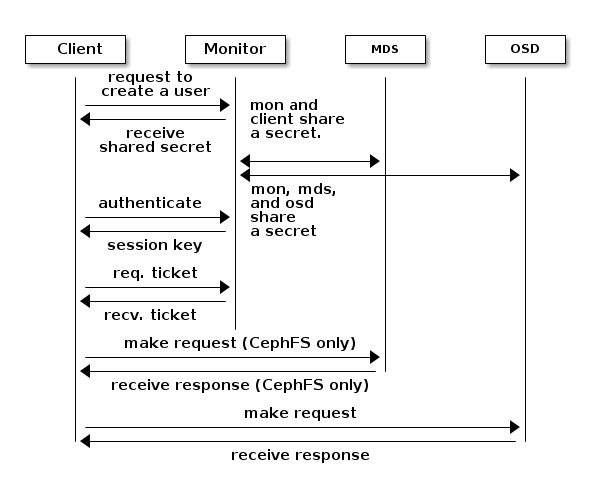
2.2.3 智能守护进程
在传统的集群架构中,中心服务器不仅是单点故障,而且在大规模用户场景下中心服务器可能成为性能瓶颈。此外,中心服务器通过双向调度的方式为客户端提供服务。在 ceph 集群架构中,ceph-osd 进程之间能够互相通信并感知并监控彼此的状态,ceph 集群客户端能够直接和 ceph-osd 进程进行交互,这就避免了中心服务器的引入带来的性能瓶颈问题。ceph 集群架构有以下几个优势:
- ceph-osd 直接和客户端交互。避免的中心服务器单点故障问题即性能瓶颈。
- osd 成员健康状态监控。monitor 节点监控 osd 的健康状态,如果 monitor 节点在一段时间内未检测到 osd 是否可用,则 monitor 认为该 osd 故障。此外,osd 之间也会互相监控邻近 osd 的健康状态。
- 数据清洗。ceph-osd 进程可以对数据进行清洗,也就是说,ceph-osd 守护进程可以将一个放置组中的对象元数据与存储在其他OSD上的放置组中的副本进行比较。清洗操作通常每天都会执行,ceph-osd 守护进程还通过逐位比较对象中的数据来执行更深层次的清理。深度清洗(通常每周执行一次,主要检测存储设备上的坏扇区。
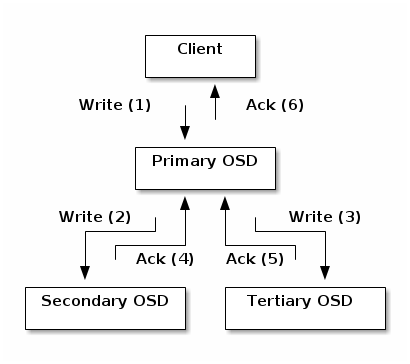
- 副本。与 Ceph 客户端一样,ceph-osd 守护进程也使用 CRUSH 算法,但 ceph-osd 守护进程使用它来计算应存储对象副本的位置(以及重新平衡)。
客户端将对象写入主 OSD 中的标识的放置组。然后,具有其自己的 CRUSH 映射副本的主 OSD 识别用于复制的二级和三级 OSD,并将该对象复制到二级和三级 OSD 中的适当放置组(与另外的副本一样多的 OSD),并响应客户端确认对象已成功存储后。
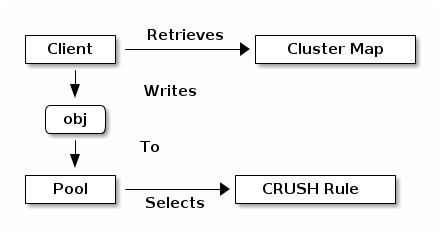
2.3 动态数据管理
2.3.1 Pool
Ceph 存储系统支持 “pool” 的概念,“pool” 是对于存储对象的逻辑分区。Ceph 客户端从 Ceph Monitor 检索集群映射,并将对象写入 pool。池的大小或副本数量,CRUSH 规则和放置组的数量决定了 Ceph 如何放置数据。
可以对 pool 的属性进行设置,例如允许那些用户访问、pg 数量、CRUSH 规则等。
2.3.2 PG 和 OSD 映射
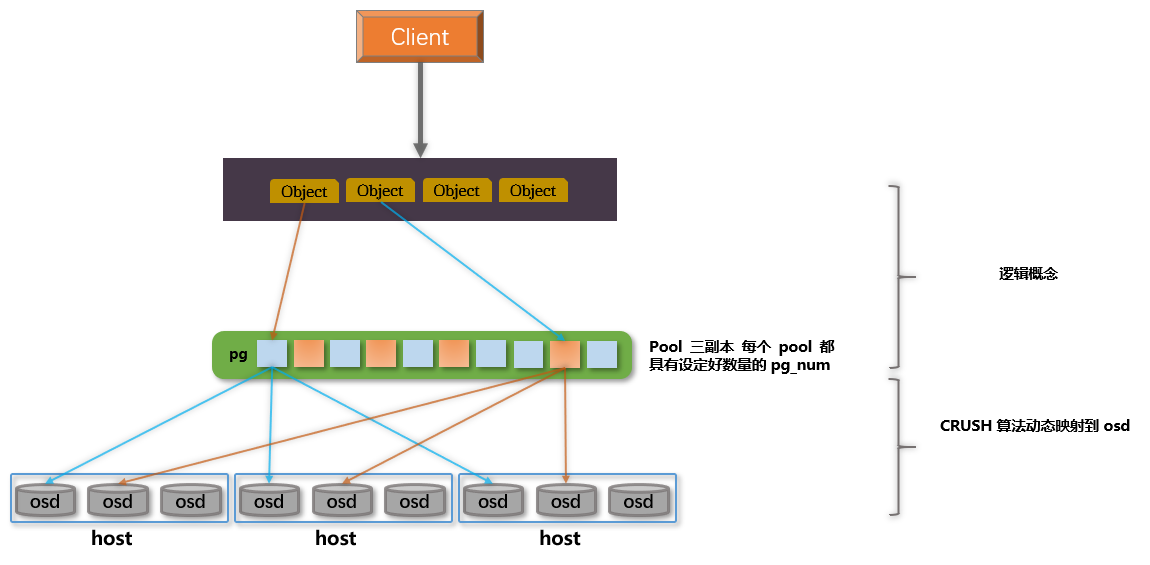
Ceph 集群将 object 映射到 pg ,再将 pg 映射到 osd 之上,使得在数据存储的 osd 和客户端建立了一个间接层,降低了耦合度,实现了 osd 之上的数据重平衡。CRUSH 算法将每个对象映射到一个 pg,然后将每个 pg 映射到一个或多个Ceph OSD守护进程。Pool、PG、都是逻辑概念,并不存在,Object 是实实在在保存到磁盘的数据。
2.3.3 PG ID 计算
当客户端连接一个 Monitor 后,它将检索集群最新的映射,此时客户端可以知道集群中有多少个 Monitor 和 osd 以及元数据服务器的信息。但客户端对 object 一无所知。object 的位置是实时进行计算出来的。其计算过程公式:Pool ID + HASH(Object ID) % pg_num ===>PG_ID:
- client 输入 Pool ID 和 Object ID
- ceph 获得 Object ID 之后计算 object 的哈希值
- ceph 将 Object ID 对 pg_num 取模
- Ceph 根据池名称获取池 ID(例如,“Liverpool”= 4)
- Ceph 将 Pool ID 添加到 PG ID(例如,4.58)
通过计算的方式来定位对象的位置比对象查询的效率要高很多,CRUSH 算法允许客户端计算应存储对象的位置,并使客户端能够联系主 OSD 以存储或检索对象。
2.3.4 Peering and sets
在前面的部分中,我们注意到 ceph-osd 守护进程会检查彼此的心跳并向 Ceph Monitor 报告。ceph-osd 守护进程所做的另一件事叫做 “peering”,即将存储放置组(PG)的所有 OSD 与该PG 中所有对象(及其元数据)的状态达成一致(即所有对象副本一致)。
Ceph 存储集群旨在存储至少两个对象副本(即size= 2),这是数据安全的最低要求。为了数据的高可用性,Ceph 存储集群应该存储一个以上的对象副本(例如,size = 3 和 min size = 2),以便它可以在降级状态下运行,同时保证数据安全。
例如:在一组 acting set 中包含 osd.25,osd.32 和 osd.61,如果第一个 OSD osd.25 是 Primary,如果该OSD失败,则 Secondary osd.32 将成为主节点,并且从 acting set 中删除 osd.25。
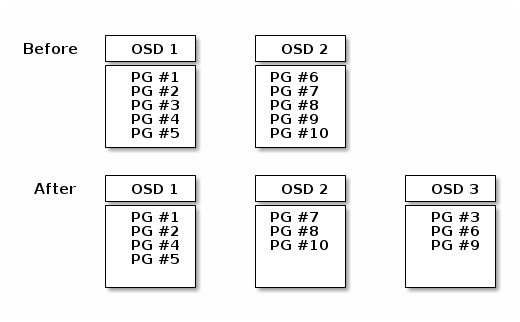
2.3.5 Reblancing
将 Ceph OSD 守护程序添加到 Ceph 集群时,集群映射将重新对 PG 和 OSD 之间映射关系进行更新,会有新的 pg 迁移到新的 osd 上。
2.3.6 纠删码
在纠删码池中,ceph 将每个 object 存储为 K+M 个数据块,K 为数据块的数量,M 为纠删码块。
纠删码写过程:
当一个名为 NYAN 其中包含 ABCDEFGHI 内容的对象写入 pool 时,纠删码功能将内容分为三块,即将内容分成三个数据块,ABC、DEF、GHI,同时生成两个纠删码块,YXY、QGC。每个数据库都存放在一组 acting set osd 中。在创建块的过程中,必须保留创建块的顺序,并保存在对象的属性 shard_t 当中。
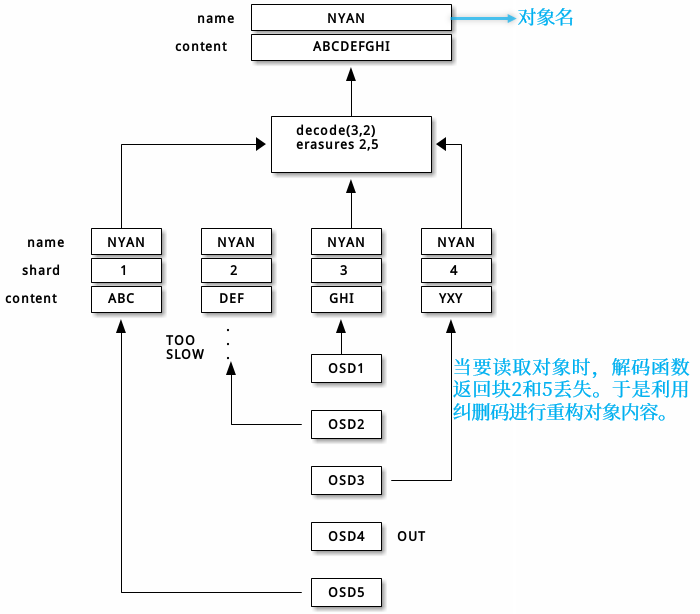
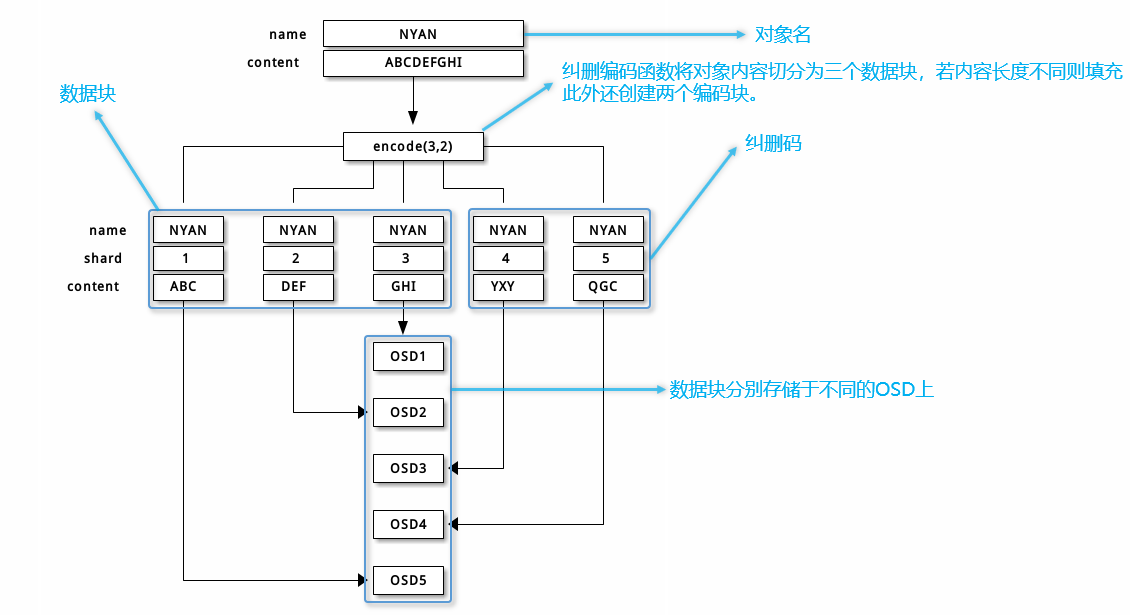 利用纠删码恢复过程:
利用纠删码恢复过程:
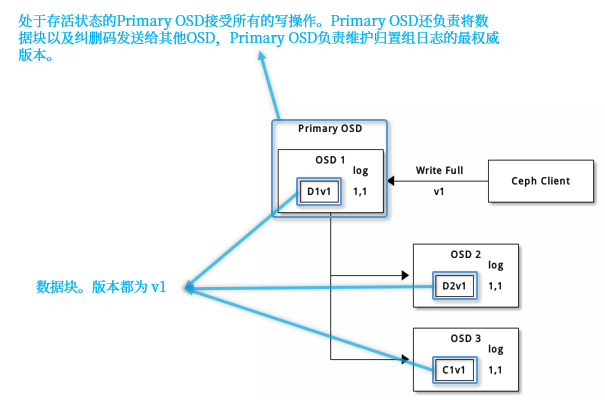
纠删码池数据修改过程:
在擦除编码池中,up set 中的主 OSD 接收所有写操作。它负责将有效载荷编码为 K + M 个块,并将其发送到其他 OSD。它还负责维护放置组日志的权威版本。
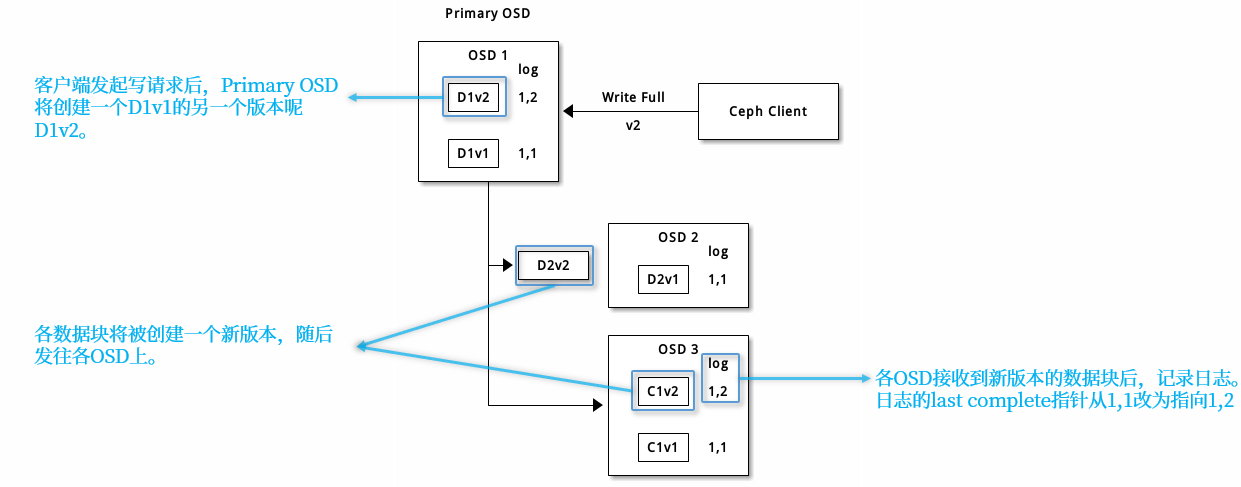
当数据更新完成之后,旧版本的数据块将被删除。
2.3.8 缓存分层
缓存层为 Ceph 客户端提供了更好的 I/O 性能,高速缓存分层涉及在高速存储设备上创建缓存层池,以及配置存储在相对较慢存储设备上的后端存储池。Ceph 集群负责对象的存放位置,并且分层代理(缓存层)确定何时将对象从缓存层刷新到后端存储层。因此,缓存层和后端存储层对Ceph 客户端完全透明。
2.4 数据条带化
存储设备具有吞吐量限制,这会影响性能和可伸缩性。因此,存储系统通常支持在多个存储设备上条带化存储连续的数据以提高吞吐量和性能。最常见的数据条带形式来自 RAID。与 Ceph 条带化最相似的 RAID 类型是 RAID 0 或 “条带卷”。Ceph 的条带化提供了 RAID 0 条带化的吞吐量,RAID 1 的可靠性和更少的恢复时间。Ceph 提供三种类型的客户端:Ceph Block Device,Ceph Filesystem 和 Ceph Object Storage 。Ceph 客户端将数据存储时转换为对象,以便存储在Ceph存储集群中。
在 Ceph 存储集群内存储的对象是没条带化的。对象存储,块存储和文件系统将其数据分散到多个Ceph存储集群对象上。Ceph通过 librados 直接写入 Ceph 存储集群的客户端必须为自己执行条带化(并行I / O)以使用此功能。
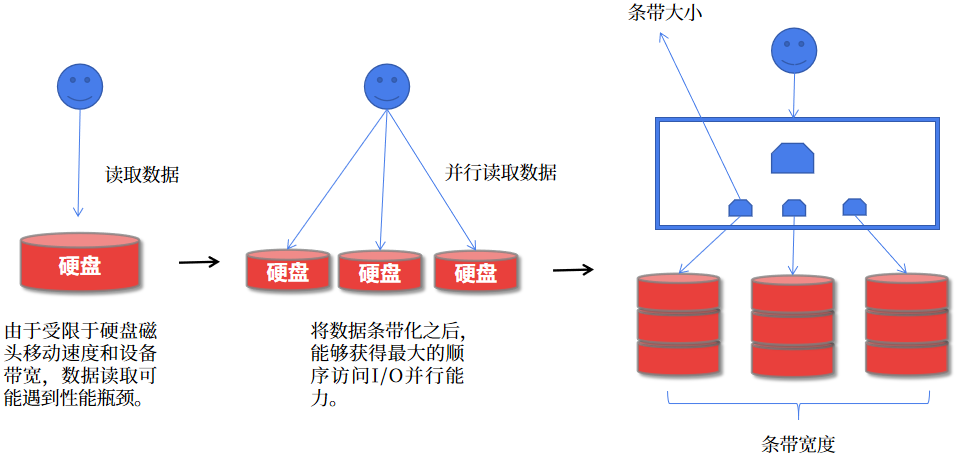
librados 通过 OSD 写入的数据单元是 strip。在 ceph 集群中是以 object为条带进行写入的,即条带大小为 object 的大小,默认为 4M,顺序将数据写入一个 object,直到这个 object 被写满,再去到另一个 object 上进行写入,然而此种方式在小规模场景下可以提高一定的并行写入性能,例如对象存储、CephFS。但在大规模数据量的场景下,这种条带化方式并不能够最大化利用 ceph 集群 PG 在不同磁盘上分布的优势。条带化示意如下:
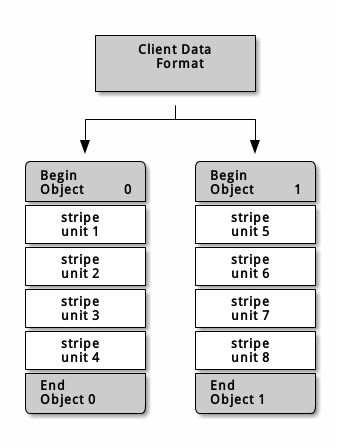
如果存储大文件,例如视频等,则需要考虑通过在一个 object set(对象集,多个对象) 中条带化多个 object 来提高读写的性能。客户端并行的将条带单元写入对象集时,将显著提高写入性能。由于这多个对象被映射到不同的 pg,pg 又被映射到不同的 osd 之上,因此写入速度会由于并行而利用多个 osd 之上磁盘的性能叠加而增加。
注意:条带化和数据副本之间没有必然联系,条带化是以对象进行的,副本是通过 CRUSH 算法跨 osd 分发的,因此条带会自动复制。
如下图中,客户端请求的数据在 Object Set 上划分条带,Object Set 1 包含了 4 个对象。第一个条带单元 stripe unit 0 存储在 Object 0 内,第四个条带单元 stripe unit 3 保存在 Object 3 内当写完四个 Object 后,客户端会确认 Object Set 是否写满,如果未写满,则继续返回给 Object 0 内写 stripe unit,直到 Object Set 写满之后,客户端会创建一个新的 Object Set 。
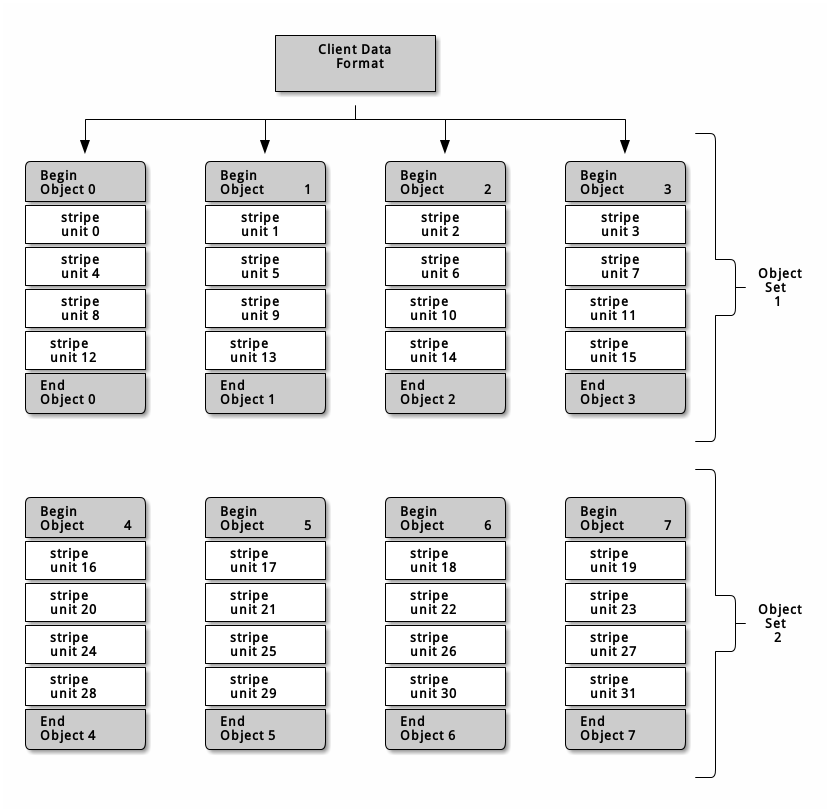
三个变量指标将决定 ceph 将如何条带化数据:
- Object Size:Object 可调整大小,通常情况下,设置足够大的尺寸以容纳更多的 Stripe unit。
- Stripe Width:Stripe unit 的大小,例如 64KB。
- Stripe Count:Stripe unit 的数量,取决于 Object size 和 Stripe Width。
3. Ceph 手动部署
3.1 获取软件
安装ceph有几种方法,最简易和推荐的方式是添加官方或者镜像存储库来获取安装包,例如使用 apt 或 yum 进行安装。获取软件包有两种方式:1、添加存储库,使用软件包管理工具进行安装。2、手动下载安装包。
ceph 存储库中安装包括 keys、Ceph Packages、Ceph Development 三种类型的文件。推荐下载密钥 key,无论是从存储库还是手动下载软件包都应该下载密钥 key 来验证软件包。Ceph Packages 是必须安装的类型。如果进行 ceph 的开发工作,则可以下载 Ceph Development 类型软件包。
添加密钥
# 密钥
rpm --import 'https://download.ceph.com/keys/release.asc'
# 阿里镜像密钥
rpm --import 'https://mirrors.aliyun.com/ceph/keys/release.asc'添加存储库
# 官方存储库
https://download.ceph.com/rpm-{release-name}
# 阿里镜像存储库
https://mirrors.aliyun.com/ceph/?spm=a2c6h.13651104.0.0.79fb7dd1s5OLZo
# 其他
http://mirrors.ustc.edu.cn/ceph/rpm-{release-name}在 /etc/yum.repo.d/ 目录下创建一个 ceph.repo 文件,复制以下内容,并将 {ceph-release} 替换为要安装的 ceph 版本,例如: luminous, mimic, nautilus,将 {distro} 替换为 linux 的版本,替换镜像链接路径,密钥路径。此外需要注意的是,某些 ceph 软件包的优先级高于标准软件包,{epel 源中包含了 ceph 的安装包,则可能添加的 ceph 源无法生效,从 epel 源中下载}。因此要对源的下载优先级进行设置。内容如下:
[ceph]
name=Ceph packages for $basearch
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/$basearch
enabled=1
gpgcheck=1
priority=2
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/noarch
enabled=1
gpgcheck=1
priority=2
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/SRPMS
enabled=0
gpgcheck=1
priority=2
gpgkey=https://download.ceph.com/keys/release.asc# 安装插件
yum -y install yum-priorities
# 修改配置文件,确保启用插件
vim /etc/yum/pluginconf.d/priorities.conf
[main]
enabled=1
# 修改repo文件,修改源的优先级
priority=23.2 安装前准备
时间同步
时间同步使用 chronyd 服务,使用阿里时间服务器进行同步。 /etc/chrony.conf 配置如下:
server ntp.aliyun.com iburst
stratumweight 0
driftfile /var/lib/chrony/drift
rtcsync
makestep 10 3
bindcmdaddress 127.0.0.1
bindcmdaddress ::1
keyfile /etc/chrony.keys
commandkey 1
generatecommandkey
logchange 0.5
logdir /var/log/chrony设置时区为
Asia/Shanghai
基于主机名通信
各主机之间可以基于主机名通信。
无密钥通信
使用脚本进行无密钥通信进行设置。
for I in `seq 1 3`;do ./ssh.sh 10.53.220.20$I root '*******';done添加epel存储库
# 安装存储库
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm安装 ceph 依赖包
yum install leveldb python-argparse snappy gdisk gperftools-libs
snappy # 压缩/解压缩库,提供非常高的速度和合理的压缩
leveldb # 键值数据库
gdisk # 用于GPT磁盘的类似fdisk的分区工具
python-argparse # 命令行解析
gperftools-libs # 性能分析工具 Perf Tools 的库文件安装ceph
yum install ceph3.3 部署注意事项
一个集群中必须有一个Monitor节点,监控节点为整个集群提供了一些重要的参数,例如:集群中副本数量、每个OSD的放置组数量、心跳信息时间间隔、是否启用认证功能。
必须有和集群副本数相同的OSD节点。
引导并初始化 Monitor 节点是部署 Ceph 集群的第一步。
如下图,是 一个简单的 Ceph 集群架构图,node1 作为管理节点。
3.4 部署 Monitor
3.4.1 注意事项
- 唯一标识符(Unique Identifier):
fsid是集群的唯一标识符。- 集群名称(Cluster Name):ceph集群需要一个名称,由一个简单的字符串组成,名称不能包含空格。默认的集群名称是
ceph,也可以自定义一个集群名称。在存在多个 ceph 集群的场景中,强烈建议自定义集群名称。当自定义集群名称后,需要注意:1、命令行表示集群名称需要使用--cluster {Cluster-Name}参数。2、使用集群名称命名集群配置文件。- Monitor 节点名称(Monitor Name):每个 Monitor 节点在集群中都有唯一的名称,通常将节点的主机名作为 Monitor 名称。建议将 Monitor 节点和 osd 节点分开部署。
- 监控节点映射(Monitor Map):安装监视节点需要生成监视节点映射。监视节点映射需要 fsid,集群名称(或使用默认值)以及至少一个主机名和其IP地址。
- 监控节点密钥(Monitor Key):监控节点之间通过密钥相互通信,必须生成一个带有监控节点密钥的密钥环,并在初始化监控节点时提供此密钥环。
- 管理员密钥(Administrotor Key):要使用 ceph CLI 工具,必须有一个 client.admin 用户。因此,必须生成管理用户和密钥环,并且还必须将 client.admin 用户添加到监视器密钥环中。
3.4.2 创建 Monitor 节点
ceph 集群的配置文件位置在 /etc/ceph/ 目录下,创建配置文件:
touch /etc/ceph/test-ceph.conf生成 ceph 集群唯一标识符 fsid:
uuidgen
14576471-c98a-48d6-b217-0e451cba7043创建 monitor 节点之间通信使用的密钥 key:
ceph-authtool --create-keyring /root/ceph-deploy/test-ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'创建管理员密钥,生成 client.admin 用户并添加用户到密钥:
ceph-authtool --create-keyring /etc/ceph/test-ceph.client.admin.keyring --gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *'生成bootstrap-osd密钥环,生成client.bootstrap-osd用户并将用户添加到密钥环:
ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/test-ceph.keyring --gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' --cap mgr 'allow r'将生成的密钥 client.admin 和 client.bootstrap-osd 添加到 monitor 通信密钥环文件中:
ceph-authtool /root/ceph-deploy/test-ceph.mon.keyring --import-keyring /etc/ceph/test-ceph.client.admin.keyringceph-authtool /root/ceph-deploy/test-ceph.mon.keyring --import-keyring /var/lib/ceph/bootstrap-osd/test-ceph.keyring生成监控节点映射:
# 生成映射
monmaptool --create --add node1.ceph.com 10.53.220.240 --add node2.ceph.com 10.53.220.241 --add node3.ceph.com 10.53.220.242 --fsid 5c8e1ff2-2183-48bf-a760-7220ec64fbad /root/ceph-deploy/monmap
# 查看monmap
monmaptool --print monmap创建monitor数据目录(此目录会自动生成):
mkdir /var/lib/ceph/mon/{cluster-name}-{hostname}数据目录初始化操作,初始化完成后会在目录下生成数据文件(验证数据目录是否生成文件):
ceph-mon --cluster test-ceph --mkfs -i node1.ceph.com --monmap /root/ceph-deploy/monmap --keyring /root/ceph-deploy/test-ceph.mon.keyring提供 test-ceph.conf 配置文件:
[global]
# ceph 集群唯一标识符
fsid = d2852e03-4354-4220-887c-61f1e9e13249
# 填写 monitor 节点名称
mon initial members = node1.ceph.com,node2.ceph.com,ceph3.ceph.com
# 监控节点 IP 地址
mon host = 10.53.220.240,10.53.220.241,10.53.220.242
public network = 10.53.220.0/24
cluster network = 10.53.220.0/24
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = 1024
osd pool default size = 3
osd pool default min size = 2
osd pool default pg num = 1024
osd pool default pgp num = 1024
osd crush chooseleaf type = 1启动 ceph-mon 进程:
# 启动前将 monitor 之间通信使用的密钥 key 复制到 /var/lib/ceph/mon/ 目录下
# 修改 mon 数据目录属组和属主
chown -R ceph:ceph /var/lib/ceph/mon/{ceph_name}-{monhost_name}
# 启动和设置开机自启
systenctl start ceph-mon@node1.ceph.com
systenctl enable ceph-mon@node1.ceph.com3.4.3 扩展 Monitor 节点
复制
test-ceph.conf配置文件到另外两个节点。在 node2 和 node3 节点创建 monitor 数据目录
/var/lib/ceph/mon/test-ceph.node2.ceph.com和/var/lib/ceph/mon/test-ceph.node3.ceph.com。复制
monmap和test-ceph.mon.keyring文件到另外两个节点。从正常的 monitor 节点导出 monmap
ceph mon getmap -o /path/to/dir/monmap初始化 node2 和 node3 节点。
ceph-mon --cluster test-ceph --mkfs -i node2.ceph.com --monmap /root/ceph-deploy/monmap --keyring /tmp/test-ceph.mon.keyring ceph-mon --cluster test-ceph --mkfs -i node3.ceph.com --monmap /root/ceph-deploy/monmap --keyring /tmp/test-ceph.mon.keyring # 初始化完成后要确认在相应的目录下生成的数据文件
3.4.4 启动 ceph-mon 进程
注意:实验中以 root 用户身份运行 ceph-mon 守护进程,所以需要修改
ceph-mon@.service文件中ExecStart=字段中传递给 ceph-mon 进程的用户名、用户组参数为 root。(可选,如果以root身份运行)
# 添加 service unit 环境变量,修改 /etc/sysconfig/ceph
CLUSTER=test-ceph
# 启动
systenctl start ceph-mon@node2.ceph.com
systenctl start ceph-mon@node3.ceph.com
# 设置开机自启动
systenctl enable ceph-mon@node2.ceph.com
systenctl enable ceph-mon@node3.ceph.com3.4.5 删除 mon 节点
# 停止mon进程
systemctl stop ceph-mon@{mon_id}
# 从集群中删除mon节点
ceph mon remove {mon_id}3.5 部署 MGR
- ceph-mgr 与 ceph-mon 进程一起运行,提供附加的监控以及外部监控和管理功能。从
luminous 12.x版本起,ceph-mgr 是 Ceph 集群正常运行的必要组件。- 对 ceph-mgr 的访问需要使用 cephX 认证,如果从旧版本 Ceph 升级或其他部署工具部署则会自动获得访问 ceph-mgr 的权限。若非如此,则可能在运行某些集群命令时则可能提示
EACCES错误,需要手动授权访问 ceph-mgr。- ceph-mgr 进程中首先启动的将先被 monitor 激活,其他后启动作为
standby进程,因此 ceph-mgr 进程并不需要仲裁。如果 ceph-mgr 进程在mon mgr beacon grace配置参数指定的时间间隔内未给 monitor 发送心跳信息,则将启用 standby 进程。可使用ceph mgr fail <mgr_name>手动转移故障。- ceph-mgr 可运行众多的附加模块运行,如果 module 被启用,则活跃的 ceph-mgr 进程将加载此模块。有些模块可能对外提供服务,例如 HTTP 服务。此外,一些模块还支持重定向功能,当用户向 standby 的 ceph-mgr 进程发起请求时,可被重定向到活跃的进程上去。
- 集群在第一次启动时,会使用 [mon] 配置段中
mgr initial modules = <module1_name> <module2_name>配置参数中指定的模块启动。此后,此配置参数将不生效。
# 查看模块
ceph mgr module
# 启用/禁用
ceph mgr module enable|disable <module_name>
# 查看 module 中发布的服务地址
ceph mgr services
# mgr 给 monitor 发送心跳的时间间隔,默认为 5 秒
mgr tick period =
# mgr 故障的超时时间,默认为 30 秒
mon mgr beacon grace = 注意:1、在三个节点都要进行以下操作;2、建议在每个运行
ceph-mon进程的节点上运行ceph-mgr进程。
为 ceph-mgr 守护进程创建通信密钥:
ceph auth get-or-create mgr.node1.ceph.com mon 'allow profile mgr' osd 'allow *' mds 'allow *'将密钥导入到 mgr 数据目录中:
# 创建 mgr 数据目录
mkdir /var/lib/ceph/mgr/test-ceph-node1.ceph.com
# 导入 keyring
ceph auth get mgr.node1.ceph.com -o /var/lib/ceph/mgr/test-ceph-node1.ceph.com/keyring修改 mgr service unit 文件及数据目录权限:
# 一
ExecStart=/usr/bin/ceph-mgr -f --cluster ${CLUSTER} --id %i --setuser root --setgroup root
# 二
chown -R ceph:ceph test-ceph-node1.ceph.com/启动 ceph-mgr 进程:
systemctl start ceph-mgr@{mgr-id}
ceph-mgr --conf /etc/ceph/test-ceph.conf -i node1.ceph.com --cluster test-ceph设置开机自启动:
systemctl enable ceph-mgr@node1.ceph.com3.6 部署 OSD
添加 OSD 有两种方式,快速创建并激活,手动创建激活。Ceph 提供了 ceph-volume 程序来准备逻辑卷、磁盘或分区供 OSD 使用,ceph-volume 创建 OSD ID,此外,还添加 OSD 到 CRUSH 的映射。
3.6.1 注意事项
- ceph-volume 可以激活逻辑卷、裸设备、分区。
create选项会创建和激活 OSD,prepare选项是准备 OSD,activate是激活 OSD。- 需要将
/var/lib/ceph/bootstrap-osd/test-ceph.keyring文件复制到各个节点。
3.6.2 自动创建并激活 OSD
注:如果集群名称不是默认名称,则在 .bashrc 文件添加
alias ceph='ceph --cluster test-ceph'命令别名。
# 方法一 直接启动并激活
ceph-volume --cluster test-ceph lvm create --bluestore --data <VG_NAME>/<LV_NAME> --block.db <VG_NAME>/<LV_NAME># 方法二 创建,而后激活
ceph-volume --cluster test-ceph lvm prepare --bluestore --data <VG_NAME>/<LV_NAME> --block.db <VG_NAME>/<LV_NAME>
ceph-volume --cluster <CLUSTER_NAME> lvm activate {ID} {OSD_FDID}3.6.3 手动创建 OSD
创建 osd
# 生成一个密钥
ceph-authtool --gen-print-key
# 生成osd uuid
uuidgen
# 生成 osd id,并添加
echo "AQCli/hdJfADHBAABG39q3dbJugf6evhKq6V1g==" | ceph --cluster <CLUSTER_NAME> --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/<CLUSTER_NAME>.keyring -i - osd new <OSD_UUID>
# 挂载 tpmfs 到 osd 数据目录
mount -t tmpfs tmpfs /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>
# 修改osd数据设备的权限
chown -h ceph:ceph /dev/<VG_NAME>/<LV_NAME>
chown -R ceph:ceph /dev/dm-{N}
# 创建 osd 数据设备软链接
ln -s /dev/cephd/osd7 /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/block
# 生成 monmap 到 osd 数据目录
ceph --cluster test-ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/<CLUSTER_NAME>.keyring mon getmap -o /var/lib/ceph/osd/test-ceph-7/activate.monmap
# 生成 osd key
ceph-authtool --gen-print-key
# 生成osd密钥环文件
ceph-authtool /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/keyring --create-keyring --name osd.7 --add-key AQBVlPhdxXG1CRAALS+M/sWCphT4TtUrd25R8Q==
# 修改密钥环文件权限、osd 数据目录权限、block.db 数据设备权限
chown -R ceph:ceph /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/keyring
chown -R ceph:ceph /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/
chown -h ceph:ceph /dev/<VG_NAME>/<LV_NAME>
chown -R ceph:ceph /dev/dm-{N}
# 初始化 osd 数据目录
echo "AQBVlPhdxXG1CRAALS+M/sWCphT4TtUrd25R8Q==" |ceph-osd --cluster <CLUSTER_NAME> --osd-objectstore bluestore --mkfs -i <OSD_ID> --monmap /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/activate.monmap --keyfile - --bluestore-block-db-path /dev/<VG_NAME>/<LV_NAME> --osd-data /var/lib/ceph/osd/<CLUSTER_NAME>-<OSD_ID>/ --osd-uuid 42aff8a7-5e44-4bef-9074-8ffe8befbcd8 --setuser ceph --setgroup ceph --no-mon-config激活 osd
# 修改 osd 数据目录权限
chown -R ceph:ceph /var/lib/ceph/osd/test-ceph-7
# 设置 bluestore 数据目录
ceph-bluestore-tool --cluster=test-ceph prime-osd-dir --dev /dev/cephd/osd7 --path /var/lib/ceph/osd/test-ceph-7 --no-mon-config
# 生成 osd 认证文件
ceph-authtool -C /root/keyring -n osd.7 --cap mgr "allow profile osd" --cap mon "allow profile osd" --cap osd "allow *" --add-key "AQBVlPhdxXG1CRAALS+M/sWCphT4TtUrd25R8Q=="
# 导入文件
ceph auth import -i /root/keyring
# 设置开机 ceph-volume 自动激活osd
systemctl enable ceph-volume@lvm-7-42aff8a7-5e44-4bef-9074-8ffe8befbcd8
systemctl enable ceph-osd@7
# 启动 osd
systemctl start ceph-osd@7给lvm添加tag信息
# 查看 lvm tag 信息
lvs --noheadings --readonly -o lv_tags
# 添加 lvm tag 信息
lvchange --addtag tags vg/lv
# 删除 tag 信息
lvchange --deltag tags vg/lv
# 需要添加的 tag 信息如下
ceph.block_device=/dev/cephe/osd8
ceph.block_uuid=A5lheC-dCo5-OxSr-i3AS-vY1O-btbe-Qo8MVK
ceph.cephx_lockbox_secret=
ceph.cluster_fsid=7f02bf48-836f-4b48-a342-70bdb33b8716
ceph.cluster_name=test-ceph
ceph.crush_device_class=None
ceph.db_device=/dev/cephg/block8
ceph.db_uuid=CfOb7X-OwVa-WeHK-P9dk-n742-8T7Z-SfGJYU
ceph.encrypted=0
ceph.osd_fsid=f361b747-498a-405d-8977-ee957c01c969
ceph.osd_id=8
ceph.type=block 或 db
ceph.vdo=03.7 添加 MDS
创建 mds 数据目录:
# id 可以是任意名称,例如主机名
mkdir -p /var/lib/ceph/mds/{cluster-name}-{id}
mkdir -p /var/lib/ceph/mds/test-ceph-node1.ceph.com创建密钥文件:
ceph-authtool --create-keyring /var/lib/ceph/mds/test-ceph-node1.ceph.com/keyring --gen-key -n mds.node1.ceph.com导入密钥文件并授权:
# 创建并导入密钥(执行此步骤可省略创建密钥步骤)
ceph auth get-or-create mds.${id} mon 'profile mds' mgr 'profile mds' mds 'allow *' osd 'allow *' > /var/lib/ceph/mds/ceph-${id}/keyring
# 此外将密钥导入到keyring文件中添加配置文件:
[mds.node1.ceph.com]
host = node1.ceph.com启动服务:
systemctl enable ceph-mds@node1.ceph.com
systemctl start ceph-mds@node1.ceph.com4. Ceph Dashboard
4.1 概述
Ceph Dashboard 是基于 Web 界面的内置的管理和监控 ceph 集群的应用程序,是 ceph-mgr 守护进程的模块实现。对于 Luminous 之前的版本 Dashboard,功能比较简单,只有一个简单的只读视图,可查看集群状态信息和性能数据。新版本中的 Dashboard 架构和功能源自于 OpenATTIC,ceph Dashboard 后端使用 CHerryPy 框架和自定义的 REST API 实现,Web UI 基于 Angular/TypeScript, 在新版本的 Dashboard 中合并的旧版本的功能并开发了新的功能。
4.2 功能特性
多用户和角色管理。支持多用户定义不同的权限,通过 Web UI 可以修改和管理用户以及所属的权限;单点登录,支持通过 SAML 2.0 协议进行身份认证;SSL 加密传输;审计。对 Dashboard 后端的所有请求,都可以进行记录,开启此功能需要进行配置。;化语言支持。
支持监控和管理 Ceph 集群:
- 展示集群状态,性能和容量指标。
- 可以嵌入 Grafana 图表,显示通过 Prometheus 模块收集到的性能等信息。
- 显示集群最近的日志和审计信息。日志条目可按优先级日期或关键字进行过滤。
- 显示与集群内的所有主机及其上运行的进程和版本信息。
- 性能统计,显示每个运行的服务的统计信息。
- 显示所有 Monitor,仲裁结果,选举结果。
- 配置操作。显示所有可用的配置项,以及配置项的描述、类型、默认值。
- 列出所有Ceph池及其详细信息(例如应用程序,放置组,副本个数,EC配置文件,CRUSH规则集等)。
- 列出所有 OSD 以及 OSD 的状态和使用统计信息。例如:读写操作、OSD 映射、元数据、性能指数、使用情况等。
- iSCSI 支持。
- 列出所有 RBD image 及其属性(大小、对象、特征等);创建、克隆、修改、删除 RBD image,配置 I/O 限制;创建、保护快照。
- 启用并配置 RBD 镜像到远程 Ceph 服务器。列出所有活动的同步守护程序及其状态,池和 RBD 映像,包括其同步状态。
- 列出所有活动对象网关及其性能计数器。显示和管理(添加/编辑/删除)对象网关用户及其详细信息(例如配额)以及用户的存储桶及其详细信息(例如所有者,配额)。
- 启用和禁用所有Ceph Manager模块,更改模块特定的配置设置。
4.3 启用 Dashboard
安装 Dashboard 软件包:
yum install ceph-mgr-dashboard启动 dashboard:
ceph mgr module enable dashboard默认情况下,与仪表板的所有HTTP连接均使用SSL / TLS保护,为了使 dashboard 快速启动并运行,您可以使用以下内置命令生成并安装自签名证书:
# 禁用 SSL
ceph config set mgr mgr/dashboard/ssl false
# 生成自签名 SSL 证书
ceph dashboard create-self-signed-cert
#
# 创建用户名及密码
ceph dashboard ac-user-create <user_name> <user_password> administrator每个 ceph-mgr 实例都可以拥有自己的 dashboard 实例,因此为了 dashboard 的可用性,尽可能在每一个 ceph-mgr 实例上安装 ceph-mgr-dashboard 安装包,并全部配置相应的端口和需要绑定的 IP 地址。当某一个 ceph-mgr 实例故障时,其之上所托管的 dashboard 也将不可用。事实上,ceph-mgr 会将故障的 dashboard 地址重定向到正常的 dashboard 页面。luminous 版本中,dashboard 的故障转移生效需要重新启动 ceph-mgr 进程,否则其他节点无法加载 dashboard 模块。
# 配置监听端口和 IP
ceph config set mgr mgr/dashboard/<mgr1_name>/server_addr 10.53.120.11
ceph config set mgr mgr/dashboard/<mgr1_name>/server_port 1024
ceph config set mgr mgr/dashboard/<mgr2_name>/server_addr 10.53.120.12
ceph config set mgr mgr/dashboard/<mgr2_name>/server_port 1024
# 查看配置(此写配置是写入到 monitor 集中式配置数据库中)
ceph config dump
# 查看 ceph-mgr 暴露出来的服务
ceph mgr services
# 启用禁止 dashboard 模块
ceph mgr module enable|disable dashboard打开浏览器查看 dashboard:
# 当禁用 ssl 时,当前活跃的 mgr 示例默认会将 dashboard 绑定到 8080 或 8443 端口
http://10.53.220.240:8080/ http://10.53.220.240:8443/4.4 启用 Object Gateway 管理
在 dashboard 中开启 object gateway 管理功能,你需要提供 rgw 系统用户的连接凭证。
# 创建 rgw 系统用户
radosgw-admin user create --uid=dashboard --display-name=dashboard --system
# 给 dashboard 提供密钥
ceph dashboard set-rgw-api-access-key "O2EH7TLA5AD4JT43BFQY"
ceph dashboard set-rgw-api-secret-key "OjysFxGrEizj5XcDZ3Xx8dU9wWhqHcvCvUlfDkZw"通常指定 rgw 系统用户之后,mon 会自动去查找 mon 信息来查找 rgw 信息,但有时候可能需要去手动指定 rgw 主机和端口。
ceph dashboard set-rgw-api-host <host>
ceph dashboard set-rgw-api-port <port>如果 rgw 启动了 SSL 并使用了自签名的证书,则需要手动关闭 dashboard 对证书的效验。
ceph dashboard set-rgw-api-ssl-verify False如果 dashboard 请求 rgw 超时,则可以设置对 rgw 的请求超时时间,默认为 45 秒。
ceph dashboard set-rest-requests-timeout <seconds>其他配置。
ceph dashboard set-rgw-api-scheme <scheme> # http or https
ceph dashboard set-rgw-api-admin-resource <admin_resource>
ceph dashboard set-rgw-api-user-id <user_id>4.5 嵌入 grafana 监控图表
效果如图:
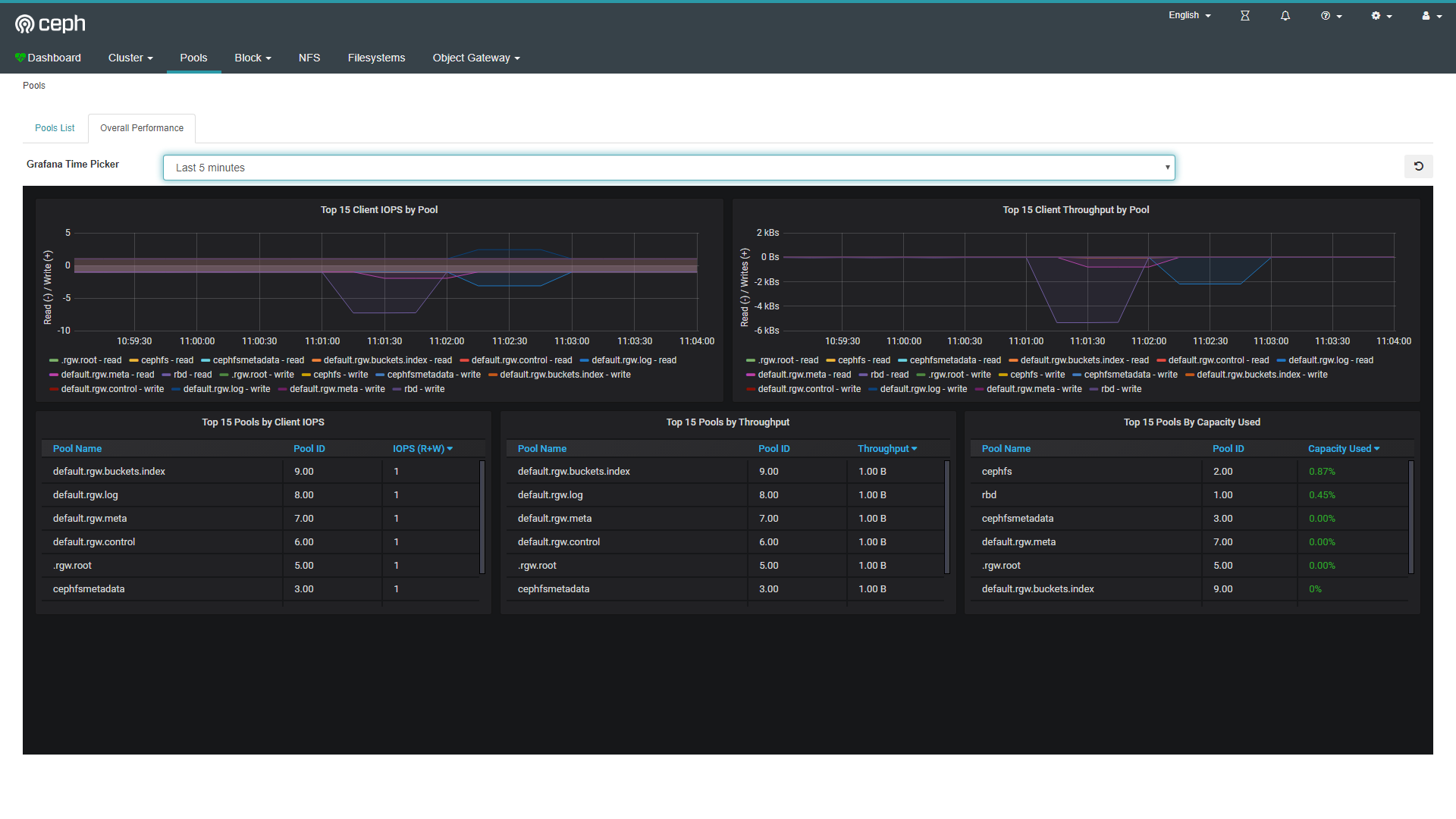 grafana 允许去查询、展示、告警关注的某些指标,数据来源支持多种类型。是一款流行的可视化工具,可以进行多种类型的图表展示。prometheus主要用于抓取数据和存储时序数据,prometheus server 定期从静态配置的 targets 中拉取数据并持久化存储到磁盘中。在 Ceph 中的 Dashboard 中,可嵌入由 grafana 生成的监控图表,grafana 的监控数据来源于 prometheus 提取的数据。
grafana 允许去查询、展示、告警关注的某些指标,数据来源支持多种类型。是一款流行的可视化工具,可以进行多种类型的图表展示。prometheus主要用于抓取数据和存储时序数据,prometheus server 定期从静态配置的 targets 中拉取数据并持久化存储到磁盘中。在 Ceph 中的 Dashboard 中,可嵌入由 grafana 生成的监控图表,grafana 的监控数据来源于 prometheus 提取的数据。
在现有的 ceph 版本中,grafana 和 prometheus 还没有和 ceph 进行捆绑,需要分别手动安装 prometheus 和 grafana。
4.5.1 安装 prometheus
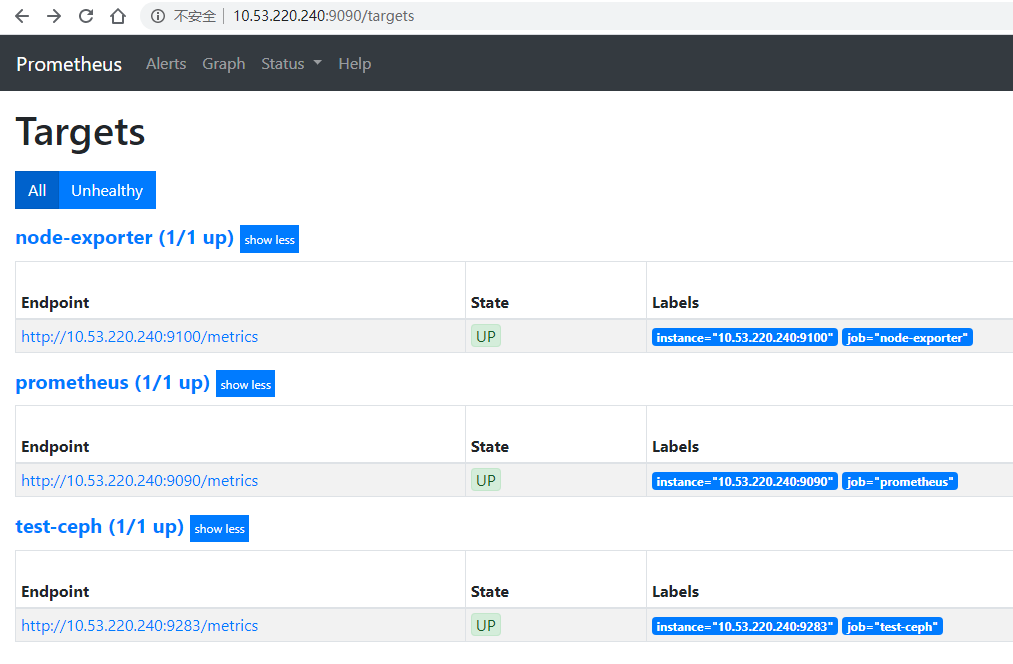
Prometheus 通过 HTTP 协议周期性的抓取被监控组件的状态,被监控的组件提供 HTTP 访问接口,输出被监控组件信息的 HTTP 接口被称为 exporter,Ceph mgr 内嵌了 prometheus exporter 模块,需要手动启用。安装 prometheus 之后可以在其页面上查看到 target 信息 http://10.53.220.240:9090/。
启用 ceph prometheus 模块:
ceph mgr module enable prometheus
# 配置端口
ceph config-key set mgr/prometheus/server_addr x.x.x.x
# 启用之后,会监听 9283 端口,可使用 http://10.53.220.240:9283/ 链接查看安装 prometheus:
# 下载
wget https://github.com/prometheus/prometheus/releases/download/v2.15.1/prometheus-2.15.1.linux-amd64.tar.gz
# 解压,将解压后的文件复制到此目录下
tar -xf prometheus-2.15.1.linux-amd64.tar.gz
mkdir /usr/local/prometheus
mv prometheus-2.15.1.linux-amd64/* /usr/local/prometheus提供配置文件:
# 编辑安装目录下 prometheus.yml 文件
# 导出prometheus本身的状态信息
- job_name: 'prometheus'
static_configs:
- targets: ['10.53.220.240:9090']
# 指定 ceph mgr prometheus 模块导出
- job_name: 'test-ceph'
honor_labels: true
static_configs:
- targets: ['10.53.220.240:9283']
# 本地主机的状态信息
- job_name: 'node-exporter'
static_configs:
- targets: ['10.53.220.240:9100']提供服务脚本:
vim /etc/systemd/system/prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheus
Restart=on-failure
[Install]
WantedBy=multi-user.target启动 prometheus:
systemctl enable prometheus.service
systemctl start prometheus.service4.5.2 安装 node-exporter
下载安装:
# 下载
wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
# 将所有文件解压并复制到 /usr/local/node-export 目录下
tar -xf node_exporter-0.18.1.linux-amd64.tar.gz
cp -a node_exporter-0.18.1.linux-amd64/* /usr/local/node-export提供服务脚本:
vim /etc/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target启动:
systemctl enable node_exporter.service
systemctl start node_exporter.service4.5.3 安装 grafana
添加 yum 仓库:
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt安装:
yum install grafana启动:
systemctl enable grafana-server.service
systemctl start grafana-server.service安装插件:
grafana-cli plugins install vonage-status-panel
grafana-cli plugins install grafana-piechart-panel安装完成之后可通过 8080 端口访问 grafana,用户名和密码默认为 admin/admin。
4.5.4 启用 grafana
将 prometheus 添加到 grafana 的数据源:
在 grafana 中添加监控面板,使用 json 模板文件直接导入,json模板文件默认在 /etc/grafana/dashboards/ceph-dashboard目录下。也可以在 github ceph 仓库中下载 json 模板文件。
配置 grafana 允许匿名访问模式:
vim /grafana/grafana.ini
[auth.anonymous]
enabled = true
org_name = Main Org.
org_role = Viewer默认情况下,grafana 不允许在通过 iframe 的方式在浏览器中嵌入渲染图表,需要手动配置将其设置为允许,编辑 grafana 配置文件:
allow_embedding = true在 ceph dashboard 中配置 grafana 的 api 地址,使其能够访问 grafana:
ceph dashboard set-grafana-api-url http://10.53.220.240:3000注意:如果 ceph dashboard 中配置了 SSL 支持,则 ceph dashboard 会拒绝加载 grafana 中的图表。
启动 rbd 状态监控:
# pool_name 为 rbd 存储池
ceph config set mgr mgr/prometheus/rbd_stats_pools {pool_name}
# 设置对 rbd 监控状态的刷新时间
ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 300 为了使 dashboard 能够监控到其他主机信息,在 prometheus 中需要设置主机名:
- job_name: 'node-exporter' static_configs: - targets: ['node1.ceph.com:9100']
4.6 启用 iSCSI 管理
cpeh dashboard 能够通过 rbd-target-api 服务管理 iSCSI target。ceph dashboard 管理 iSCSI target 需要 ceph-iscsi v3 版本,如果 ceph-iscsi REST API 是在 HTTPS 模式下配置的,并且使用自签名证书,那么您需要配置信息中心,以避免在访问ceph-iscsi API时进行SSL证书验证。
禁用 API SSL 验证:
ceph dashboard set-iscsi-api-ssl-verification false添加 iSCSI网关:
ceph dashboard iscsi-gateway-add http://admin:admin@10.53.220.240:5000
ceph dashboard iscsi-gateway-add http://admin:admin@10.53.220.241:5000
ceph dashboard iscsi-gateway-list5. Ceph 块存储
5.1 简介
块设备:1、线性的存储空间;2、支持随机读写;3、字符设备按照字符流方式被有序访问;
Ceph RBD 提供虚拟块设备可被使用,RBD 配置精简、可调整大小、在 ceph 集群中的多个 osd 上条带化存储数据。RBD 块设备通过内核模块或者librbd库与osd进行交互。通过内核模块的rbd可使用Linux页面缓存,通过librbd库的rbd支持rbd缓存。ceph 块设备可通过内核模块、KVM、依靠libvirt和QEMU与ceph块设备集成的云场景。
关于 Linx 页缓存
5.2 rbd 基本操作
创建rbd
创建 rbd 之前需要初始化一个 pool 用来使用 rbd 块设备,如果未提供 pool name 则 rbd 命令默认将 pool name 为 rbd 的池初始化为用作 rbd 的 pool。
rbd pool init --conf /etc/ceph/test-ceph.conf --cluster test-ceph --pool rbdPool创建访问有限权限的用户
# 创建对池 rbdpool 具有读写访问权限
ceph auth get-or-create client.testrbd mon "allow r" osd "allow rwx pool=rbdPool"在ceph集群中创建rbd
rbd --cluster test-ceph create --size 102400 --image-feature layering --image-feature striping poolName/rbdName其他操作
# 查看 rbd
rbd ls <PoolName>
# 查看 rbd 详细信息
rbd info <poolName>/<rbdName>
# 扩大或减小 rbd。调整 rbd image 的大小类似于截断一个稀疏文件。增加的空间部分归置为0,缩小rbd iamge 会删除超出旧范围的内容。
rbd resize --size 2048 poolName/rbdName (增加)
rbd resize --size 2048 poolName/rbdName --allow-shrink (减少)
# 删除 rbd
rbd rm poolName/rbdName
# 将 rbd 移动到回收站
rbd trash mv poolName/rbdName
# 查看回收站 rbd
rbd trash ls poolName
# 删除回收站 rbd
rbd trash rm poolName/rbd-id (rbdPool/2fd2181d0d0e)
# 恢复回收站中的 rbd
rbd trash restore poolName/image-id
# 恢复回收站中的 rbd 时重命名
rbd trash restore poolName/image-id --image new-name
# 查看 rbd 被哪个客户端使用
rados -p rbdpool listwatchers rbd_header.{100986b8b4567}
# 查看 rbd 使用量
rbd du -p|--pool {pool-name}
# 查看 rbd 状态
rbd status {pool-name}/{rbd-name}
# 监控 rbd 状态
rbd watch {pool-name}/{rbd-name}注意:1、可以将任何rbd移动至回收站,如果rbd有克隆或有快照,此时回收站的rbd不能删除。2、可使用–expires-at 延迟删除。
5.3 Ceph 快照
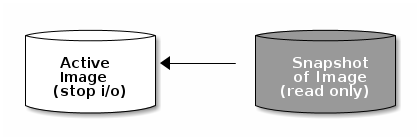
5.3.1 介绍
Ceph 快照 (Sapshots) 是 image 在某一时刻的一个只读副本,快照可以保留 image 某一刻的状态。ceph 支持使用 rbd 命令以及使用更高级别的接口(例如:QEMU、Libvirt、OpenStack、CloudStack)去创建快照。image 之上如果创建有文件系统,则这些文件系统对于 rbd 命令及众多的接口来说是透明的,因此在创建快照时 image 之上有 I/O 操作,有可能会造成文件系统错乱,所以建议在创建快照时停止设备的 I/O 操作。
对于单独挂载的块设备,可以使用以下命令:
# 锁定文件系统的 I/O 操作
fsfreeze -f|--freeze /MountPint
# 释放文件系统的 I/O 操作
fsfreeze -u|--unfreeze /MountPint5.3.2 rbd 命令使用
对于启用 cephX 认证的 Ceph 集群来说,使用 rbd 命令需要指定用户及秘钥路径。格式如下:
rbd --id {user-ID}|--name {username --keyring=/path/to/secret [commands]5.3.3 快照操作
# 创建快照。需要指定 pool 名称以及 image 名称、快照名称
rbd snap create {Pool-Name}/{Image-Name}@{Snap-Name}
# 查看快照。需要指定查看的是哪个 pool 中的哪个 image 的快照
rbd snap ls {Pool-Name}/{Image-Name}
# 回滚快照。需要指定回滚到哪个 Pool 中的哪个 Image 的哪个快照
rbd snap rollback {Pool-Name}/{Image-Name}@{Snap-Name}注意:回滚快照意味着将使用快照时的那个状态覆盖当前 image 的状态;回滚所需要的时间随 image 的增大而增加;创建快照比回滚快照要快。
# 删除快照。
rbd snap rm {Pool-Name}/{Image-Name}@{Snap-Name}
# 删除 image 的所有快照
rbd snap purge {pool-name}/{image-name}注意:ceph OSD 在删除数据是异步的,并不会立即释放磁盘空间。
5.4.4 写时复制
写时复制原理如下:
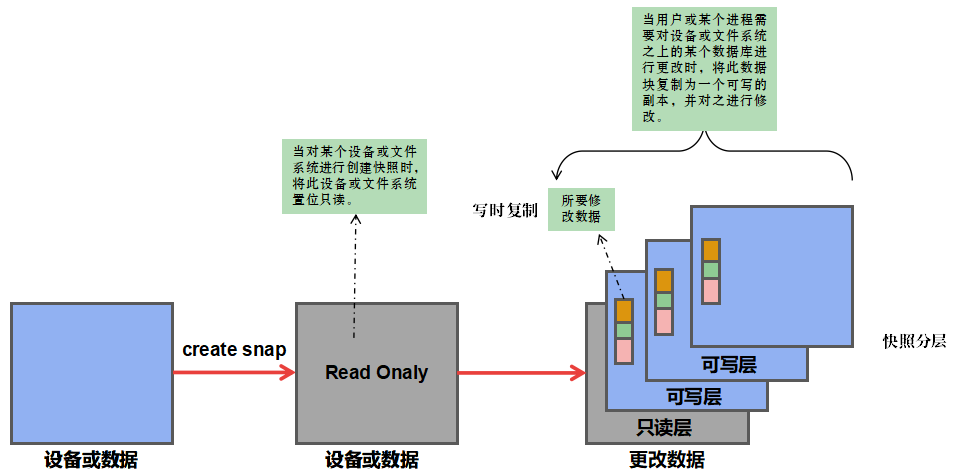
当数据更改时不会在原 image 之上更改,而是创建一个可写层进行更改数据。
5.4.5 克隆快照
注意:克隆快照只支持 image 格式为
--image-format 2格式。从 Linux 内核 3.10 之后支持克隆快照。
在创建 clone snap 时,必须对原 snap 进行保护。创建 clone snap 流程如下:
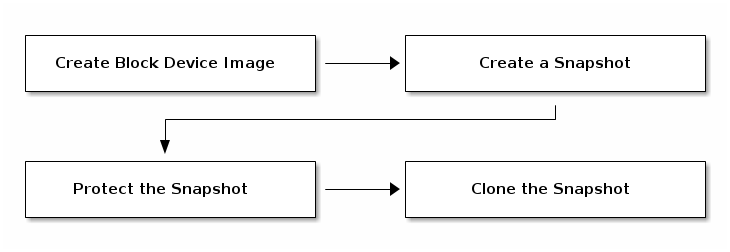
克隆快照对其父快照进行了引用,包括 pool ID、image ID、snap ID。可以将克隆快照从一个池中复制到另一个池中。克隆快照和 image 的快照类似,也可以对克隆快照进行修改、写入等操作。克隆快照在写时复制时引用了其父快照,因此在克隆快照之前需要对快照进行保护。用户无法对受保护的快照进行删除操作。
clone snap 操作
# 保护 snap
rbd snap protect {Pool-nName}/{Image-Name}@{Snapshot-Name}# 克隆 snap
rbd clone {pool-name}/{parent-image}@{snap-name} {pool-name}/{child-image-name}在删除快照之前,必须先取消保护。此外,不能删除被克隆快照引用的快照。在删除快照之前必须删除克隆快照。
# 删除某个快照的保护
rbd snap unprotect {pool-name}/{image-name}@{snapshot-name}# 列出某个快照的克隆快照
rbd children {pool-name}/{image-name}@{snapshot-name}克隆快照保留了对父快照的引用,当你想从子快照中删除对父快照的引用时,可以通过将数据从快照中复制到克隆快照中来。展开克隆快照的时间与快照大小有关,删除快照,必须先展开快照克隆。
rbd flatten {pool-name}/{image-name}5.4 rbd 排它锁
排它锁介绍
维基百科
排他锁(Exclusive Locks,简称X锁),又称为写锁、独占锁,在数据库管理上,是锁的基本类型之一。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
排它锁是一种为了避免多个进程不协调的访问同一个 rbd 块设备而造成数据损坏的一种机制,排它锁在虚拟化场景中大量使用以及 RBD Mirror 中使用。默认情况下 rbd 会启用排它锁,可使用 rbd_default_features 选项或在创建 rbd 时使用 --image-feature exclusive-lock 选项覆盖。为了确保正确的操作排它锁,使用 rbd 的任何客户端使用排它锁特性需要启用 cephx 身份认证且包含 profile rbd 权限。
librbd客户端程序或内核rbd客户端开始使用启用了独占锁的 rbd 时,会在首次写入数据时首先持有独占锁。任何程序在优雅终止后,都会自动释放,使随后的进程能够获得排它锁并向rbd内写入数据。需要注意的是,两个或两个以上的进程完全可能会同时去读取rbd内的数据,只有当某个进程写入数据时才会获得排它锁。
黑名单
有些情况下,一个客户端(如何krbd client,是客户端节点的内核线程)在rbd上获得排它锁,但此客户端没有优雅终止,例如节点突然断电等故障,在这种情况下,客户端持有的排它锁不会被自动释放。因此,当有新的客户端尝试使用rbd设备时,需要一种方式去打破先前客户端持有的排它锁。
然后,某些进程或内核线程会因为短暂的网络连接而挂起,在这种情况下,简单的打破锁可能会有潜在的危险,挂起的进程连接性问题可能立刻解决,但旧进程恢复和启动的新进程可能会产生会竞争,造成对rbd数据的破坏。如果进程无法以优雅的方式获得锁,之前的进程不仅会破坏锁,而且会被列入持锁者黑名单,列入黑名单的决定是由新的连接客户端和ceph mon协商的结果,mon收到黑名单请求后:
- Mon指示相关OSD不再服务于旧客户端进程的请求;
- 相关osd映射升级完成,mon将锁授予新客户端;
- 新客户端获得锁之后就会开始在rbd上写入数据。
为了使得黑名单生效,客户端必须要有osd黑名单使用权限,该权限通常在客户端和mon之间身份及权限认证的keyring配置文件之上配置。
5.5 rbd Mirroring
5.6 rbd 迁移
介绍
不同格式的 rbd 能够在同一个集群中的不同 pool 中进行迁移。当开始迁移时,源 rbd 将深度复制数据到目标 rbd,并将所有的历史快照及可能迁移的所有特征复制到目标 rbd ,以保证两个 rbd 之间的低耦合。复制进程能够安全的运行在后台,rbd 在迁移(复制)之前会暂时停止源 rbd 的使用即只读状态,以保证客户端使用复制之后的 rbd 之上的数据是最新的,rbd 的迁移是实时的。
rbd 迁移功能需要
Nautilus或最新版本。截止目前,内核使用的 rbd 还不支持此功能。
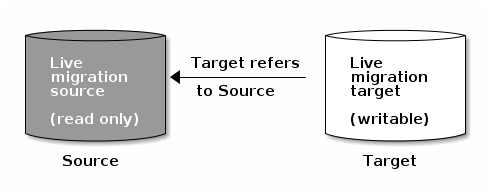
迁移过程:
- 准备过程:在初始化创建新 rbd 时,会创建目标 rbd 的交叉链接,类似于克隆快照,客户端读取目标 rbd 中未初始化的范围时将在内部把读写重定向到源 rbd,客户端如果写目标 rbd 中初始化的范围时将在内部深度复制源 rbd 的内容到目标 rbd,之后接受写请求。
- 迁移过程:后台复制线程从源 rbd 深度复制到目标 rbd。
- 结束过程:当后台复制迁移程序结束迁移,则可以发出迁移结束请求,当提交迁移结束之后,就会删除源 rbd 和目标 rbd 之间的交叉链接,之后删除源 rbd。如果中途终止迁移,则删除两者之间的交叉链接并删除目标 rbd。
迁移具体操作:
注意:1、在准备迁移过程中,如果发现 rbd 处于活跃状态,则准备过程可能失败,一旦迁移准备就绪,则客户端可以使用新的目标 rbd 进行。2、迁移rbd之后需要更改客户端的认证文件。
# 迁移准备过程
rbd migration prepare S_Pool/S_RBD D_Pool/D_RBD
# 查看迁移状态(源rbd将会被移动至回收站)
rbd status D_Pool/D_RBD
# 执行迁移(迁移过程中也可以查看迁移反馈信息)
rbd migration execute D_Pool/D_RBD
# 提交迁移
rbd migration commit D_Pool/D_RBD
# 终止迁移过程
rbd migration abort D_Pool/D_RBD5.7 持久缓存
通过克隆的 rbd 利用写时复制仅仅改变很少的数据,例如 VDI 的使用场景中,克隆虚拟机从相同的基础镜像中克隆而来。当虚拟机启动时,它们将重复的从ceph集群的父 rbd 中读取数据。如果我们在本地有一个父 rbd 的缓存,将有助于提高虚拟机的性能。父 rbd 的共享只读缓存需要在 ceph.conf 配置文件中开启。ceph-immmutable-object-cache 守护进程负责将父内容缓存在本地磁盘上,对该数据进行的读取将从本地缓存中进行。
注意:此功能从
Nautilus版本及之后可用。
ceph-immutable-object-cache守护进程会将父 rbd 的数据内容缓存在本地目录,因此使用 SSD 能够大大增提高性能,ceph-immutable-object-cache守护进程的关键组件有:
- 守护进程在启动时会在本地创建并监听一个本地套接字,等待librbd client的连接。
- 最近最少使用算法的升级/降级缓存策略。该守护进程将记录和分析每一个文件的命中信息。如果缓存容量达到配置的阈值,将会清除冷缓存。
- 守护进程将维持一个简单的基于文件的缓存存储。升级缓存的过程时,守护进程会将热点数据从RADOS请求并保存到本地缓存目录。
每当有数据要从 rbd 读取时,librbd 会尝试连接缓存进程的本地套接字,如果连接成功,则会检查是否会有缓存,如果缓存没有命中,守护进程将会从 RADOS 中读取数据缓存到本地,下一次读取该数据对象时,会从本地缓存中读取。守护进程使用 LRU 算法分析和统计缓存对象, 如果本地缓存没有乳沟的容量,守护进程会删除一些冷数据。
启用RBD共享只读缓存
# ceph.conf 配置文件
rbd parent cache enabled = true
immutable_object_cache_path = /path/to/dir
immutable_object_cache_max_size =
immutable_object_cache_watermark =
# 启用使用缓存的用户
ceph auth get-or-create client.ceph-immutable-object-cache.{unique id} mon 'allow r' osd 'profile rbd-read-only'
# 启动缓存进程
systemctl enable ceph-immutable-object-cache@immutable-object-cache.{unique id}
# 使用名命令行启动
ceph-immutable-object-cache -f --log-file={log_path}5.8 librbd 配置
5.8.1 缓存配置
内核驱动的 rbd 设备可使用 linux 页缓存来提高性能。用户空间操作使用的 rbd 设备(例如 librbd)无法利用 linux 的页面缓存,但是它可以使用自己内存中的缓存,称为 RBD caching rbd 缓存。RBD caching 和硬盘缓存一样,当操作方发送刷新缓存请求后,所脏数据将写入 osd,这意味着回写式缓存和使用物理磁盘样安全和可靠 (Linux kernel >= 2.6.32)。缓存使用 LRU 最近最少使用算法,在回写模式下,它可以合并连续的请求以获得更好的吞吐量。librbd 缓存默认是开启状态且支持三种不同的缓存策略:
- 绕写 (write-around),数据直接写入后端,但读取数据时才将数据缓存。
- 回写 (write-back),数据直接写到缓存中,一旦缓存中写成功,则返回写完成信息,把数据写到非易失性存储介质上的实际操作将会延迟进行。
- 直写 (write-through),写入数据时同时给后端和缓存写入数据。
librbd 缓存策略中,绕写和回写两种缓存策略都是立即返回写完成信息,除非 librbd 缓存容量超过设定值。绕写策略不同于回写策略,绕写策略不尝试接收读请求,而回写策略下,缓存层直接接收读请求,因此性能更好。直写策略下,只有当所有数据落在磁盘上后,才返回写完成信息,读请求可能来自于缓存层。
注意:
- 缓存在客户端的内存中保存,且每一个 RBD 都有自己的缓存。因此当每一个客户端连接 RBD 时,都会生成本地缓存,因此缓存的数据不具有一致性。所以,在分布式文件系统 GFS 无法启动 RBD 缓存。
- RBD 缓存配置应配置在 ceph.conf 文件中的 [client] 配置段中。
# 启用 RBD 缓存,默认为 true
rbd cache =
# 设置 rbd 缓存策略,可选值有 writearound(默认), writeback, writethrough
rbd cache policy =
# 以直写write-through模式开始,在第一次刷新请求后切换为回写write-back模式,默认为true
# 此功能是一种保守安全的设置,放置 rbd 客户端没有刷新请求功能而无法发送刷新
rbd cache writethrough until flush =
# 缓存大小,使用范围(write-back,write-through),字节为单位,默认为36M
rbd cache size =
# 脏数据最大大小,必须小于 rbd cache size 大小,默认为24M
# 使用范围(write-back,write-through)
rbd cache max dirty =
# 当脏数据达到多大时,开始将脏数据写入后端存储,必须小于 rbd cache max dirty
# 使用范围(write-back)
rbd cache target dirty =
# 脏数据在缓存中存在多长时间后开始回写到后端,默认为 1.0 秒,
# 使用范围(write-back)
rbd cache max dirty age = 5.8.2 readahead 配置
librbd 支持预读以优化较小的顺序读取。在虚拟机中启动引导程序不能够被预先读取。如果禁用缓存或使用绕写 write-around 缓存策略,则 readahead 功能将会被自动禁用。
# 触发机制。如果连续的顺序读请求达到多少次之后触发readahead功能,默认为10次
rbd readahead trigger requests =
# 预读数据最大大小,默认为512KB
rbd readahead max bytes =
# 从RBD中读取多少字节后,关闭预读功能。如果为0,则一直保持预读功能开启,默认为50M
rbd readahead disable after bytes = 5.8.3 RBD 特性配置
RBD 支持通过创建 image 时命令行指定和配置文件的方式进行高级特性配置。
配置文件中的格式为:rbd_default_features = 特性数字之和
命令行配置格式为:rbd_default_features = 以逗号分隔的特性列表
# 说明:字符串为特性名称、数字为特性码、yes为默认开启、no为默认关闭
# 使用命令行修改 rbd 特性
rbd feature disable {pool-name}/{rbd-name} object-map fast-diff deep-flatten| 特性名称 | 特性值 | 默认值 | Kernel RBD | 解释 | 命令行格式 |
|---|---|---|---|---|---|
| Layering | 1 | yes | since V3.10 | 是否支持分层,具有分层特性的 image 才可以使用克隆 | layering |
| Striping v2 | 2 | yes | since v3.10 | 将数据条带化,能够提高并行的顺序读写性能 | striping |
| Exclusive locking | 4 | yes | since v4.9 | 详见rbd排它锁 | exclusive-lock |
| Object map | 8 | yes | since v5.3 | Object map的功能依赖于排它锁的支持,object map跟踪实际给 image 分配的存储块以及位置。能够加快对 image 的操作,例如调整大小、导入、导出、展开、克隆、删除等,客户端不需要计算每个对象的位置,客户端会根据 object map 来查找 | object-map |
| Fast-diff | 16 | yes | since v5.3 | 依赖 Exclusice locking 和 Object map 功能。此功能可以使快照快速生成差异,在使用快照时能够提高速度 | Fast-diff |
| Deep-flatten | 32 | yes | since v5.1 | 深度展开特性可使得rbd的展开在任何快照上进行,如果没有开启此功能 image 的快照将依赖于其父级,所以其父级在有快照的情况下不能被删除。deep-flatten可使得快照的父级独立于其克隆或者快照 | Deep-flatten |
| Journaling | 64 | no | no | 依赖 Exclusice locking 功能。将按照顺序记录image 的每一个修改操作。在 rbd mirroring 的场景中,必须开启此功能,保证奔溃状态下能够保持两个集群的数据保持一致 | journaling |
| Data pool | 128 | no | since v4.11 | 在擦除编码池中,image 数据存储和元数据存储需要在不同的池中 | / |
| Operations | 256 | / | since v4.16 | 用于限制较旧的客户端对映像执行某些维护操作(例如,克隆,快照创建) | / |
| Migrating | 512 | / | no | 用于限制旧客户端在处于迁移状态时打开图像 | / |
5.8.4 QOS 设置
| 名称 | 解释 |
|---|---|
| rbd qos iops limit | 限制每秒的I/O操作数 |
| rbd qos bps limit | 限制I/O每秒传输的字节数 |
| rbd qos read iops limit | 限制每秒读取次数 |
| rbd qos write iops limit | 限制每秒写取次数 |
| rbd qos read bps limit | 每秒读取字节数的限制 |
| rbd qos write bps limit | 每秒写入字节数的限制 |
| rbd qos iops burst | 突发I/O操作次数限制 |
| rbd qos bps burst | 突发I/O操作字节数限制 |
| rbd qos read iops burst | 读取操作次数突发限制 |
| rbd qos write iops burst | 写入操作次数突发限制 |
| rbd qos read bps burst | 读取操作字节数突发限制 |
| rbd qos write bps burst | 写入操作字节数突发限制 |
| rbd qos schedule tick min | 单位为毫秒,默认为50。QoS时间的最小时间单位 |
5.9 RBD 集成方式
RBD与第三方集成方式有 Kernel Modules、QEMU、libvirt、Kubernetes、OpenStack、CloudStack、LIO iSCSI Gateway。
5.9.1 内核模块
客户端映射 RBD map及使用过程:
# 1.安装 ceph-common
yum install ceph-common
# 2.将认证密钥拷贝到客户端,可使用 --keyring 选项指定 keyring 文件
# 3.使用 rbd 命令加载RBD内核模块,并映射 rbd
lsmod | grep rbd
rbd --cluster {cluster-name} --id {client-name} device map {pool-name}/{rbd-name}
# 4.客户端查看映射的块设备。Luminous 版本使用 rbd showmapped 命令查看。
rbd device --cluster {cluster-name} --id {client-name} list
# 5.取消 rbd 设备映射
rbd device --cluster {cluster-name} --id {client-name} unmap /dev/rbd/rbd/foo
# 7.格式化文件系统
mkfs.xfs /dev/rbd0
# 6.客户端挂载 rbd
mount /dev/rbd0 /root/testrbd块设备自动挂载:
/usr/bin/rbdmap是一个shell脚本,可以开机自动映射挂载块设备,关机自动卸载取消映射的操作。此脚本可以有rbdmap.service服务脚本进行触发。rbdmap的配置文件为 /etc/ceph/rbdmap,此配置文件的路径也可以由环境变量 RBDMAPFILE 配置。
# 配置文件格式
IMAGESPEC RBDOPTS
# IMAGESPEC:格式是PoolName/ImageName,如果只有ImageName则PoolName默认是rbd
# RBDOPTS:传入rbd map命令的参数
# 示例 /etc/ceph/rbdmap
Block/foo01 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring
# 示例 /etc/fstab
/dev/rbd/Block/foo01 /Docker-Data xfs noauto 0 0
# 注:注:最好加上 noauto (或者 nofail )挂载选项。这样可防止 init 系统过早地挂载设备——甚至早于相应设备存在时,导致系统无法启动或设备无法挂载5.9.2 ISCSI 网关
介绍及装备工作
iSCSI 协议允许客户端(initators)通过 tcp/ip 网络将 SCSI 命令发送给 SCSI 存储设备 (targets),此种方式允许异构客户端(例如Microsoft Windows)访问Ceph存储群集。每一个 iSCSI 网关都运行 Linux LIO target 来提供 iSCSI 协议支持。LIO 通过用户空间与 ceph librbd 交互,并将 RBD image 暴露给你客户端。通过 iSCSI 网关,可以在常规网络架构中使用块存储。
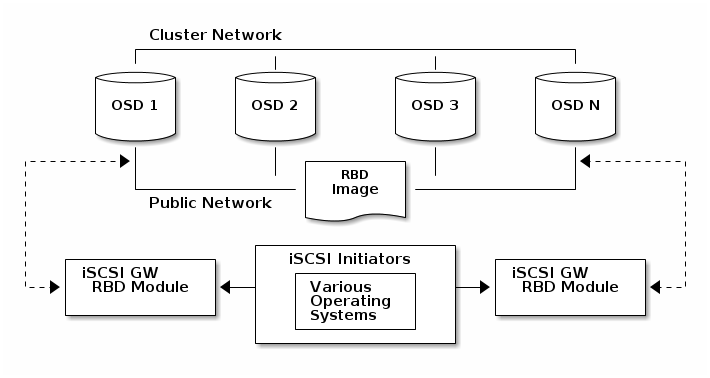
注意:1、推荐使用2-4个 iSCSI 网关节点来高可用网关;2、iSCSI 网关节点会随着 RBD image 的容量增大,内存使用量也会增大。3、在 ceph 集群中没有 iSCSI 专用的配置选项,但是降低检测 osd 的默认计时器来尽量避免 iSCSI 网关发起者的超时。4、iSCSI 网关可以是单独的节点,也可以和 osd 在同一个节点。建议配置如下:
# 配置文件配置 [osd] osd heartbeat grace = 20 osd heartbeat interval = 5 # 在线更新配置 ceph tell osd.* config set osd_heartbeat_grace 20 ceph tell osd.* config set osd_heartbeat_interval 5 # 创建 rbd pool ceph osd pool create rbd 64 64 # 标记应用程序 ceph osd pool application enable rbd rbd # 创建 image rbd --cluster test-ceph create --size 102400 --image-feature layering --image-feature striping rbd/iscsirbd
配置 iSCSI Target
注意:
1、Ceph 集群的版本最低版本为
Luminous2、依赖的安装包及必要工具
targetcli-2.1.fb47or newer packagepython-rtslib-2.1.fb68or newer packagetcmu-runner-1.4.0or newer packageceph-iscsi-3.2or newer package (需要手动添加yum源,在ceph ceph-iscsi仓库中,)3、ceph-iscsi的安装需要很多依赖包,可进行手动安装
安装 ceph-iscsi:
rpm -ivh --nodeps ceph-iscsi-3.3-1.el7.noarch.rpm安装 tcmu-runner:
# 克隆源代码
git clone https://github.com/open-iscsi/tcmu-runner
# 自动安装依赖
cd ./tcmu-runner/extra/install_dep.sh
# 编译
cmake -Dwith-glfs=false -Dwith-qcow=false -DSUPPORT_SYSTEMD=ON -DCMAKE_INSTALL_PREFIX=/usr
# 安装
make install
# 启动
systemctl enable tcmu-runner
systemctl start tcmu-runner编辑 /etc/ceph/iscsi-gateway.cfg文件:
[config]
# Name of the Ceph storage cluster. A suitable Ceph configuration file allowing
# access to the Ceph storage cluster from the gateway node is required, if not
# colocated on an OSD node.
cluster_name = test-ceph
# Place a copy of the ceph cluster's admin keyring in the gateway's /etc/ceph
# drectory and reference the filename here
gateway_keyring = test-ceph.client.admin.keyring
# API settings.
# The API supports a number of options that allow you to tailor it to your
# local environment. If you want to run the API under https, you will need to
# create cert/key files that are compatible for each iSCSI gateway node, that is
# not locked to a specific node. SSL cert and key files *must* be called
# 'iscsi-gateway.crt' and 'iscsi-gateway.key' and placed in the '/etc/ceph/' directory
# on *each* gateway node. With the SSL files in place, you can use 'api_secure = true'
# to switch to https mode.
# To support the API, the bear minimum settings are:
api_secure = false
# Additional API configuration options are as follows, defaults shown.
# api_user = admin
# api_password = admin
# api_port = 5001
trusted_ip_list = 10.53.220.240,10.53.220.241启动 rbd-target-api 服务:
systemctl enable rbd-target-api
systemctl start rbd-target-apitarget 配置:(可使用 skipchecks=true 选项绕过版本及内核检测)
# 创建一个 target
gwcli
> /> cd /iscsi-target
> /iscsi-target> create iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw
# 创建网关
> /iscsi-target> cd iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw/gateways
> /iscsi-target...-igw/gateways> create {hostname1-FQDN} {host_ip_1}
> /iscsi-target...-igw/gateways> create {hostname2-FQDN} {host_ip_2}创建一个设备:
> /iscsi-target...-igw/gateways> cd /disks
> /disks> create pool=rbd image=disk_1 size=90G创建一个客户端:
> /disks> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw/hosts
> /iscsi-target...eph-igw/hosts> create iqn.1994-05.com.redhat:rh7-client配置 CHAP 认证用户名和密码:
auth username=iqn.1994-05.com.redhat:rh7-client password=admin@a_12a-bb增加设备到客户端:
disk add rbd/iscsirbd配置Initiators
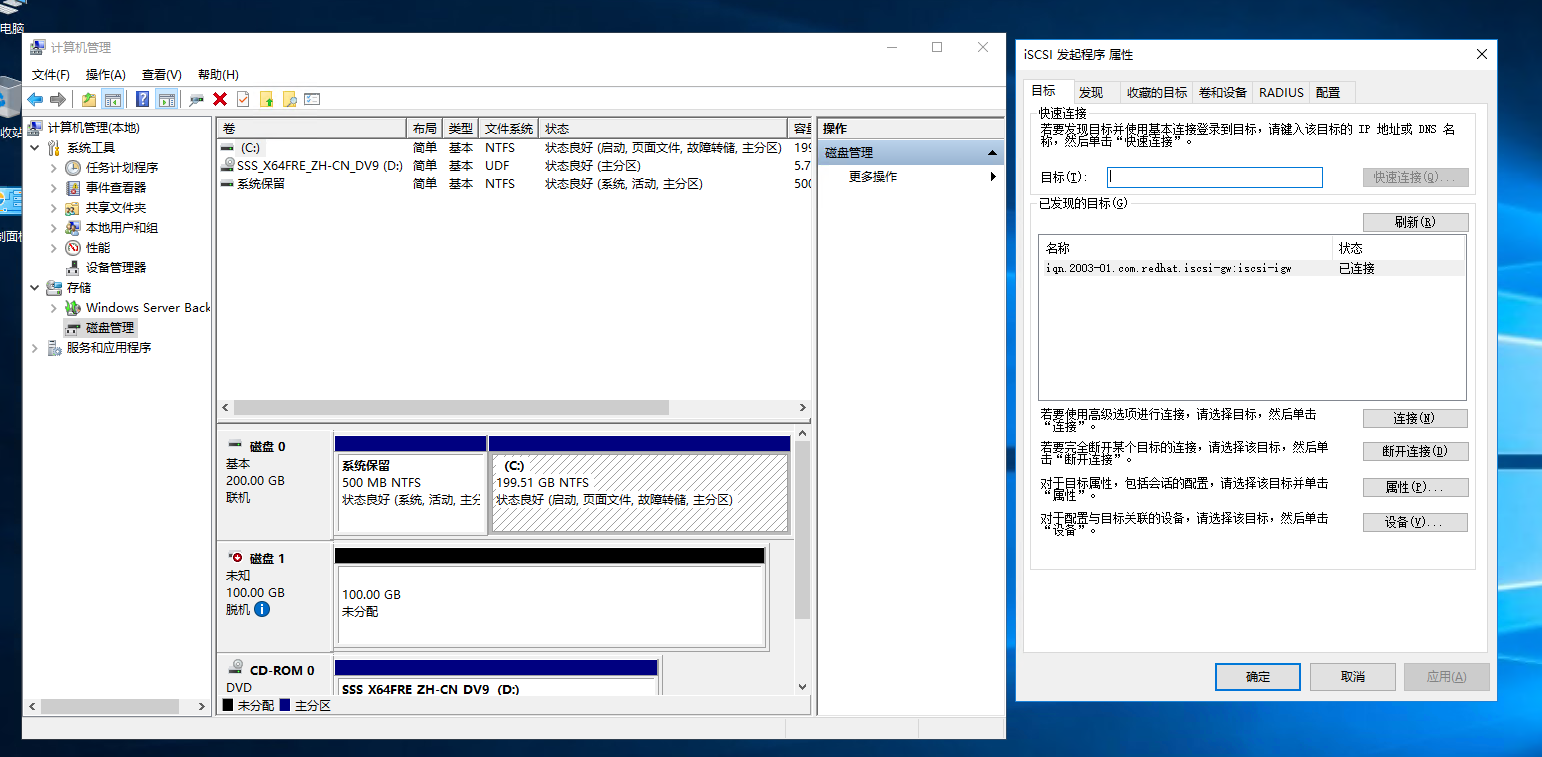
使用windows iscsi 发起程序进行配置,发现目标:
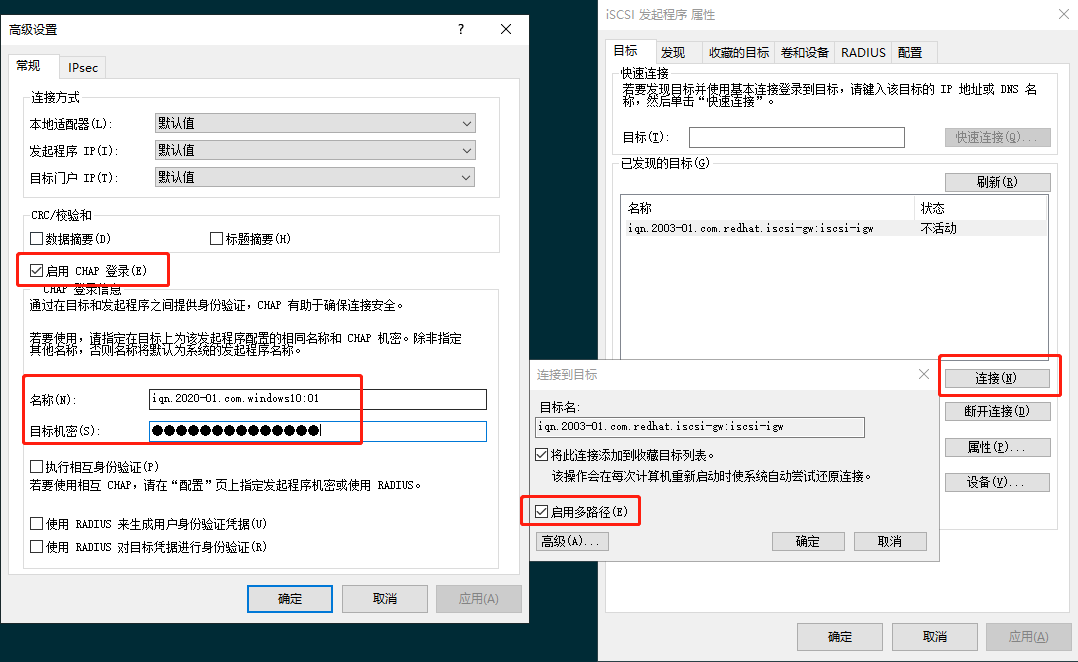
连接配置目标:
5.9.3 QEMU 集成
ceph 最常用的场景就是利用块的形式给虚拟机提供存储。
5.9.4 libvirt 集成
5.9.5 Kubernetes 集成
5.9.6 OpenStack 及 CloudStack 集成
6. Ceph 文件系统
6.1 CephFS 简介
Ceph 文件系统或 CephFS 是一个兼容 ROSIX 标准构建在 RADOS 之上的分布式对象存储接口,CephFS 致力于为各类应用程序提供一个最优、多用途、高可用的文件存储方式,包括传统的共享文件、高性能计算暂以及分布式工作共享文件等。CephFS 的数据存储和元数据存储分别在 RADOS 之上不同的 Pool 中,因为没有中心服务器的限制,理论上 CephFS 的性能随着 ceph 集群的扩展是线性增长的。CephFS
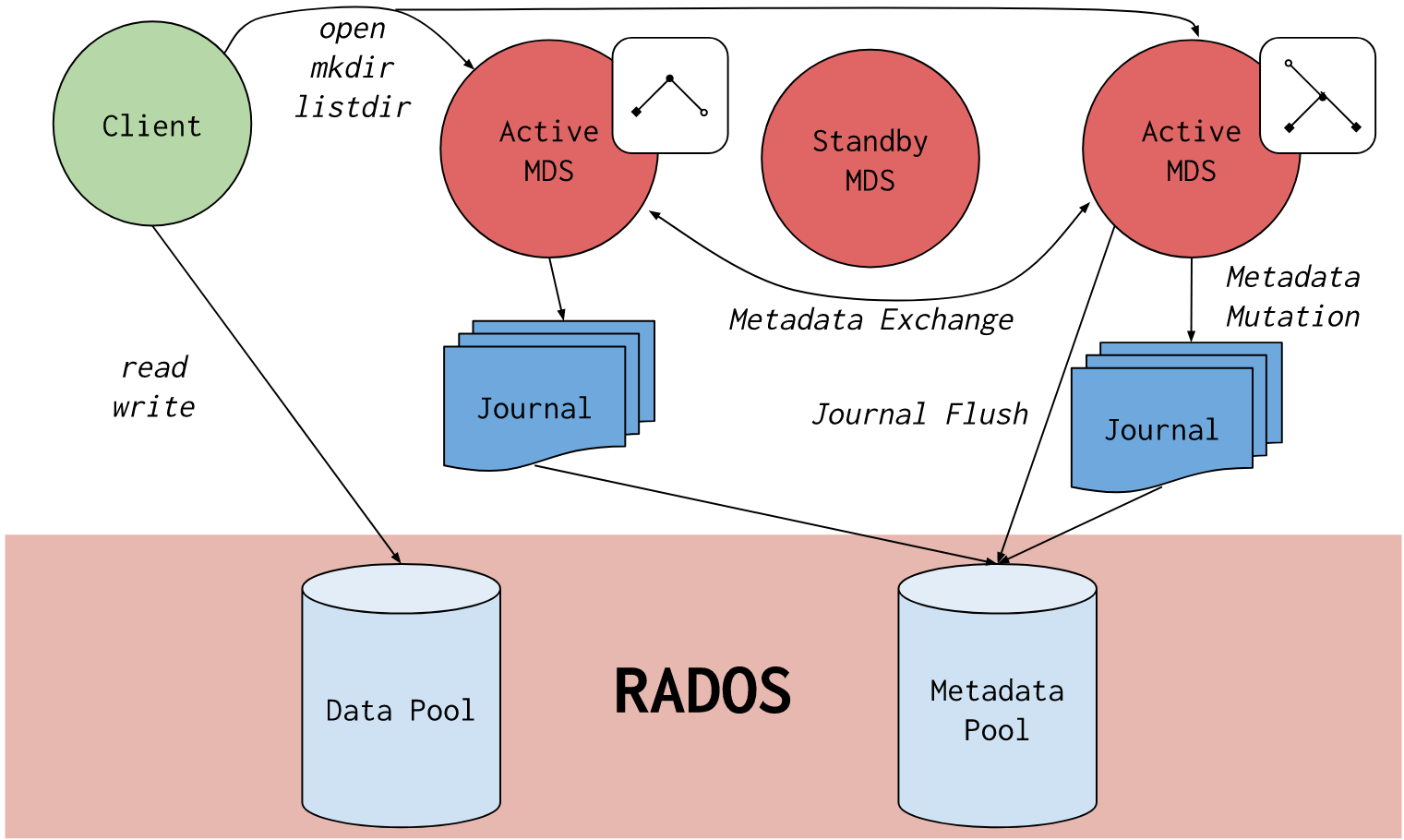
6.2 注意事项
- 使用 Ceph 的最小版本为 Jewel V10.2.0 ,这个版本是首次包含稳定 CephFS 组件及 fsck/repair 工具的版本。
- 尽量避免多个 MDS 处于工作状态,多个 MDS 可用作冗余进程。
- 通过 FUSH 使用 CephFS 是最易于使用的方式,但 Kernel Client 是性能最好的一种方式。不同客户端功能上可能不尽相同,例如 fuse 客户端支持配额,而 kernel Client 则不支持。
- Linux 4.X 版本的内核支持,旧版的内核版本可能会有未知的错误。
- 对于元数据 pool 可以采用更多的副本数量,任何元数据的丢失将导致文件系统无法访问。
- 给元数据 pool 可以使用 SSD 作为存储,因为元数据的访问速度直接影响用户的用户体验。
- 通常元数据 pool 中的数据有数 GB 的数据,在大型集群中元数据 pool pg 数量为 64 或 128。
- CephFS 文件系统有一个除了易于识别的名称之外,还有一个ID(整数),这个 ID 称为
file system cluster ID或FSCID。- 每一个文件系统都有一个表示级别的数字,默认情况下,rank 值为 0,从 0 开始计数。在新版本中允许部署多个 mds 处于活跃状态,元数据的负载能力随 mds 服务器数量的增长线性增长。可以使用命令激活多个元数据服务器:
ceph fs set {cephfs_name} max_mds {num}。通过递增 rank 数量来增加活跃 mds 的数量。
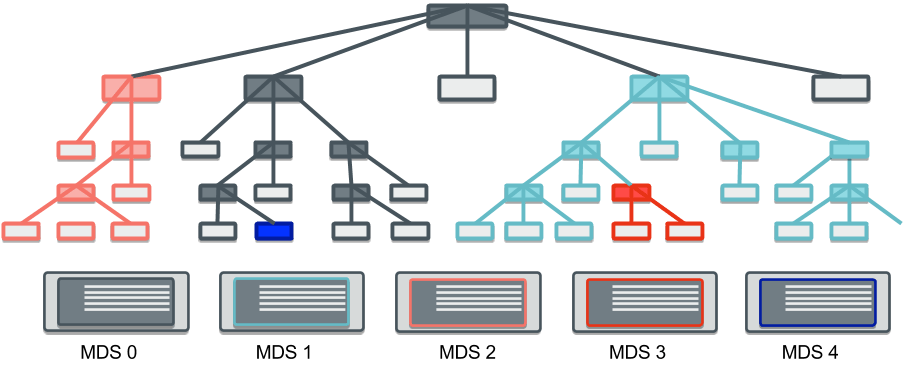
CephFS的一个独特功能是它能够将文件系统树分割成子树,每个子树都可以分配给特定的 MDS 进行权威管理。这允许文件系统上的元数据负载能力随元数据服务器的数量线性扩展。每个子树都是根据给定目录树中元数据的热度动态创建的。创建子树后,其元数据将迁移到负载不足的MDS。后续客户对先前授权MDS的请求将被转发。
可通过ceph daemon mds.{ID} get subtrees命令查看子树的情况。默认情况下,/子树由 rank 0 来管理,~开头的子树的内部子树,不属于文件系统层次结构。
6.3 CephFS 创建
创建 pool :
ceph osd pool create cephfs_data
ceph osd pool create cephfs_metadata启用 CephFS:
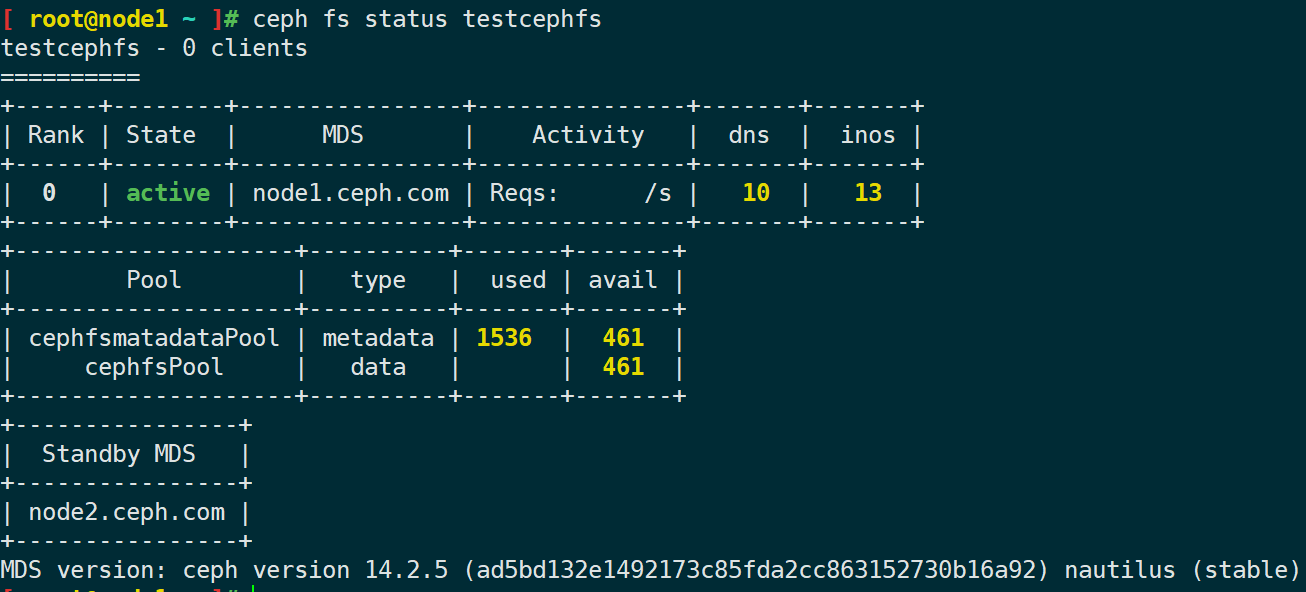
ceph fs new {fs_name} {metadata_pool_name} {data_pool_name}查看 cephfs 状态:
ceph mds stat
ceph fs status {cephfs_name}启用cephfS之后的状态信息如下:
如果创建多个 cephfs ,客户端在挂载文件系统时未指定名称,则可以使用 ceph fs set-default {cephfs_name} 指定客户端默认挂载的文件系统。
(可选)可以在数据池上开启纠删码功能,使用 ceph osd pool set {data_pool} allow_ecoverwrites true 命令启用。此功能只支持后端存储为 bluestore 的存储引擎。元数据池之上无法开启纠删码功能,因为元数据是使用 RADOS OMAP 数据结构存储,纠删码池不能够存储。
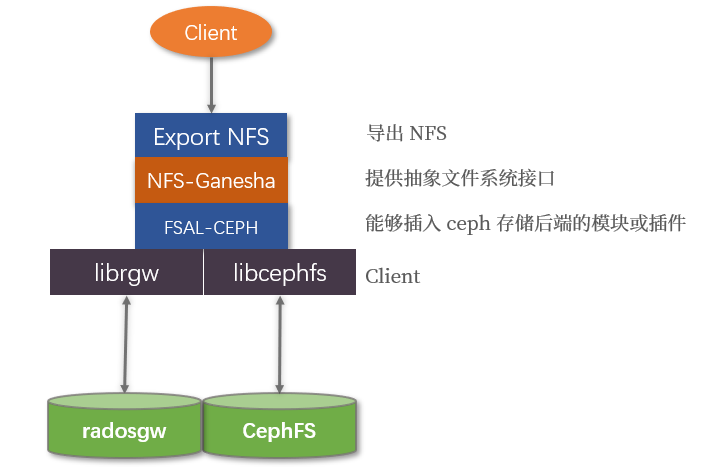
6.4 NFS 导出(待完善)
cephFS 或 rgw 能够通过使用 NFS-Ganesha NFS server 导出 NFS 协议的文件系统。NFS-Ganesha 提供了一个抽象的文件系统接口能够插入不同的存储后端,FSAL-CEPH 是能够插入 ceph 存储后端的插件。对于每一个 NFS-ganesha 导出端点,FSAL-CEPH 使用 libcephfs 作为客户端。
要求
- Ceph file system 版本为
luminous或更高版本。- 在 NFS server 主机上,安装最新版本的
libcephfs2,nfs-genesha,nfs-ganesha-ceph。- nfs-server 能够访问公共网络。
6.5 CephFS 管理
6.5.1 CephFS 配置
默认情况下,ceph 集群只允许创建有一个文件系统,如果需要创建多个文件系统,需要使用 ceph fs flag set enable_multuple true 命令进行配置。注:此功能尚在测试阶段,官方并不建议在生产环境中使用此功能。
状态信息/删除/配置:
# 列出所有文件系统的详细信息
ceph fs dump
# 获取cephfs文件系统的信息
ceph fs get {cephfs_name}
# 删除一个文件系统,(并不会删除数据和元数据池,只会擦除文件系统的 FSMap 信息,池需要单独删除),删除一个文件系统之前需要将文件系统标记为 inactive 状态
ceph fs fail {cephfs_name}
ceph fs rm {cephfs_name} --yes-i-really-mean-it
# 改变一个文件系统的特性
ceph fs set {cephfs_name} {var} {val}给文件系统添加数据池:
# 添加一个数据池,该数据池可利用文件布局 file layouts 将该池作为一个备用存储 Pool
ceph fs add_data_pool {cephfs_name} {pool_name}
# 从文件系统中删除数据池,如果有数据被映射到了要删除的 Pool 中,则该 Pool 被删除后,数据也将被删除,创建文件系统时的默认数据池无法被删除
ceph fs rm_data_pool {cephfs_name} {pool_name} 最大文件设置:
设置最大文件限制,可避免用户创建超大空文件,当在查询或删除操作时,对 MDS 造成无谓的负载。
# 设置文件系统中存储的文件最大值,单位为字节,默认为大小为 1TB,设置为 0 ,则表示无限制
ceph fs set max_file_size {file_size}关闭/启用文件系统:
关闭cephfs将刷新所有日志到元数据池,然后停止所有客户端I/O。
# 关闭
fs set <fs_name> down true
# 启用
fs set <fs_name> down false快速停止文件系统,避免备用 mds 激活文件系统:
# 这种方式可避免备用 mds 激活文件系统
ceph fs fail {cephfs_name}
# 也可以手动避免备用 mds 加入
ceph fs set {cephfs_name} joinable false
# 恢复 cephfs
ceph fs set {cephfs_name} joinable truemds守护进程操作:
# 对于mds的操作指定可使用 fs_name、fs_id、rank三种方式
# 标记mds守护进程失败等同于mon节点在 mds_beacon_grace 指定的时间内未收到mds存活通知。如果 mds进程仍在运行,则此命令将导致该进程重启,如果该进程有备用进程,则备用进程将被激活,该进程将转为备用进程。
ceph mds fail {mds_name}
# 给mds守护进程发送命令,command 可使用 ceph tell mds.* help 查看
ceph tell mds.{daemon_name} command .... mon 的关于 mds 的信息:
ceph mds metadata {mds_name}标记文件已修复完成:
ceph mds repaired {mds_name}限制客户端最低版本:
fs set <fs name> min_compat_client <release> # 例如:nautilus高级配置:
通常情况下不需要对这些选项进行配置,不正确地使用这些命令可能会导致严重的问题,例如无法访问文件系统。
# 移除兼容性 flag
ceph mds compat rm_compat
# 移除不兼容性 flag
ceph mds compat rm_incompat
# 显示兼容性 flag
ceph mds compat show
# 将故障mds移除
ceph mds rmfailed
# 重置 cephfs
ceph fs reset {cephfs_name}6.5.2 MDS 管理
mds 当前版本仍然是单进程和受限于 CPU,在高负载情况下,mds 进程会使用到 2-3 个 CPU 核心,因为还有一些其他线程来协调 mds 的一同工作,尽管目前 mds 还不支持使用多进程来利用 CPU 的能力,但依然建议提供给 mds 服务器使用尽可能多的内存以提供更快的元数据的访问和更改。默认情况下,mds 使用的缓存大小为 4G,强烈建议提供至少 8G 大小的内存来支持 mds 的元数据缓存。通常情况下,提供 1000个或更多的客户端的服务的集群建议使用至少 64G 内存作为缓存,但并不意味更大的内存作为缓存可以提高性能,因为管理巨大的缓存可能会造成性能下降。在物理机之上运行 mds ,通常尽可能的给 mds 更多的物理性能,尽管单个 mds 进程无法充分利用硬件性能,但可在之上运行多个 mds 进程来充分利用硬件性能。
添加 mds 进程
mds 进程数据目录在 /var/lib/ceph/mds/{ceph_name}-{mds_id}目录下,此目录中仅存放 mds 的 keyring 文件。
参见 3.7 章节
移除 mds 进程
# 停止mds进程
systemctl stop ceph-mds@{mds_id}
# 删除 mds 数据目录,及ceph auth认证密钥注意事项
管理 mds 进程可以使用rank、GID、名称 ID 三种方式,守护进程是备用守护进程时,并没有分配 rank 值的情况下,只能使用 GID 或名称来引用。mds 故障转移的时候,以下命令全部使用:
ceph mds fail 5446 # GID ceph mds fail myhost # Daemon name ceph mds fail 0 # Unqualified rank ceph mds fail 3:0 # FSCID and rank ceph mds fail myfs:0 # File System name and rank如果一个 mds 守护进程和 monitor 节点停止通信,则 monitor 会在
mds_beacon_grace指定的秒数之后将故障 mds 进程标记为失败,如果有备用进程可用,则 monitor 会立即启用备用进程。# 默认值为1 ceph fs set <fs name> standby_count_wanted <count>配置此备用进程数量,包括
standby-replay守护进程。因此建议max_mds配置数量包括活跃的 mds 守护进程,备用守护进程,standby-replay守护进程。在 CephFS 中可以配置
standby-replay守护进程,standby-replay 守护进程跟踪活动的 mds 守护进程的日志,如果 mds 发生故障,则可以非常快速的进行故障转移。每个活动的 mds 仅能配置一个 standby-replay 守护进程。使用以下命令启用:ceph fs set {cephfs_name} allow_standby_replay <bool> # 例如:yes|1一旦配置,则 Monitor 将会分配可用的备用进程来跟踪活动的 mds 进程,如果此时 mds 守护进程故障,则 standby-replay 进程不会转为活跃的 mds 守护进程,即便此时没有备用 mds 守护进程。
6.5.3 MDS 缓存限制
MDS 集群会在内存中维持一组 cephfs 的元数据。MDS 的元数据缓存大小可通过配置参数 mds_cache_memory_limit 进行配置。此外还可以通过 mds_cache_reservation 参数指定缓存保留,限制内存或inode的保留百分比限制,默认为 5%,此参数的目的是使得 MDS 为缓存保留额外的内存,以供新的元数据操作使用。需要注意的是,缓存限制不是一个硬性限制,某些情况下,元数据的缓存可能超过限制,mds_health_cache_threshold 参数可以限制超过多大时给集群发送健康状态消息,此参数默认值是 1.5(150%)。
7. Ceph 对象存储
7.1 Object Gateway 部署
Ceph对象网关(也称为RADOS网关)是在librados API之上构建的对象存储接口,旨在为应用程序提供Ceph存储集群的RESTful网关。从 firefly v0.80 版本起,Ceph Object Gateway 运行在嵌入到 ceph-radosgw 守护进程之上的 Civetweb,取代了之前的 Apache 或者 FastCGI 方式,使用 Civetweb 简化了Ceph对象网关的安装和配置。在 v0.80 版本中,Ceph Object Gateway 不支持 SSL,但可以设置代理的方式来启用 SSL 功能。默认情况下,Civetweb 默认监听在 7480 端口。从11.0.1 版本开始支持 SSL 功能。
安装 ceph-radosgw
yum install ceph-radosgw修改配置文件
# {short_hostname} 为 hostname -s 显示的主机名,且 rgw-frontends 中间的参数 = 左右不能有空格
[client.rgw.{short_hostname}]
host = {short_hostname}
rgw frontends = "civetweb port=80"
# rgw dns name = <obj_gw_hostname>.example.com
# 如果需要启动多个 rgw 网关实例,添加配置文件
[client.rgw.node1]
host = node1
rgw frontends = "civetweb port=80"
[client.rgw.node2]
host = node2
rgw frontends = "civetweb port=80"创建rgw数据目录
mkdir -p /var/lib/ceph/radosgw/{cluster_name}-rgw.{short_hostname}添加用户及密钥环文件
ceph auth get-or-create client.rgw.{short_hostname} osd 'allow rwx' mon 'allow rw' -o /var/lib/ceph/radosgw/{cluster_name}-rgw.{short_hostname}/keyring注:为网关密钥提供功能时,必须提供读取功能。但是,提供 Monitor 写入功能是可选的。如果提供的话,Ceph 对象网关将能够自动创建池。在这种情况下,请确保在池中指定合理数量的 pg 数量。否则,网关将使用默认数字,该数字可能不适合创建需求。
修改数据文件权限
touch /var/lib/ceph/radosgw/<cluster_name>-rgw.{short_hostname}/done
chown -R ceph:ceph /var/lib/ceph/radosgw
chown -R ceph:ceph /var/log/ceph
chown -R ceph:ceph /var/run/ceph
chown -R ceph:ceph /etc/ceph注:如果自定义了集群名称,则需要在
/etc/sysconfig/ceph中指定CLUSTER={ceph_name}集群名称。
启动网关
systemctl enable ceph-radosgw.target
systemctl enable ceph-radosgw@rgw.{short_hostname}
systemctl start ceph-radosgw@rgw.{short_hostname}启动之后可使用 curl 或浏览器访问对象网关,如图。http://10.53.220.240/

7.2 RGW 基本配置
默认端口更改
Civetweb 默认运行监听 7480 端口,可以在集群配置文件 ceph.conf 中进行修改。rgw frontends = "civetweb port=80" 此配置项进行修改。
使用 SSL
使用 SSL 需要一个和对象网关主机名相匹配的 ssl 证书,如果使用 S3-style 子域,则需要一个通配域名 ssl 证书。证书文件文件提供给 Civetweb 服务器密钥、证书等相关信息,证书采用 pem 格式。
[client.rgw.{short_hostname}]
rgw_frontends = civetweb port=443s ssl_certificate=/etc/ceph/private/keyandcert.pem此外,还可以绑定多个端口,使得可以通过80和443端口同时访问对象网关。
[client.rgw.{short_hostname}]
rgw_frontends = civetweb port=80+443s ssl_certificate=/etc/ceph/private/keyandcert.pembucket 索引分片
Ceph 对象网关将 bucket 索引数据存储在 index_pool 池中,默认为 .rgw.buckets.index 池中。一些用户喜欢将大量的数据存储在单个 bucket 中。如果不给 bucket 设置存储的对象最大数量配额,则当用户上传过多的对象时,有可能造成严重的性能下降。在 ceph 0.94 版本中,当 bucket 中存在大量对象时,可将索引用 shard(分片) 的形式存储以防止性能瓶颈。rgw_override_bucket_index_max_shards 配置参数可以设置允许在每个 bucket 中的索引分片数量,默认是 0,即默认分片功能是关闭的。最简单的配置方式是在 ceph.conf 配置文件 [global] 中设置全局配置,也可以在每个 rgw 实例下进行配置。
此外还可以统一对 zonegroup 中的 zone 中的 rgw_override_bucket_index_max_shards 值进行配置。对 zonegroup 的配置文件导出然后进行修改,之后再讲配置导入。
# 导出之后对 zonegroup.json 中的 bucket_index_max_shards 值进行修改
radosgw-admin zonegroup get > zonegroup.json
# 导入配置
radosgw-admin zonegroup set < zonegroup.json
# 更新配置更改
radosgw-admin period update --commit注:可以将 bucket 的索引存储池映射到 SSD 的 OSD 之上,能够提高索引性能。
添加通配符域名
在使用 S3 风格的域名时(例如 bucket-name.domain.com),你需要添加一个通配域名解析记录到 DNS 服务器。例如添加 *.object.com 解析记录到 DNS 解析记录。
- 引用自 AWS 文档
存储桶是 Amazon S3 中用于存储对象的容器。每个对象都储存在一个存储桶中。例如,如果名为
photos/puppy.jpg的对象存储在johnsmith存储桶中,则可使用 URLhttp://johnsmith.s3.amazonaws.com/photos/puppy.jpg对该对象进行寻址。
调试模式
[global]
#append the following in the global section.
debug ms = 1
debug rgw = 20Object Gateway 使用
为了使用 REST API 接口,首先需要去创建有权限访问的用户(无论是 S3 接口还是 Swift 接口)。
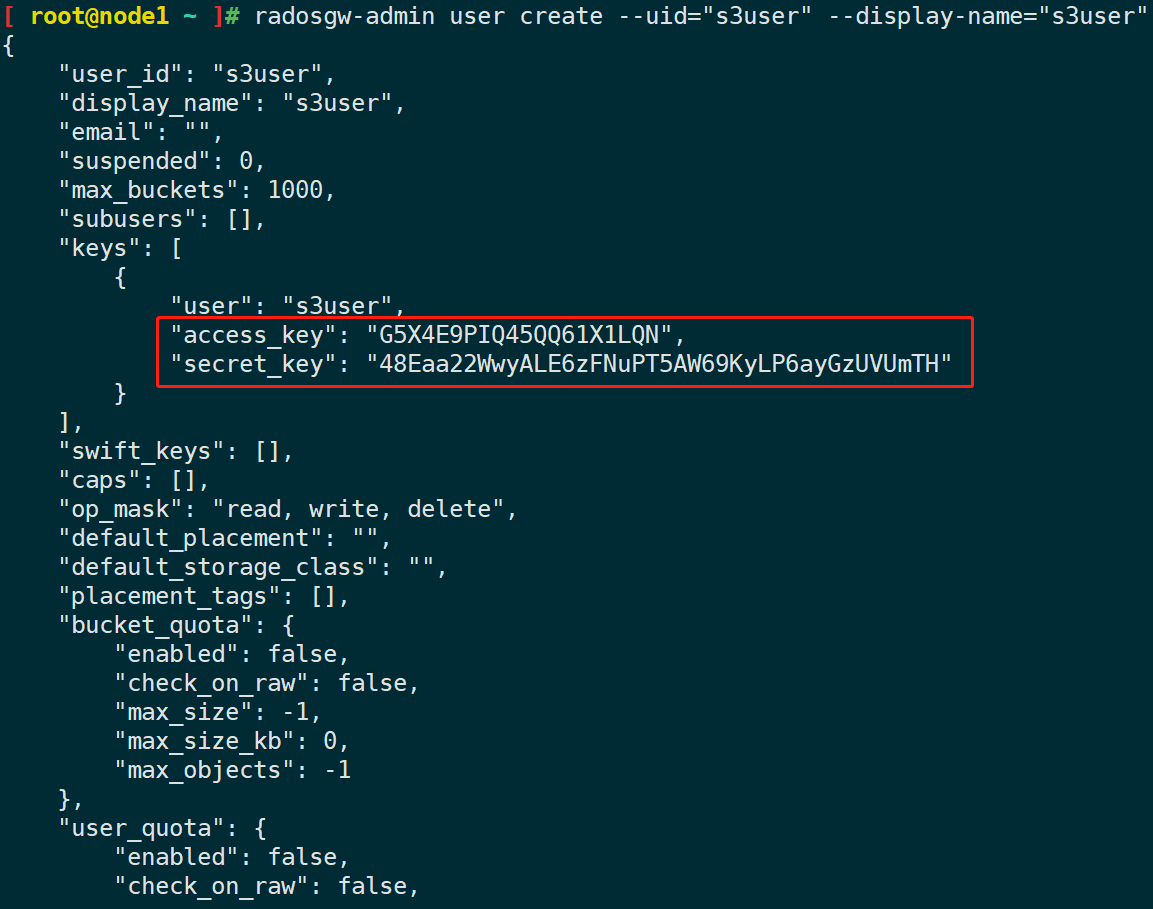
# 创建 S3 用户
radosgw-admin -c {cephcluster-conf} user create --uid="s3user" --display-name="s3user"以上命令输出内容中 keys 中的 access_key 和 secret_key 是访问验证所需要的内容。
注意:有时在 access_key 和 secret_key 中生成的密钥含有转义字符
\,解决方法是删除转义字符\,并在引号中使用删除转义符的密钥,此外,需要注意的是/字符不是转义不能删除。
# 创建 Swift 用户 swift01 为 swiftuser 的子用户
radosgw-admin user create --subuser=swiftuser:swift01 --display-name="swiftuser" --key-type=swift --access=full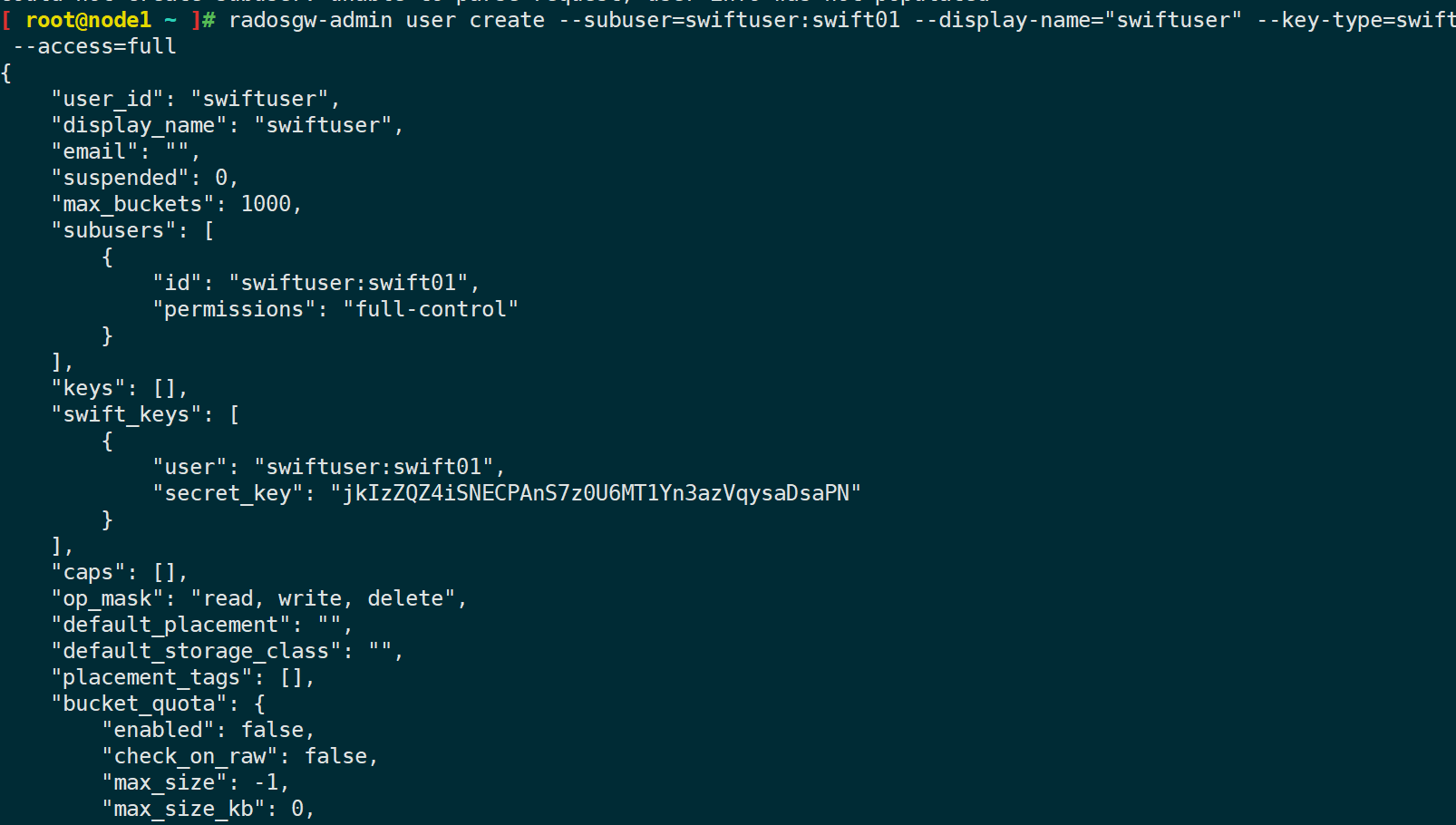
可以使用 Python 脚本来测试 S3 用户的访问,此脚本将创建一个新的 bucket,并列出所有 bucket。
# 安装 Python 库
yum install python-boto
# python 脚本
import boto.s3.connection
access_key = 'G5X4E9PIQ45QQ61X1LQN'
secret_key = '48Eaa22WwyALE6zFNuPT5AW69KyLP6ayGzUVUmTH'
conn = boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host='10.53.220.240', port=80,
is_secure=False, calling_format=boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('s3-bucket-test')
for bucket in conn.get_all_buckets():
print "{name} {created}".format(
name=bucket.name,
created=bucket.creation_date,
)输出新创建 bucket 的名称的创建时间属性:

对 swift 用户的访问可通过命令行工具进行测试。
# 安装工具
yum install python-setuptools
easy_install pip
pip install --upgrade setuptools
pip install --upgrade python-swiftclient
# 测试
swift -V 1 -A http://10.53.220.240:80/auth -U swiftuser:swift01 -K 'DncSU8flflc8UdzhhGJ0yPFVx9wPdk331EF0mko7' list7.3 HTTP 前端
Ceph 对象网关支持两种 HTTP 前端,可通过 rgw_frontends 选择配置哪一种前端,Beast 和 Civetweb。全部配置选项参数文档
配置示例
[client.rgw.gateway-node1] rgw_frontends = civetweb request_timeout_ms=30000 error_log_file=/var/log/radosgw/civetweb.error.log access_log_file=/var/log/radosgw/civetweb.access.log
7.4 存储位置及类型
Placement target 允许管理员定义默认的放置目标,并明确某些用户将数据写入哪个放置目标中。对象放置位置由 bucket 与那个 pool 关联决定,在创建 bucket 时指定了存储池后,不能修改。radosgw-admin bucket stats 可以查看对象放置规则。在 zonegroup 配置信息中包含了默认放置目标 default-placement ,使用 radosgw-admin zonegroup get 命令查看。可以分别修改 zonegroup 和 zone 配置文件来指定对象放置位置。
Storage classes 用来自定义数据的放置位置,zonegroup 配置文件列出可用的存储类,zone 配置文件为每个 zone 指定了一个 data_pool。
自定义操作
增加自定义 placement target 和 storage class:
# 导出 zonegroup.json 文件
radosgw-admin zonegroup get > zonegroup.json
# 修改 zonegroup.json 文件,添加如下内容
{
"name": "test-placement",
"tags": [
"test-placement"
],
"storage_classes": [
"TEST"
]
}
# 导入 zonegroup.json 文件
radosgw-admin zonegroup set < zonegroup.json
# 导出 zone.json 文件
radosgw-admin zone get > zone.json
# 修改 zone.json 文件,添加如下内容
"key": "test-placement",
"val": {
"index_pool": "test.rgw.buckets.index",
"storage_classes": {
"STANDARD": {},
"TEST": {
"data_pool": "test.rgw.buckets.data"
}
},
"data_extra_pool": "test.rgw.buckets.non-ec",
"index_type": 0
}
# 导入文件
radosgw-admin zone set < zone.json定义 placement
bucket 默认存储位置设置。默认情况下,新存储桶将使用 zonegroup 的 default_placement 目标。可以通过以下方式更改此区域组设置:
radosgw-admin zonegroup placement default --rgw-zonegroup default --placement-id {new-placement}user placement 设置:
# 导出
radosgw-admin metadata get user:s3user01 > s3user01.json
# 修改
"default_placement": "test-placement",
"default_storage_class": "TEST",
"placement_tags": ["test-placement"],
# 导入
radosgw-admin metadata put user:s3user01 < s3user01.jsonS3 bucket placement and Swift bucket placement:
# S3
<LocationConstraint>default:new-placement</LocationConstraint>
# Swift HTTP头部信息
X-Storage-Policy: new-placement同样在创建一个 bucket 的时候也可以指定 storage classes。